CS224N课程P8:预训练技巧(Pretrain)
本文最后更新于:几秒前
课程词汇
1 | |
课程内容
子词模型
在自然语言处理的基本任务上,对单词本身的处理可以有两种比较极端的方法。
其一是从训练集建立起一个固定的数万个单词的词汇表,所有新的单词都映射为一个统一的UNK标志表示未知性。

其二是以字符作为编码的基本单位,将单词表示为字符的集合,这在一些语法复杂的语言中效果比较好,因为这些语言的单词多而频率相对低。
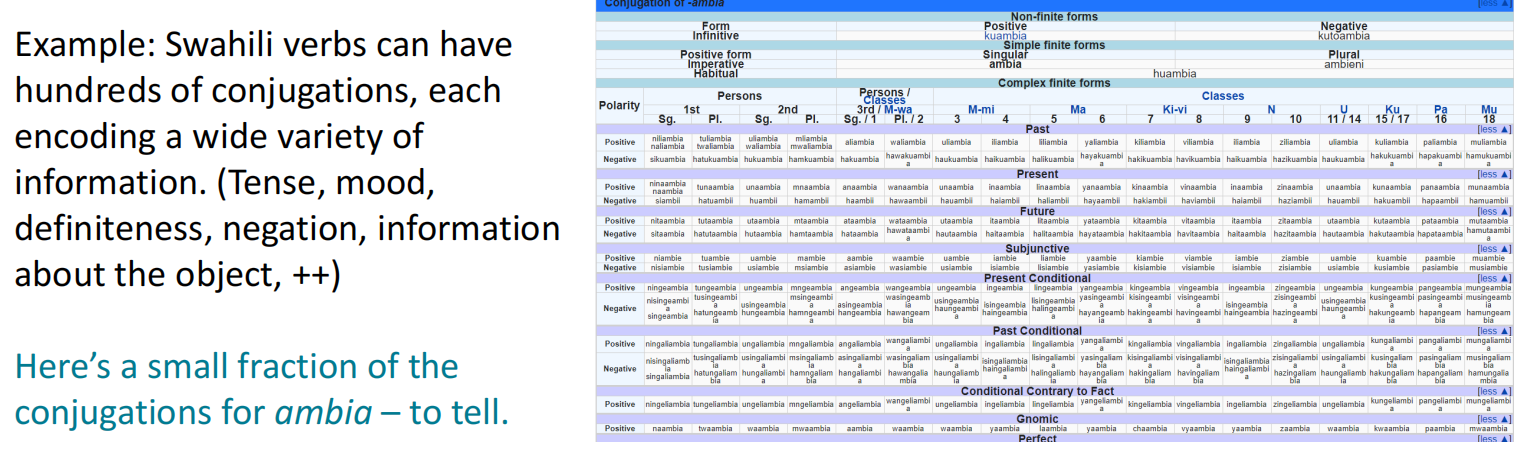
这两种方法各有优缺点,单词固定表示的映射效率高但很难处理新词,而字符表示拥有可变性但对单词的特点不太容易表示,因此目前主流的单词表示方法是两者的折中:子词模型(Subwords Model)。子词模型最初用于NLP机器翻译,现在类似的方法(WordPiece)被用于预训练模型。NLP中的子词建模包含了广泛的方法,用于推理词级以下的结构。(部分单词、字符、字节),其构造方法大致如下:
- 从只包含字符和“end-of-word”符号的词汇表开始;
- 使用文本语料库,找到最常见的相邻字符(e.g. “a,b”);添加“ab”作为子词
- 用新的子词替换字符对的实例;重复直到所需的词汇表大小
在子词生成过程中,常见词因为共现频率高,因此会被识别为一个单词,而新词会被切分为n个常见词。

子词模型的一个缺点是对子词是否“常见”的界定,最坏的情况子词模型会将一个单词(n个字符)切分为n个单词,大致退化为字符级表示方法,这就违背了我们折中的意愿。
预训练的引入
词嵌入的预训练
预训练的首先使用是在词嵌入模型中,在Circa 2017Semi-supervised Sequence Learning中首次提到了预训练技术,其中将词嵌入的部分进行预训练保存嵌入向量,将上下文分析的部分(LSTM/Transformer)作为下游任务处理。
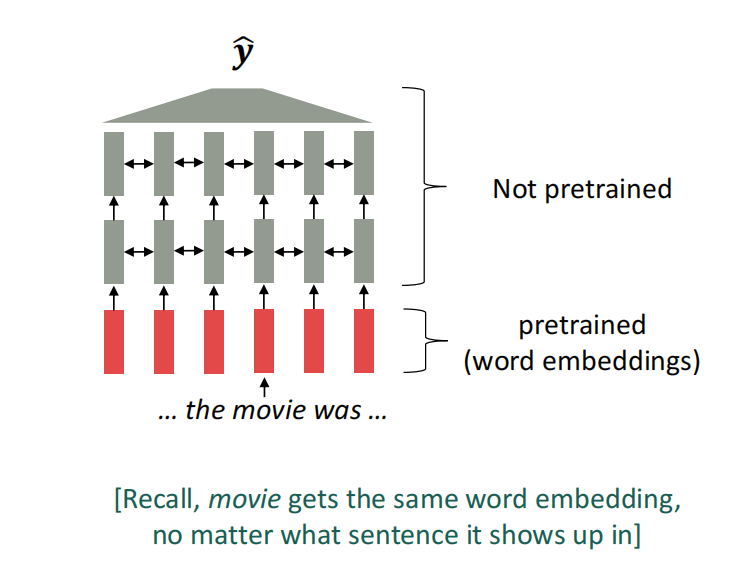
其中需要思考的一些问题:
- 为下游任务(如问题回答)准备的训练数据必须足以教授语言的所有上下文
- 网络中的大多数参数都是随机初始化的,没有进行预训练
整体模型的预训练
在现代NLP模型中,预训练模型是将模型的所有参数通过预训练进行初始化,以进一步用于下游任务。预训练的基本思路都是一致的:隐藏部分输入,并通过模型重建这些输入,模型的参数就是我们需要保存的信息。
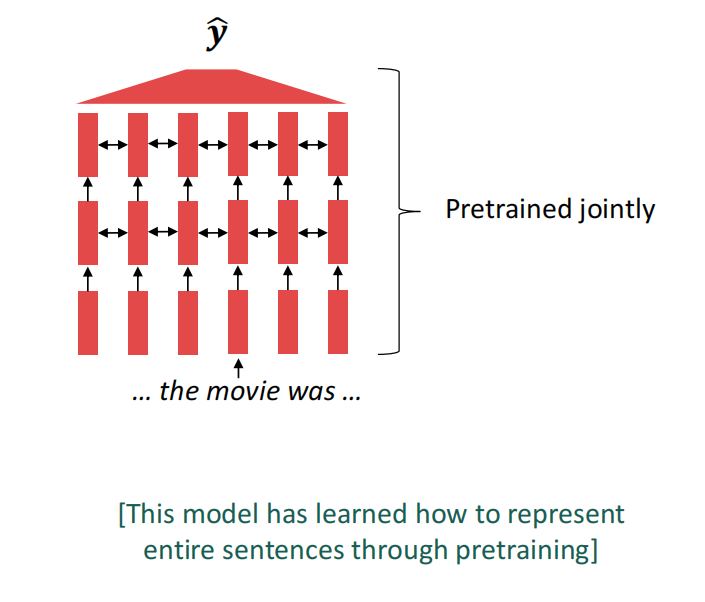
整体模型预训练对于语言表示、strong nlp model的参数初始化、可采样的语言概率分布等方面有着十分突出的表现。
对于重构后的输入,我们可以从中学习许多层次的知识,包括但不限于词汇的指代关系、相对位置关系、推理关系等等;

微调(Finetune)
预训练模型在语言模型中,通过训练神经网络对大量文本进行语言建模,然后保存参数。预训练模型是对下游模型的训练起点进行移动,将起点放到一个更适合或更容易的位置。下游训练时通过少量数据对任务本身进行finetune。
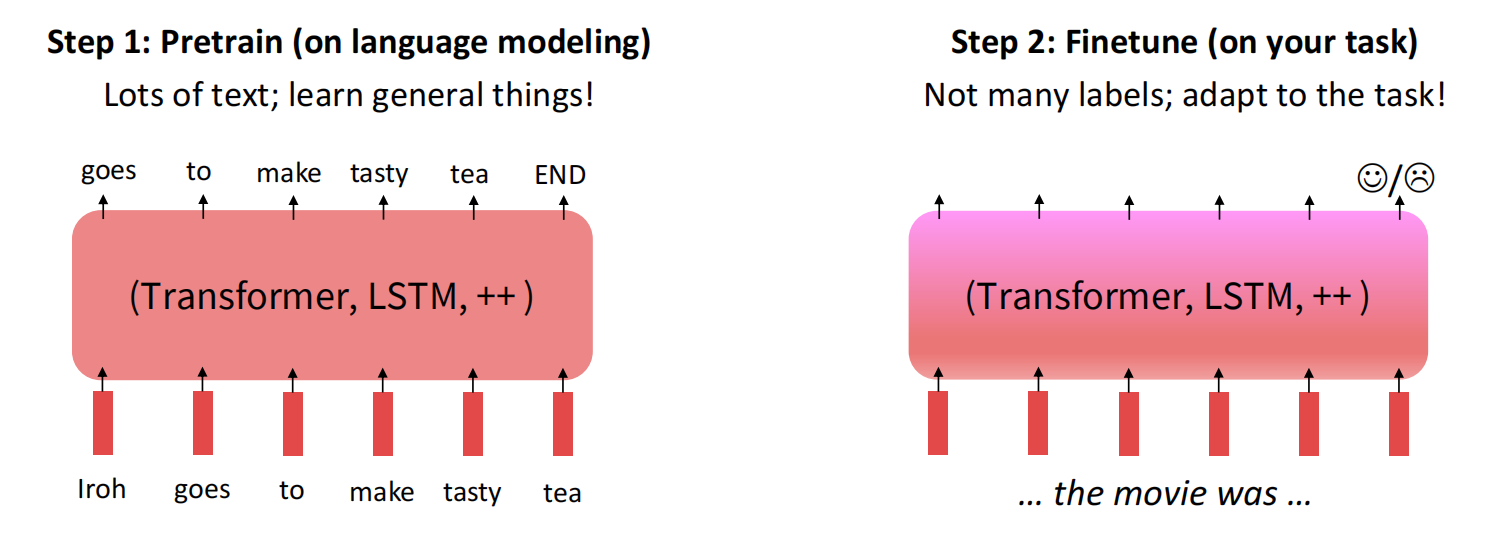
从“训练神经网络”的角度来看,预训练的过程是损失最小化$\mathcal L_{\rm pretrain}(\theta)$得到$\hat \theta$,然后微调是从$\hat \theta$开始最小化$\mathcal L_{\rm finetune}(\theta)$。在微调的随机梯度下降时,预训练得到的起始参数可能会和local minima或者global minima很接近,这也是预训练为什么能够高效的原因之一。
轻量化微调
全微调技术虽然效果很好,但每次对所有参数进行微调会对内存有很高的要求,因此引入了轻量化微调的技术。
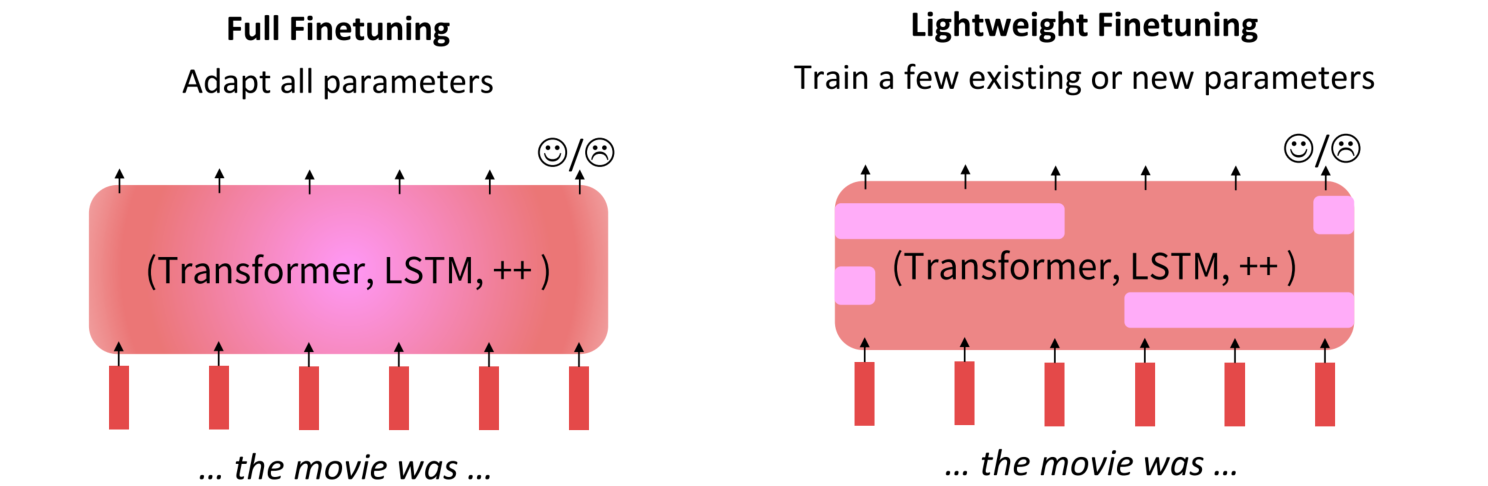
轻量化微调技术引入了参数的prefix的概念,首先冻结所有预训练参数,并将参数前缀送到模型处理,对前缀的处理和单词一样。推理时批次的每个元素都可以运行不同的调优模型。
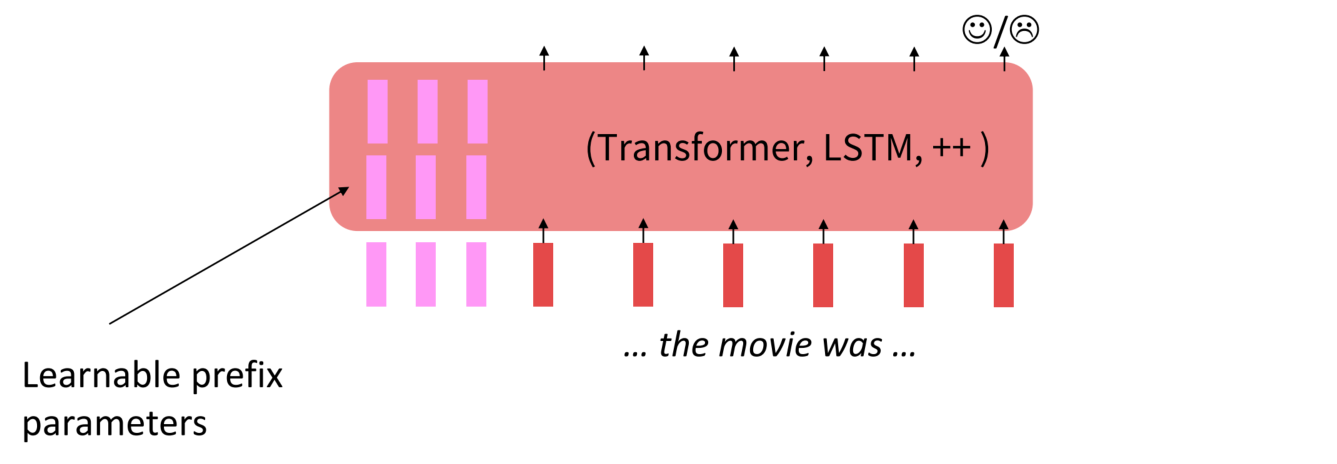
低秩适应
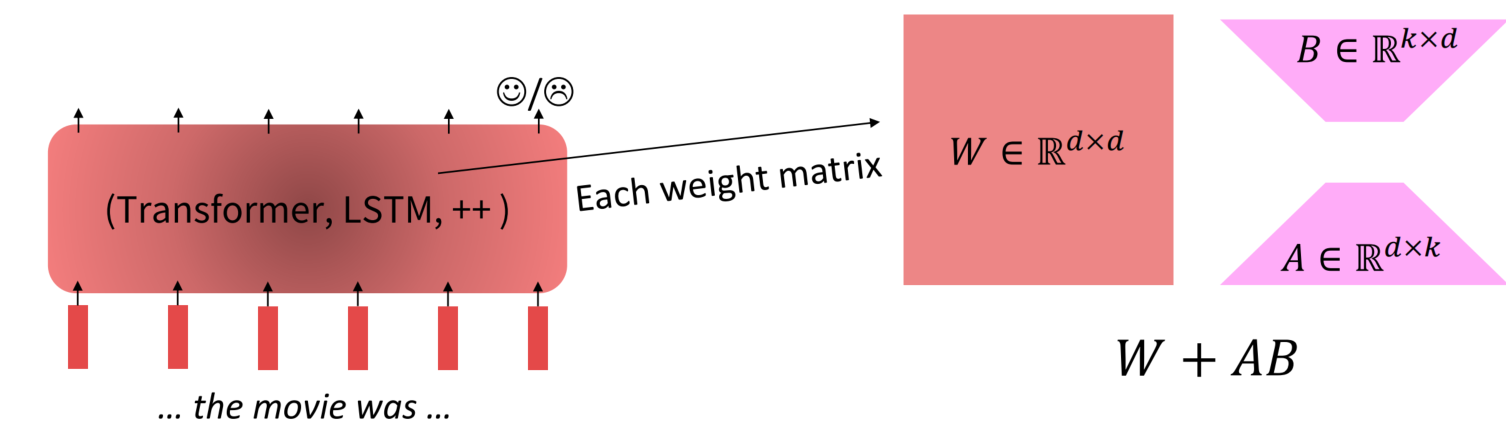
低秩适应学习预训练和微调权重矩阵之间的低秩“差异”,是微调技术本身的优化。虽然模型的参数众多,但其实模型主要依赖low intrinsic dimension ,那adaption应该也依赖于此,所以提出了Low-Rank Adaptation。低秩适应允许通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练的权重不变。
低秩适应的思路在于,在原始Pretrained Language model旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank 。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。
预训练模型的结构
Pretrained Decoder
Decoder预训练可以有两种模式:
不考虑Decoder用于概率分布$p(w_t|w_{1:t-1})$预测的用途,即不将其看作语言模型,在Decoder的最后一个隐状态加上一个分类器(线性或非线性)
$$
\begin{align}
h_1,…,h_T&={\rm Decoder}(w_1,…,w_T) \\
y &\sim Ah_T+b
\end{align}
$$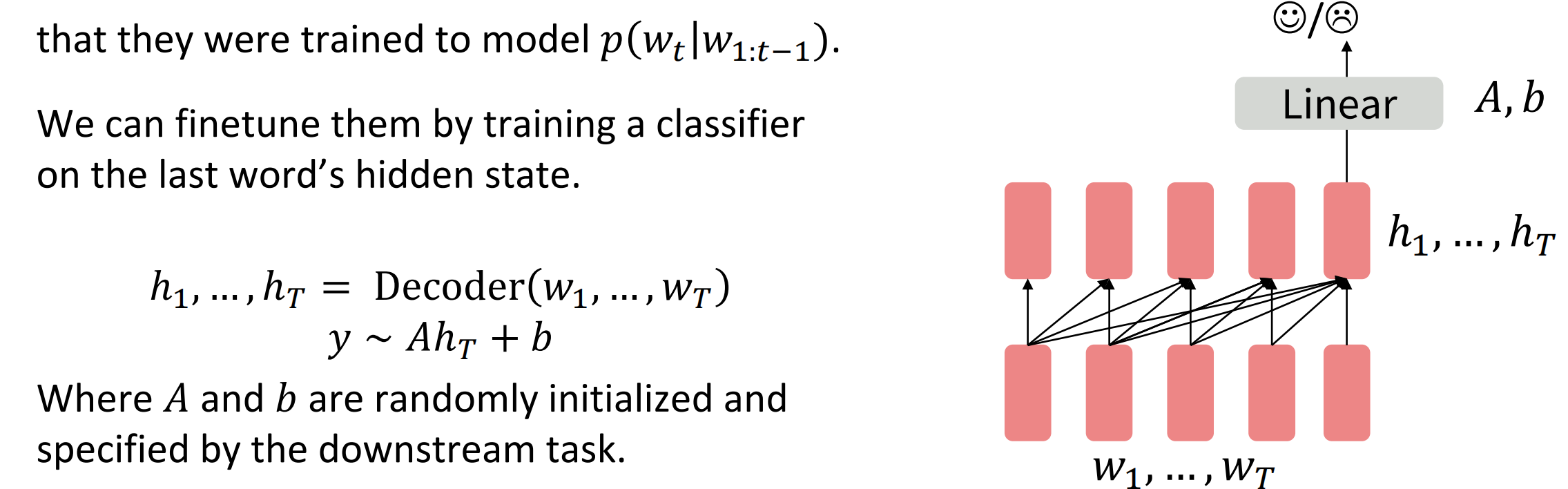
需要注意的是,这里的线性模型$A$和$b$都是外部参数,没有进行预训练;但是在预训练模型上finetune(梯度下降)的过程需要走整个模型(从上走到下)
将Decoder用作语言模型,建模$p(w_t|w_{1:t-1})$,微调概率分布中的参数$\theta$。这在训练前有充足的序列数据、且输出同样为序列数据时很有效,如对话、文本总结等等。
$$
\begin{align}
h_1,…,h_T&={\rm Decoder}(w_1,…,w_T) \\
w_t &\sim Ah_{t-1}+b
\end{align}
$$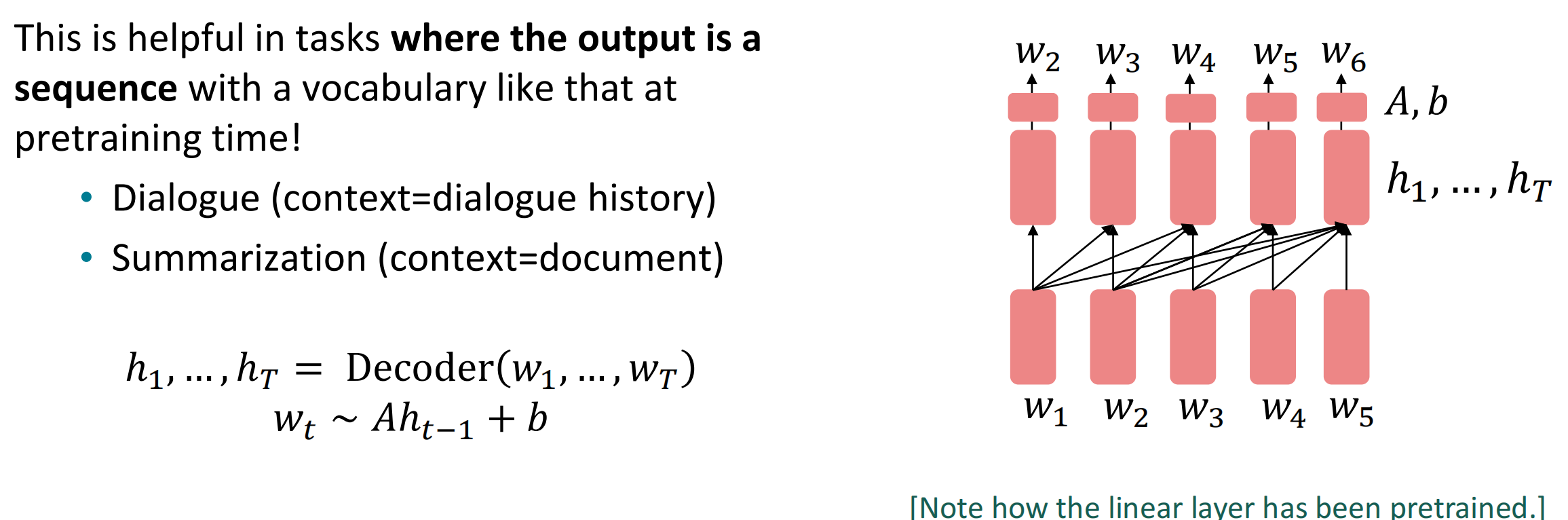
在这种模式下,参数$A$和$b$都是预训练中需要训练的参数,因此会更有一般性,更容易进行下游任务的建构。
GPT(Generative Pretrained Transformer)
2018年,GPT作为Decoder预训练模型获得了巨大成功。

在GPT中,为了微调方便(Finetune),也为了能够让更多的任务适配,微调的输入都有着一个格式规定,定义一些特殊的token表示训练时的动作信息,如

这其中有[start]、[delim]和[extract],分类任务就是从结尾的[extract]标记的表示作为输入进行训练。
GPT-2
GPT-2基于GPT,GPT-2 是在更多数据上训练的更大版本 (1.5B) 的 GPT,它被证明可以生成相对令人信服的自然语言样本。
GPT-3
GPT-3基于GPT-2的部分,作为一个非常大的语言模型,其可以简单地从您在其上下文中提供的示例中执行某种没有梯度步骤的学习,从而降低模型学习步骤的复杂度。GPT-3 有 1750 亿个参数。
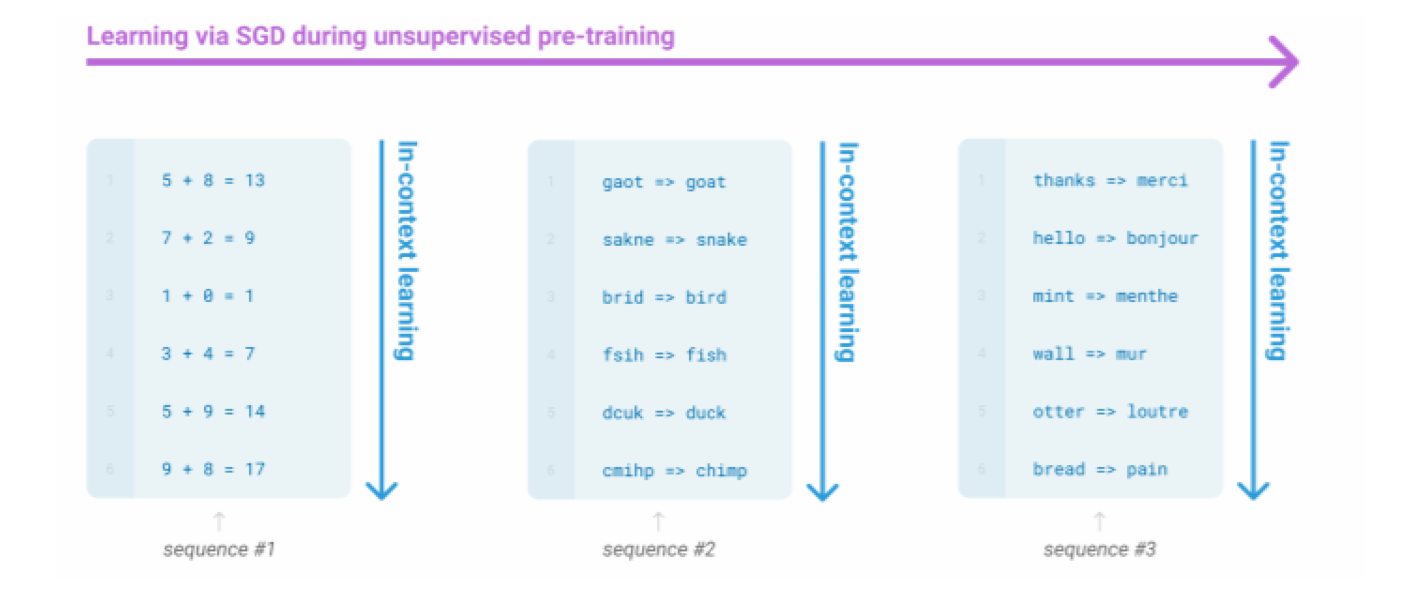
在GPT-3的模型训练学习过程中,其认为上下文中的例子指定了要执行的任务,条件分布在一定程度上模拟了执行任务,从而可以通过直接学习上下文来获得有效的表示与信息。

Pretrained Encoder
和Decoder面向于语言模型建模不同,Encoder的主要目标为对语句构建有效的表示,Encoder是双向模型,其可以获取到双向的上下文信息,为了能够实现语言的缺失表示,可以引入屏蔽技术。具体来说,将Encoder的输入覆盖掉一部分,用[MASK]代替,然后Encoder训练时来预测这些词,训练的损失只从这些屏蔽掉的词中获取,令$\tilde x$是单词$x$的被屏蔽版本,那么模型的损失函数就是$p_\theta(x|\tilde x)$的最大化,即两者越相似越好。
$$
\begin{align}
h_1,…,h_T &= {\rm Encoder}(w_1,…,w_T) \\
y_i &\sim Aw_i+b
\end{align}
$$
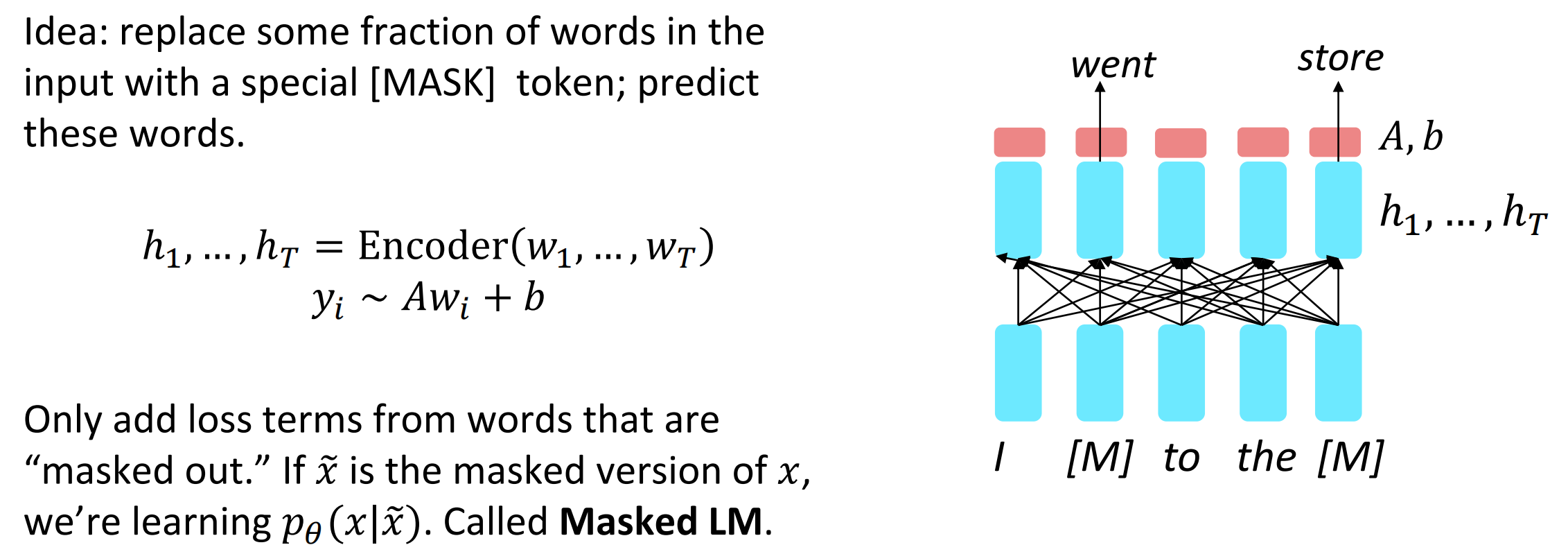
BERT
基于此,Devlin 等人在 2018 年提出了“Masked LM”目标并发布了预训练Transformer的权重,他们将这个模型标记为 BERT。在BERT中,对于[MASK]的使用,论文中希望不要让模型确定的知道[MASK]的具体位置,如果模型知道了[MASK]固定会在哪些位置出现,那么模型就不会对没有屏蔽的单词提供强大的表示,这样就违背了模型对语句所有位置提供强大表示的目标。具体的,BERT对[MASK]的使用有如下规则:
- 随机选择15%的子词标记(Tokens):
- 对其中输入单词的80%用[MASK]替换
- 对其中输入单词的10%用其他随机token替换
- 剩下的10%不变
[MASK]的应用更多的是让模型的表示能力加强,而不是在训练完成之后作为采样来用于下游,因为[MASK]生成的结果仍然有随机性。

BERT的输入包括了两个独立的连续的chunks,其中BERT训练时需要判断两个chunks中后面的chunk是前面chunk在数据集中紧随的语句,还是一个随机采样的语句,这样BERT也提高了数据集输入分布的随机性。
但这种随机性的作用大小有待考究,目前也有研究在致力于将BERT的这个随机输入直接改成更长的语句,以提高模型的长文本表达能力。
BERT的模型架构细节如下,其中需要注意,BERT的预训练时间成本比较高,但Finetune十分实用而且可以多次微调。

BERT在许多任务上都有十分显著的效果。
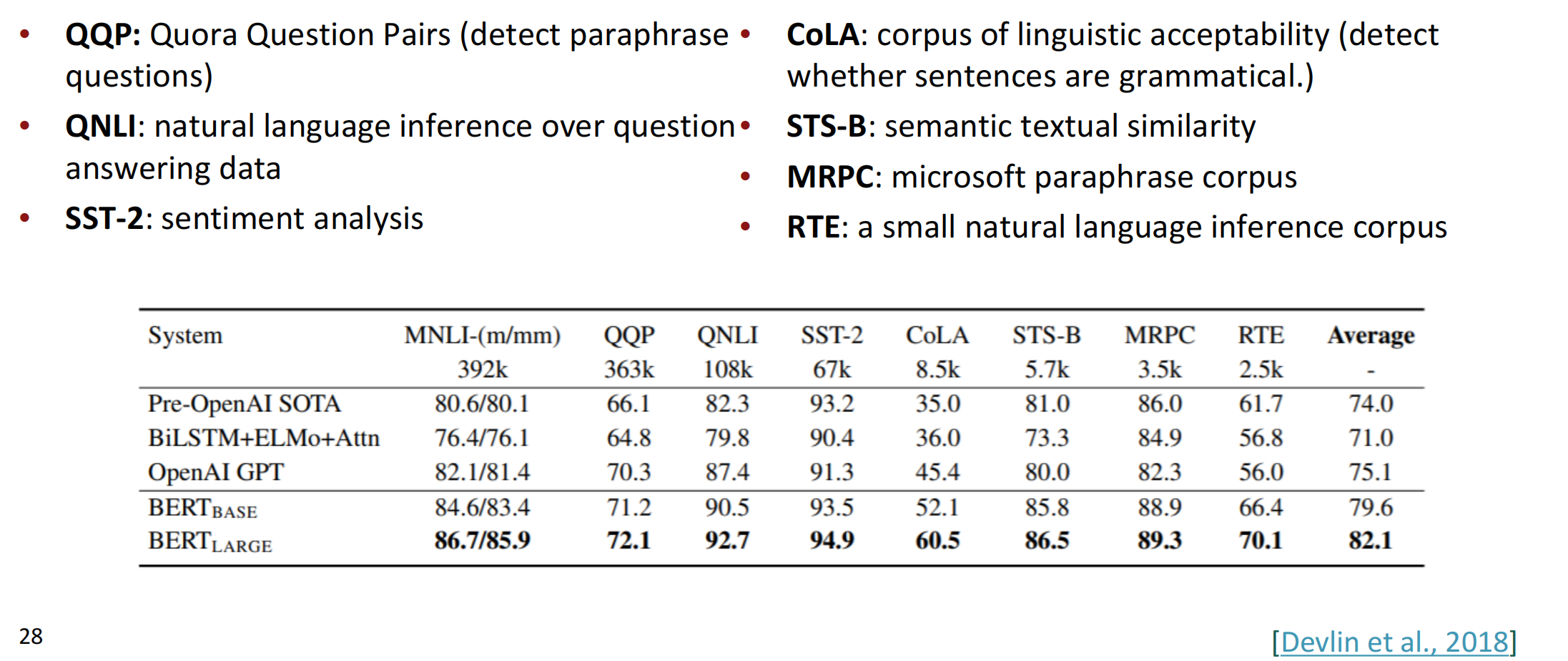
虽然Pretrained Encoder在很多任务上效果都很好,但因为Encoder在语言建模上主要是对词语离散性的去预测, BERT和其他预训练编码器不会自然地导致良好的自回归(一次一个字)生成方法。因此在语言模型上还是Decoder比较出色。
BERT的扩展
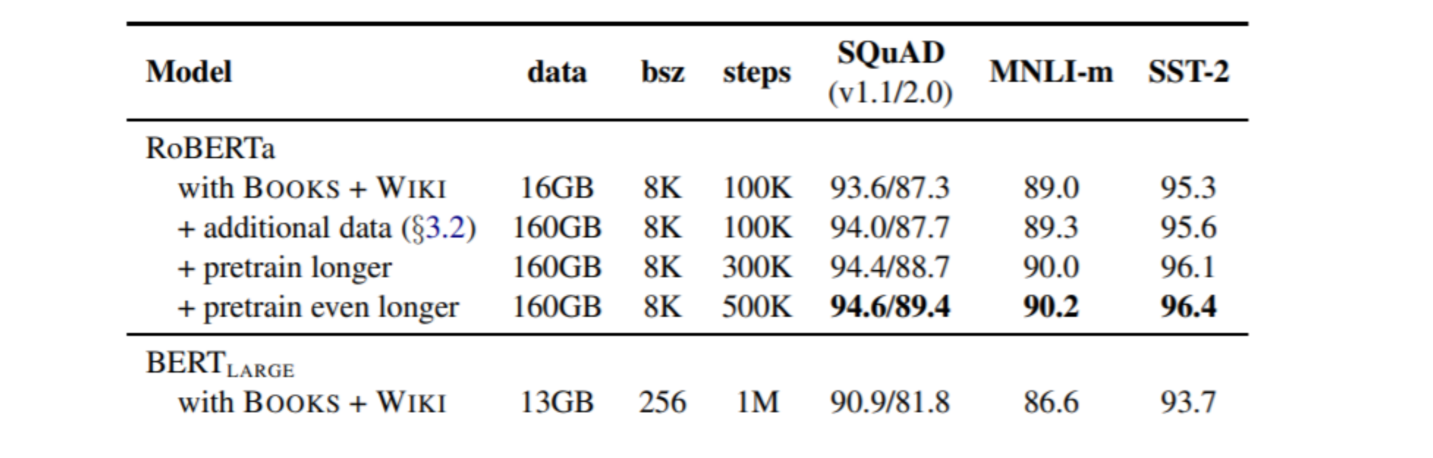
RoBERTa:去掉下一句预测的环节;BERT的训练时长更长,参数规模更大。
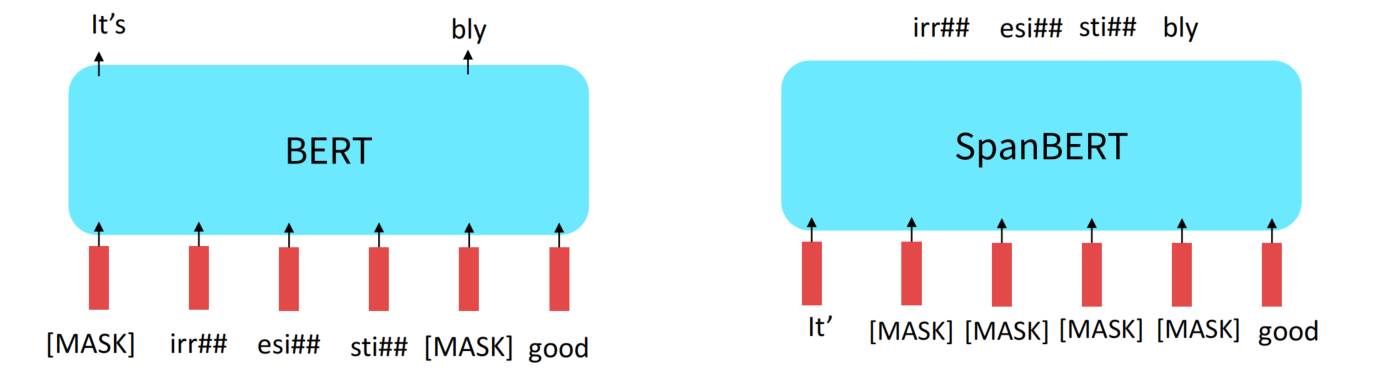
SpanBERT:连续屏蔽多个词,使模型更难去预测序列。
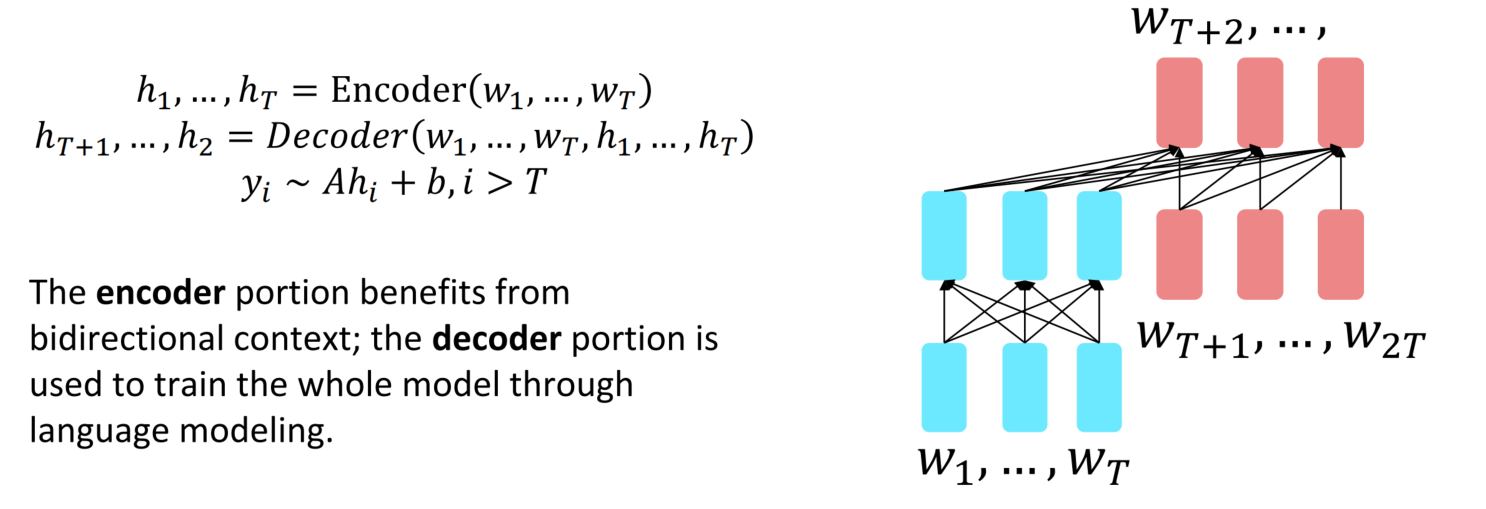
Pretrained Encoder-Decoder
预训练Encoder-Decoder结构是由Encoder和Decoder两个部分构成,其中Encoder接收输入用于获得强大的语言表示,Decoder接收输入和Encoder表示用于语言建模。对于Encoder-Decoder,我们可以做一些类似语言建模的事情,但是每个输入的前缀都提供给编码器而不是预测。
$$
\begin{align}
h_1,…,h_T & = {\rm Encoder}(w_1,…,w_T) \\
h_{T+1},…,h_{2T} &= {\rm Decoder}(w_1,…,w_T,h_1,…,h_T)\\
y_i &\sim Ah_i+b,\ \ \ \ i>T
\end{align}
$$
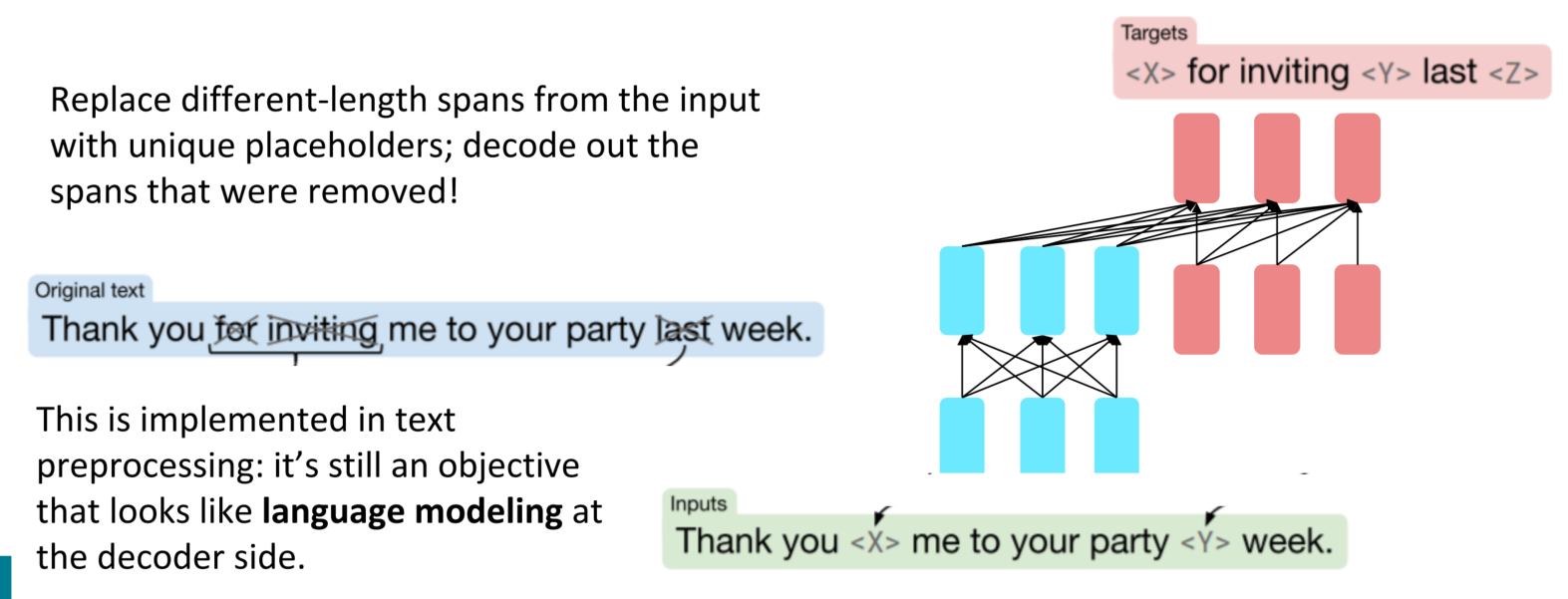
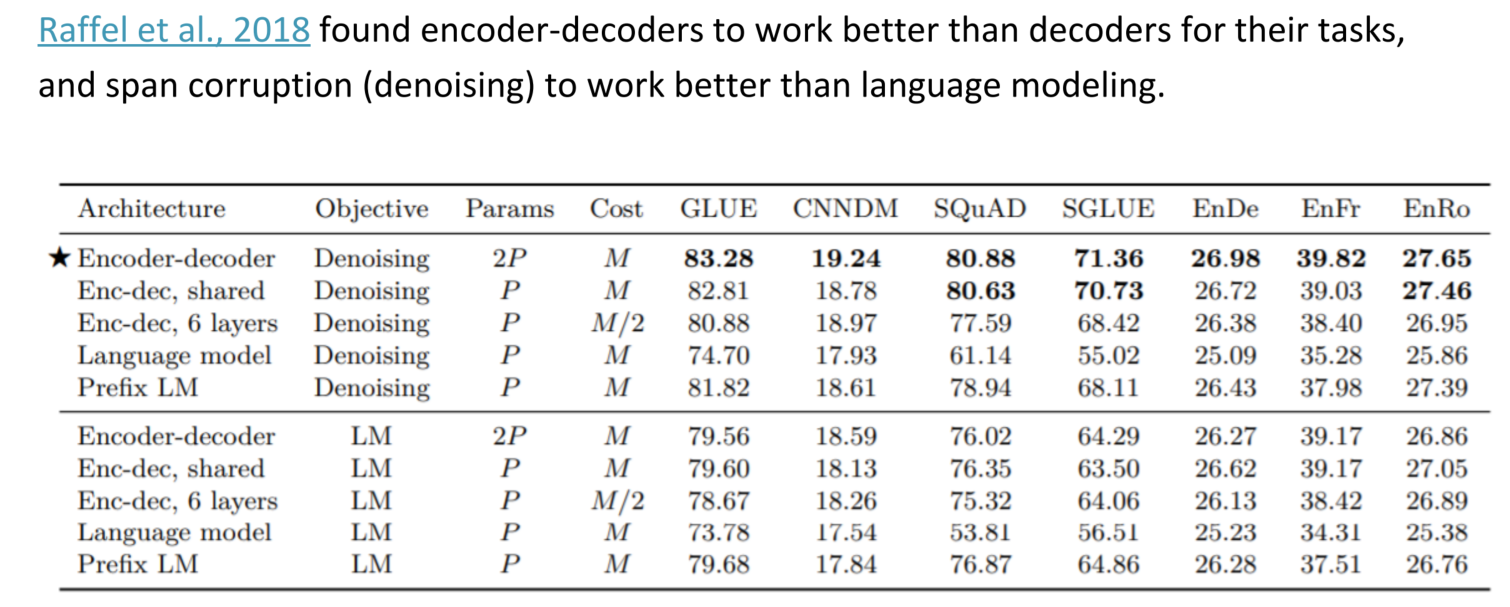
目前在业界,Encoder-Decoder中比较优秀的是Raffel et al., 2018所提出的T5模型,在其中加入了span corruption的技术,即Encoder部分替换不同长度的spans并用独一无二的标记表示,Decoder解码出被删除的部分。
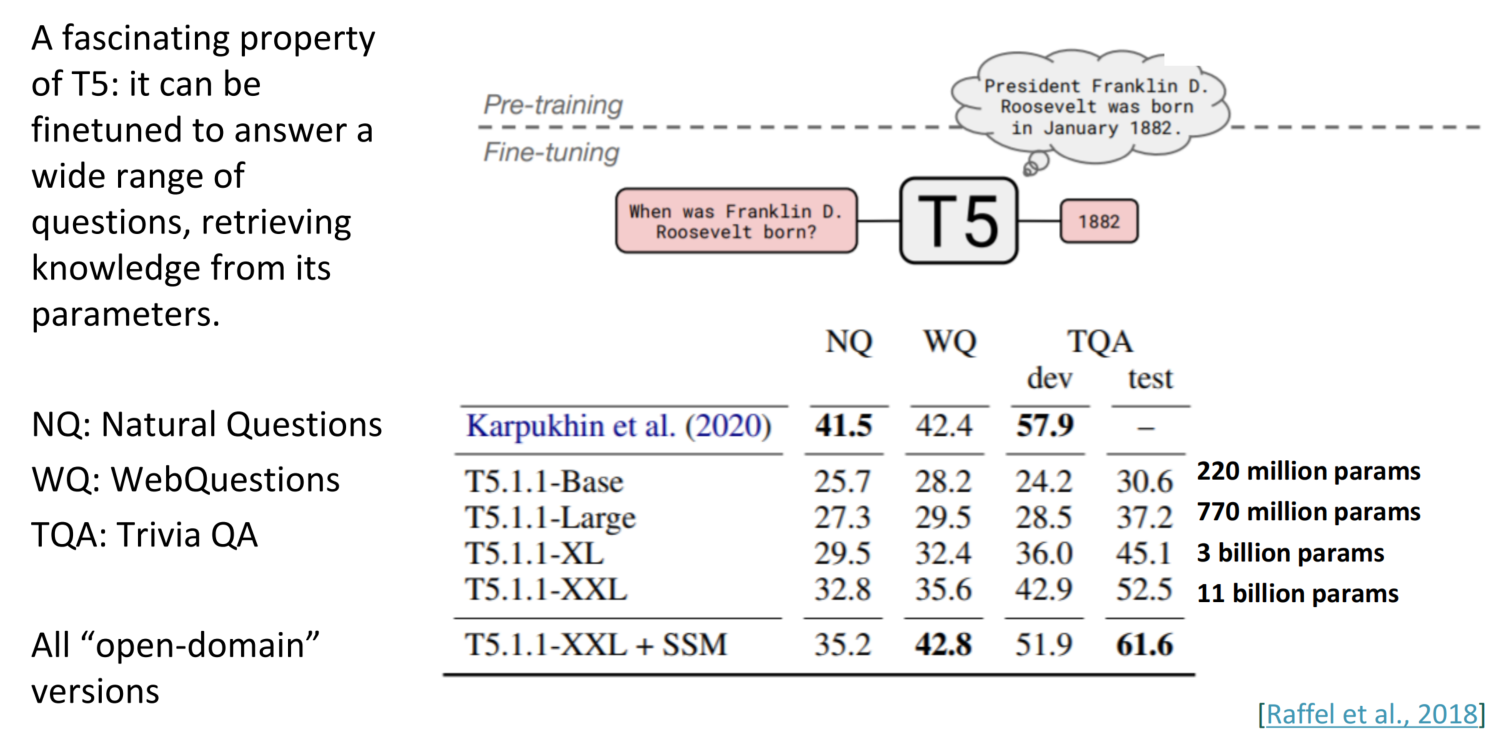
在T5模型中,一个比较出众的部分是在微调阶段,T5可以根据问答的结果从其参数中检索知识,并微调模型以逐渐适配问题,这种类动态性十分厉害。
课后问题
Q:子词模型中的”##”代表的是什么意思?
A:代表的是类似于分词的符号,##告诉我们其前面的单词不是一个单独的完整单词,比如subwords也许会被模型分为sub和words,表示为sub##words,这里的sub是属于原词的一部分而不是一个单独完整的词。
Q:预训练模型有没有过拟合的风险在?
A:目前的大模型训练来说,更多的风险在于欠拟合而不是过拟合。
Q:T5模型中的<x>、<y>是怎么继承的呢?
A:Decoder的预测部分首先需要取到标记,知道这块需要预测,然后模型预测出结果,这里就已经实现了一一对应。