defnaiveSoftmaxLossAndGradient( centerWordVec, outsideWordIdx, outsideVectors, dataset ): """ Naive Softmax loss & gradient function for word2vec models
Implement the naive softmax loss and gradients between a center word's embedding and an outside word's embedding. This will be the building block for our word2vec models. For those unfamiliar with numpy notation, note that a numpy ndarray with a shape of (x, ) is a one-dimensional array, which you can effectively treat as a vector with length x.
Arguments: centerWordVec -- numpy ndarray, center word's embedding in shape (word vector length, ) (v_c in the pdf handout) outsideWordIdx -- integer, the index of the outside word (o of u_o in the pdf handout) outsideVectors -- outside vectors is in shape (num words in vocab, word vector length) for all words in vocab (tranpose of U in the pdf handout) dataset -- needed for negative sampling, unused here.
Return: loss -- naive softmax loss gradCenterVec -- the gradient with respect to the center word vector in shape (word vector length, ) (dJ / dv_c in the pdf handout) gradOutsideVecs -- the gradient with respect to all the outside word vectors in shape (num words in vocab, word vector length) (dJ / dU) """
### YOUR CODE HERE (~6-8 Lines) U,u_o,v_c,o = outsideVectors,outsideVectors[outsideWordIdx],centerWordVec,outsideWordIdx #整体的softmax y_hat = softmax(np.dot(U,v_c)) y = np.zeros(np.shape(y_hat)) y[o]=1 #单独的o的损失 loss = -np.log(y_hat[o]) gradCenterVec=np.dot(U.T,(y_hat-y)) gradOutsideVecs = np.dot((y_hat-y)[:,np.newaxis],v_c[:,np.newaxis].T) # print(np.shape(gradCenterVec),np.shape(gradOutsideVecs)) ### Please use the provided softmax function (imported earlier in this file) ### This numerically stable implementation helps you avoid issues pertaining ### to integer overflow.
defnegSamplingLossAndGradient( centerWordVec, outsideWordIdx, outsideVectors, dataset, K=10 ): """ Negative sampling loss function for word2vec models
Implement the negative sampling loss and gradients for a centerWordVec and a outsideWordIdx word vector as a building block for word2vec models. K is the number of negative samples to take.
Note: The same word may be negatively sampled multiple times. For example if an outside word is sampled twice, you shall have to double count the gradient with respect to this word. Thrice if it was sampled three times, and so forth.
Arguments/Return Specifications: same as naiveSoftmaxLossAndGradient """
# Negative sampling of words is done for you. Do not modify this if you # wish to match the autograder and receive points! negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K) indices = [outsideWordIdx] + negSampleWordIndices ''' Arguments: centerWordVec -- numpy ndarray, center word's embedding in shape (word vector length, ) (v_c in the pdf handout) outsideWordIdx -- integer, the index of the outside word (o of u_o in the pdf handout) outsideVectors -- outside vectors is in shape (num words in vocab, word vector length) for all words in vocab (tranpose of U in the pdf handout) dataset -- needed for negative sampling, unused here. ''' ### YOUR CODE HERE (~10 Lines) ### Please use your implementation of sigmoid in here. U,u_o,v_c,o,s= outsideVectors,outsideVectors[outsideWordIdx],centerWordVec,outsideWordIdx,negSampleWordIndices gradCenterVec = np.zeros(v_c.shape) gradOutsideVecs = np.zeros(U.shape) u_negsam = U[s] center_o = np.dot(u_o, v_c) center_s = -np.dot(u_negsam,v_c) # U_sampled = np.concatenate((u_o[np.newaxis,:],-u_negsam),axis=0) loss = -np.log(sigmoid(center_o))-np.sum(np.log(sigmoid(center_s))) gradCenterVec += np.dot(u_o,sigmoid(center_o)-1) gradOutsideVecs[o] = np.dot(sigmoid(center_o)-1,v_c) for i in s: u_k = U[i] gradCenterVec += np.dot(u_k, 1-sigmoid(-np.dot(u_k,v_c))) gradOutsideVecs[i] += np.dot(1-sigmoid(-np.dot(u_k,v_c)),v_c) ### END YOUR CODE
defskipgram(currentCenterWord, windowSize, outsideWords, word2Ind, centerWordVectors, outsideVectors, dataset, word2vecLossAndGradient=naiveSoftmaxLossAndGradient): """ Skip-gram model in word2vec
Implement the skip-gram model in this function.
Arguments: currentCenterWord -- a string of the current center word windowSize -- integer, context window size outsideWords -- list of no more than 2*windowSize strings, the outside words word2Ind -- a dictionary that maps words to their indices in the word vector list centerWordVectors -- center word vectors (as rows) is in shape (num words in vocab, word vector length) for all words in vocab (V in pdf handout) outsideVectors -- outside vectors is in shape (num words in vocab, word vector length) for all words in vocab (transpose of U in the pdf handout) word2vecLossAndGradient -- the loss and gradient function for a prediction vector given the outsideWordIdx word vectors, could be one of the two loss functions you implemented above.
Return: loss -- the loss function value for the skip-gram model (J in the pdf handout) gradCenterVecs -- the gradient with respect to the center word vector in shape (num words in vocab, word vector length) (dJ / dv_c in the pdf handout) gradOutsideVecs -- the gradient with respect to all the outside word vectors in shape (num words in vocab, word vector length) (dJ / dU) """
loss = 0.0 gradCenterVecs = np.zeros(centerWordVectors.shape) gradOutsideVectors = np.zeros(outsideVectors.shape)
### YOUR CODE HERE (~8 Lines) #获取center word的vector #当前中心词的idx到vec c_i = word2Ind[currentCenterWord] v_c = centerWordVectors[c_i] for word in outsideWords: #对每个outside word都求一次loss和gradient o_i=word2Ind[word] ls,gc,go = word2vecLossAndGradient(v_c,o_i,outsideVectors,dataset) loss += ls #梯度方法返回的是一个中心词的梯度,这里需要对应到idx gradCenterVecs[c_i] += gc #梯度方法返回的已经是整体的梯度,因此不用再用o_idx gradOutsideVectors += go ### END YOUR CODE
Implement the stochastic gradient descent method in this function.
Arguments: f -- the function to optimize, it should take a single argument and yield two outputs, a loss and the gradient with respect to the arguments x0 -- the initial point to start SGD from step -- the step size for SGD iterations -- total iterations to run SGD for postprocessing -- postprocessing function for the parameters if necessary. In the case of word2vec we will need to normalize the word vectors to have unit length. PRINT_EVERY -- specifies how many iterations to output loss
Return: x -- the parameter value after SGD finishes """
# Anneal learning rate every several iterations ANNEAL_EVERY = 20000
if useSaved: start_iter, oldx, state = load_saved_params() if start_iter > 0: x0 = oldx step *= 0.5 ** (start_iter / ANNEAL_EVERY)
if state: random.setstate(state) else: start_iter = 0
x = x0
ifnot postprocessing: postprocessing = lambda x: x
exploss = None
foriterinrange(start_iter + 1, iterations + 1): # You might want to print the progress every few iterations.
loss = None ### YOUR CODE HERE (~2 lines) #f函数计算loss和grad loss,grad = f(x) #更新x,sgd的主要思想就是在负梯度方向下降某个步长,这里题目已经给出。 x = x - step*grad ### END YOUR CODE
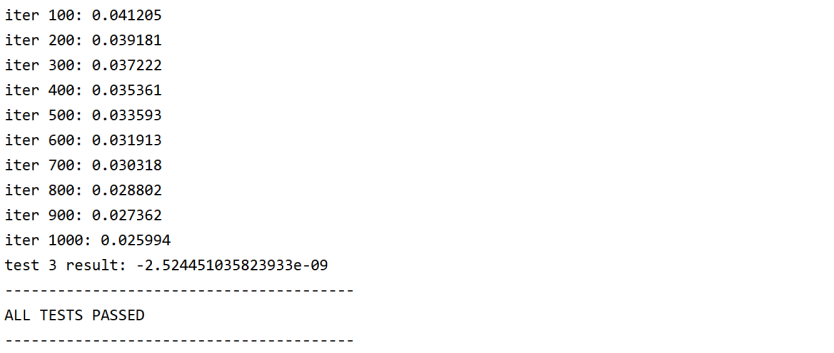
x = postprocessing(x) ifiter % PRINT_EVERY == 0: ifnot exploss: exploss = loss else: exploss = .95 * exploss + .05 * loss print("iter %d: %f" % (iter, exploss))
iter 10: 19.824024 iter 20: 20.136629 iter 30: 20.151500 iter 40: 20.211374 ... iter 11400: 12.003779 iter 11410: 12.043692 iter 11420: 12.086623 iter 11430: 12.043952 ... iter 39970: 9.330720 iter 39980: 9.410215 iter 39990: 9.418270 iter 40000: 9.367644