云计算课计算重点笔记
本文最后更新于:几秒前
先想输出长什么样子,然后反推
批量计算
倒排索引
初次思考
按照文件的数量分成多个$batch$,对每个$batch$进行$Map$过程,$Map$过程为列出$<词,[文件名,]>$的键值对,$Reduce$过程合并所有键值对中键相同的值列表,即按照词进行文件名的合并,最后输出。
讲解
按照文件的数量分成多个$batch$,对每个$batch$进行$Map$过程,$Map$过程为列出,$Reduce$过程 ,即按照词进行文件名的合并,最后输出。
相似度比较
初次思考
没思考出来。。
讲解
。键值对中的键是文本对$<文本1,文本2>$,相似性是按照词的重复次数来计算。首先先倒排索引,将文件处理成词语-文件-次数的数据,根据词将倒排索引的结果进行$batch$,然后根据词语进行$Map$,$Map$过程根据词语,将有相同词语的文件合并,$Map$的结果为$<<文件1,文件2> | 重复次数>$,其中重复次数需要设定统计方式,中间过程和$Reduce$过程将每个$batch$中键相同(即文件对相同)的进行合并,重复次数相加,最后输出为重复次数超过阈值(阈值自定义)的结果。
关系的自然连接
键值对:需要加上标记位。
$Map$过程加入,结果为$<order | <表名,[值1,值2,…]>>$,$Reduce$过程按照键$order$和标志位$表名$,进行两两连接。
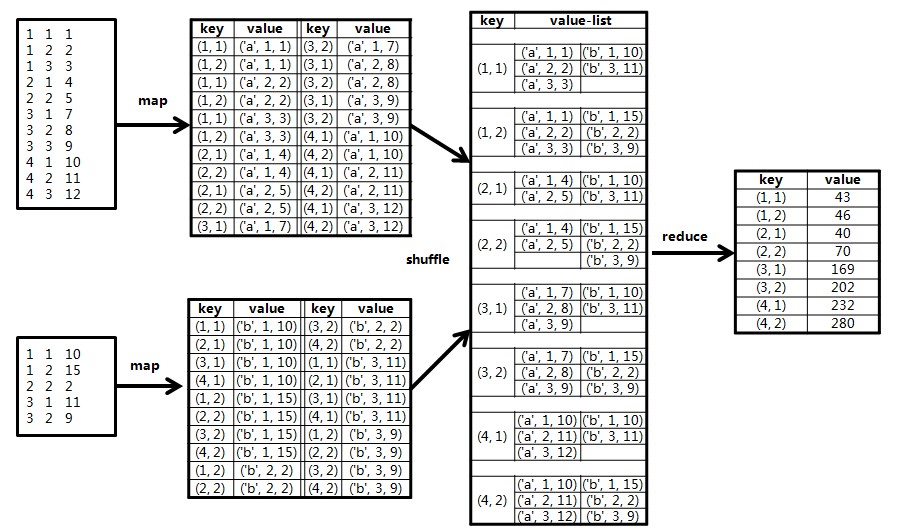
大矩阵乘法(去年考了)
存储方式:[行标 列标 值]
键值对:$<<行标,列标> | 值>$
思路是先定义输出结果,然后回推,看计算的最终结果需要的是哪个部分。
电商购物的订单统计
流式计算
中小学选班长

图计算
舆情传播
迪杰斯特拉算法(计算每个点的最短路径,模拟时判断当前时间和最短传播时间)
加概率,免疫传播,
云计算课计算重点笔记
http://paopao0226.site/post/475f1eb0.html