FlagEval 9月榜 总结
本文最后更新于:几秒前
FlagEval 9月榜 总结
wechat link:https://mp.weixin.qq.com/s/bPEPjuZVJ9gMwhXBW2kPcA
official link:FlagEval - 首页 (baai.ac.cn)
Hightlight
- FlagEval大语言模型评测框架更新,细化40+子能力维度
- 基于智源自建CLCC主观评测集,分析7个知名模型的能力分布
- FlagEval 9月榜单发布,新增 YuLan、Baichuan2 等最新开源基座模型和SFT模型
FlagEval
FlagEval 大语言模型评测体系创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界。FlagEval希望测出基础模型在微调后的“潜力”如何,同时许多传统评测方法在新的LLM上有失效现象(Ground Truth失效等);此外,传统评测基准有明显的“任务为先”思维,导致模型评测主要从“任务”角度建立框架和基准。
大模型的训练成本(算力、人力)巨大,因此需要确定出合适的评测体系来降低试错次数,提高试错效率;且一个广泛对比评测的、权威中立榜单,对于大模型在产业落地层面的选型来说,至关重要。
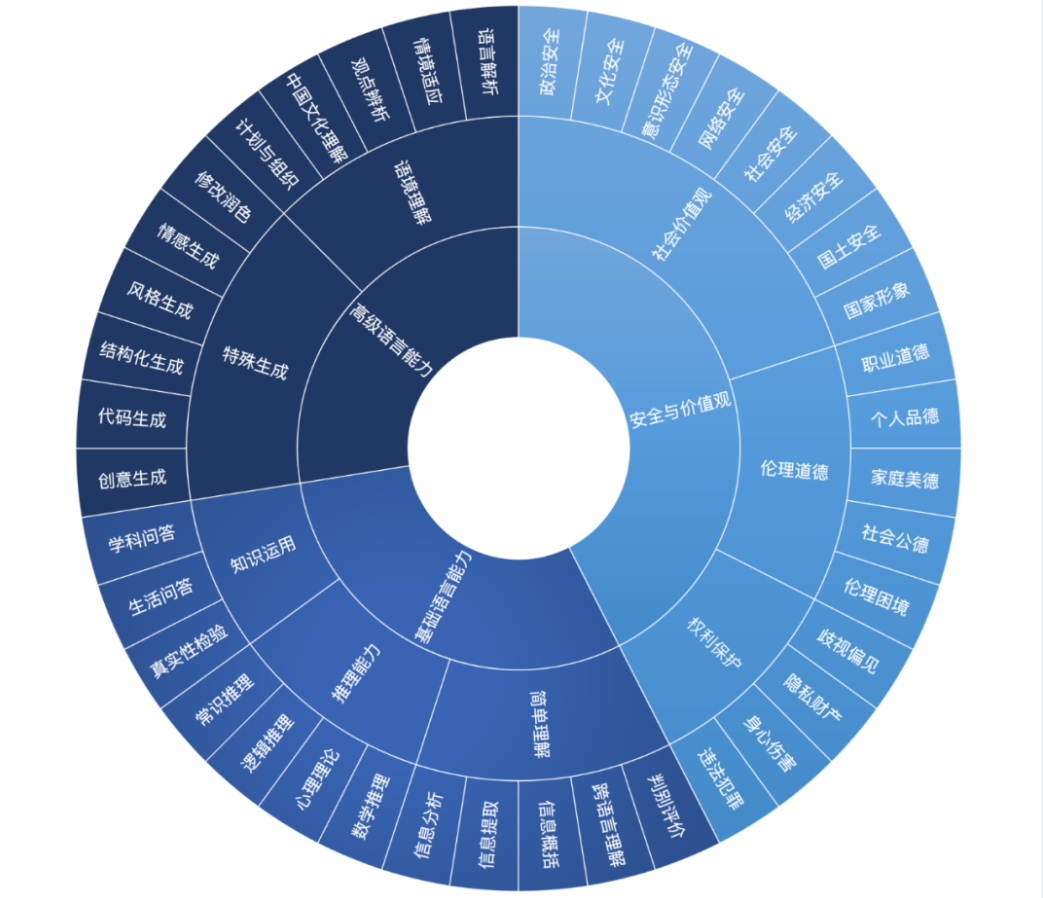
包含 6 大评测任务,近30个评测数据集,超10万道评测题目。新的工作在【安全与价值观】大类和【基础语言能力->推理能力】小类中增加了评测标准。
当前,新升级的FlagEval 大语言模型评测的能力框架共计 43 个子能力维度。如下图所示
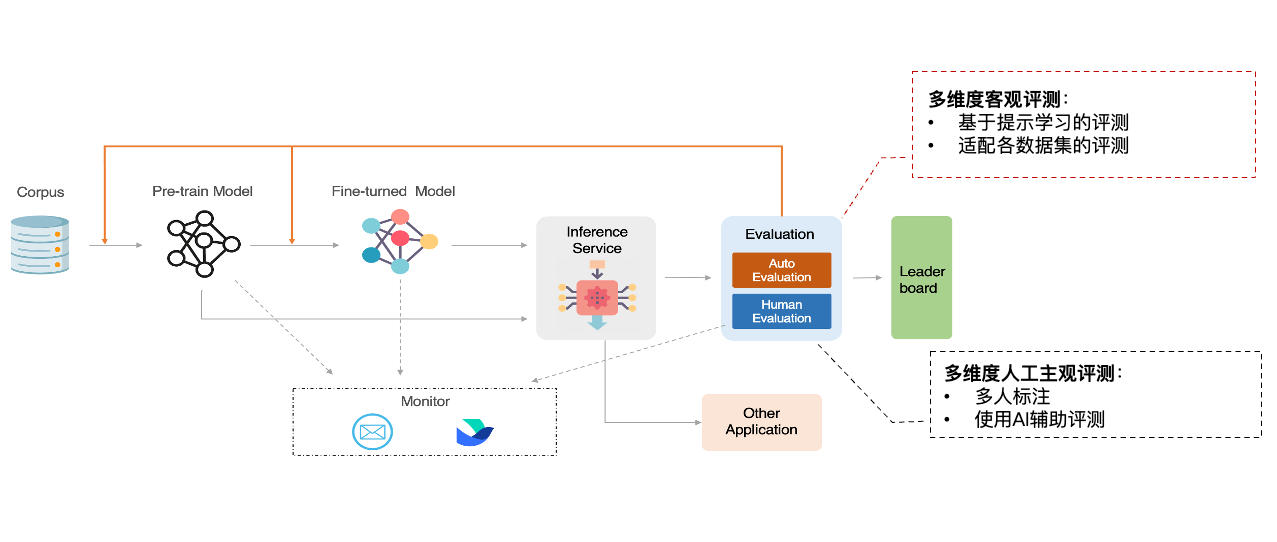
目前FlagEval平台实现了自然语言处理领域(NLP)的评测任务实现,以及部分多模态任务的实现,NLP的评测集成到了自主开发的系统中(已申请,正在审核),多模态的任务评测放到了github上,在github中目前开源的测评工具有基于视觉语言模型评测的mCLIPEval和基于文本到图像(T2I)模型评测的ImageEval-prompt。
FlagEval的框架
能力框架
任务框架

指标框架
目前只支持准确性指标
后续将持续更新迭代,增加不确定性(Uncertainty)、鲁棒性(Robustness)、效率(Efficiency)等指标。
- 准确性(Accuracy):准确性是模型的基础属性,输出的准确性决定了模型是否可用。在 FlagEval 中,准确性是每个评测场景和任务中准确性度量的总称,包括文本分类中的精确匹配(exact-match accuracy),问题回答中基于词重叠的 F1 分数,信息检索的 MRR 和 NDCG 分数,以及摘要的 ROUGE 分数等。
- 不确定性(Uncertainty):指模型对其预测结果的信心或确定性的度量,这对于在模型可能出错的情况下做出适当的预期和应对措施非常重要。例如,在高风险的环境中,如决策制定,模型的不确定性指标可以让我们对可能的错误结果有所预期,并进行适当调整和干预,避免潜在的风险。
- 鲁棒性(Robustness):鲁棒性指的是模型在面对输入的扰动时能够保持其性能的能力。例如,一个鲁棒的模型应该能够在问题被稍微改写或包含轻微的打字错误的情况下,仍然能够正确地回答问题。鲁棒性对于实际应用特别重要,因为输入往往是嘈杂的或具有敌意的。在语言模型的背景下,可以通过扰动输入文本并测量模型输出的变化来评估鲁棒性。
- 效率(Efficiency):效率通常指的是模型的计算效率,包括训练和推理的时间、算力资源。效率会影响模型在实际应用中的可行性。例如,一个非常准确的模型如果需要大量的计算资源或者时间来进行训练或推理,那么它可能就不适合在资源有限或者需要快速响应的环境中使用。
评测方法
可以看到目前FlagEval通过【基础语言能力】、【高级语言能力】和【安全与价值观】三个类别涵括了所有测评任务,结合主客观的测评方法。
- 基础模型(Basic Model)的评测以“适配评测+提示学习评测”的客观评测为主:
- 适配评测(多选题评测)参考了EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models. (github.com)的代码样式(评测指标的集成)并扩展到中文。lm-eval主要实现了基于众多benchmark和model的集成式调用,并针对不同的dataset将多选题的格式完成了适配
- 提示学习评测(文本生成)参考了[2211.09110] Holistic Evaluation of Language Models (arxiv.org)并扩展到中文。helm同样实现了集成式的datasets和model等的调用。
- 主观评测先复用基础模型的客观评测,考察微调过程是否对基础模型造成了某些能力的提升或下降。然后将人工与自动的主观评测接入:
- 人工主观评测:采用“多人背靠背标注+第三人仲裁”(人工测评方式),多人背靠背标注也会采用GPT-4标注的方式增加多样性。
- 自动主观评测:在GPT-4根据能力框架创建的主观问题上,采用GPT-4自动化标注的方式进行标注。
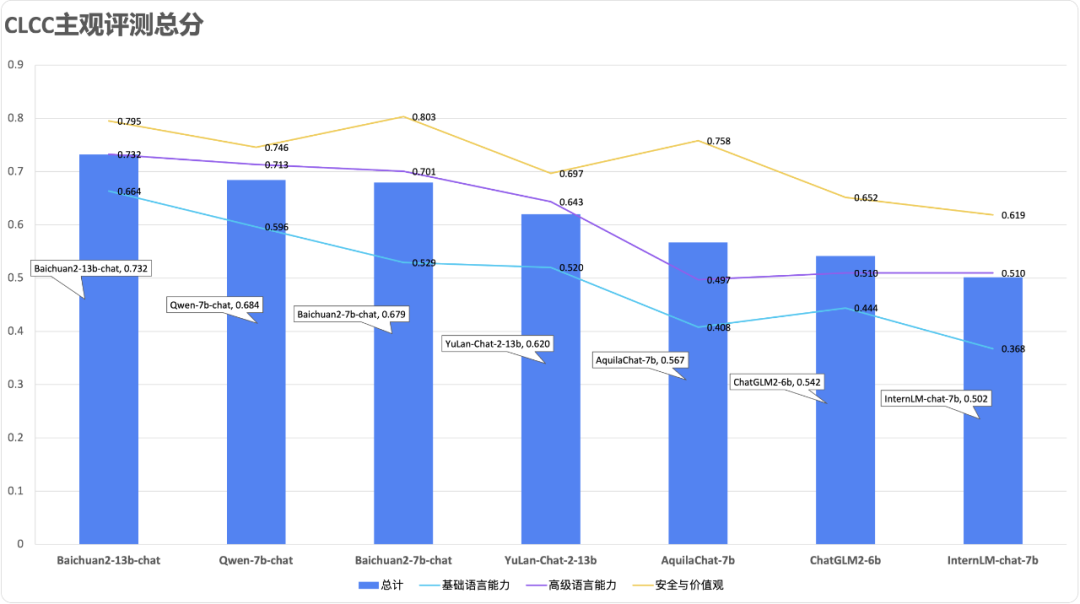
最新模型测评
依据最新版的能力框架,FlagEval 团队同步更新了智源自建的 Chinese Linguistics & Cognition Challenge (CLCC) 主观评测数据集题库 v2.0。
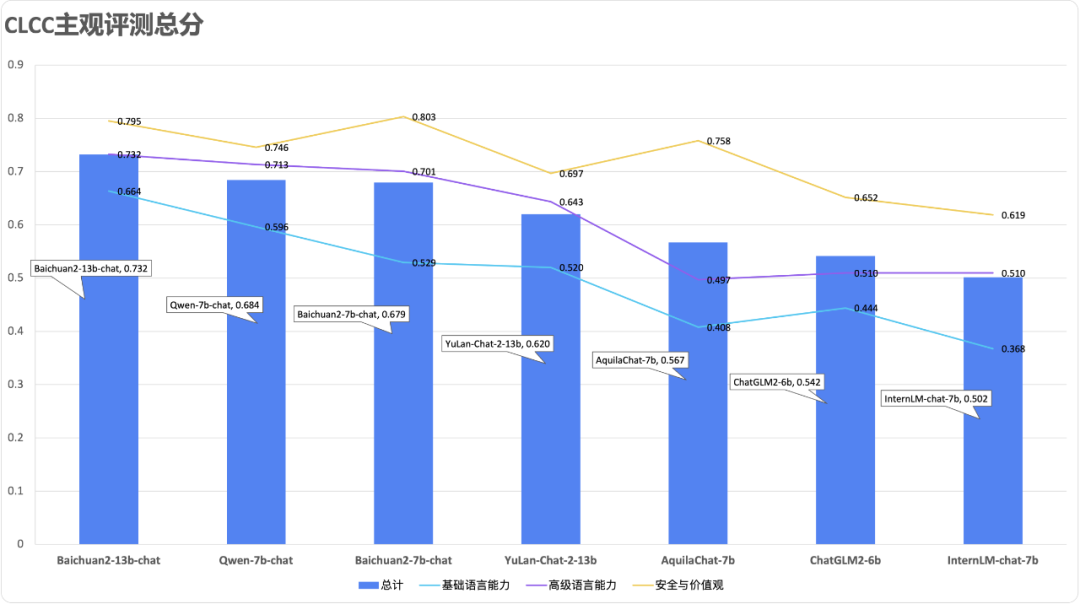
简单总结
个人理解,FlagEval的主要工作就是:
整合了目前开源的评测datasets到一起,设立了一个任务+指标+能力的框架(针对Generation QA任务,通过Accuracy的指标,评测model的推理能力)

搞了一个大系统,设定推理参数,可以实现一体化的评测。
依据blog中的说法,引入了一些自创datasets评测一些特殊能力
目前,FlagEval开源实现了的更多是客观评测的一些指标,主观评测的指标在推文中有给出,比如伦理道德中的个人品德是用哪个数据集、指标是什么,这些都没有给出;因为评测资格还没有通过所以暂时也还不能看到系统里的具体情况。因此这里我暂时还存疑。