Hadoop安装指南
本文最后更新于:几秒前
Hadoop一步完成安装指南
本博客部分参考于 Hadoop集群安装和搭建(全面超详细的过程)_小汤TYT的博客-CSDN博客_hadoop环境搭建与安装并稍有修改。
Hadoop是一个开源的、可运行与Linux集群上的分布式计算平台,用户可借助Hadoop存有基础环境的配置(虚拟机安装、Linux安装等),Hadoop集群搭建,配置和测试。可以借用Hadoop实现高效化的集群环境的搭建与分布式计算。
以下是hadoop的安装步骤:
VMware的安装
这个不再本博客再赘述了,大家可以参考此博客:
虚拟机安装
首先到镜像网站将Linux系统的镜像包下载下来,这里使用的是CentOS7(mini)的安装包
centos-7-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
安装虚拟机
点击【Vmware->文件->新建虚拟机】
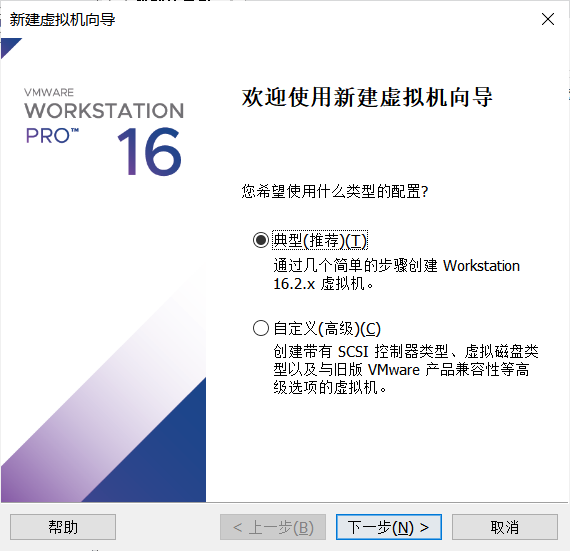
安装程序光盘映像文件。
这里需要定向到刚刚下载的iso文件。
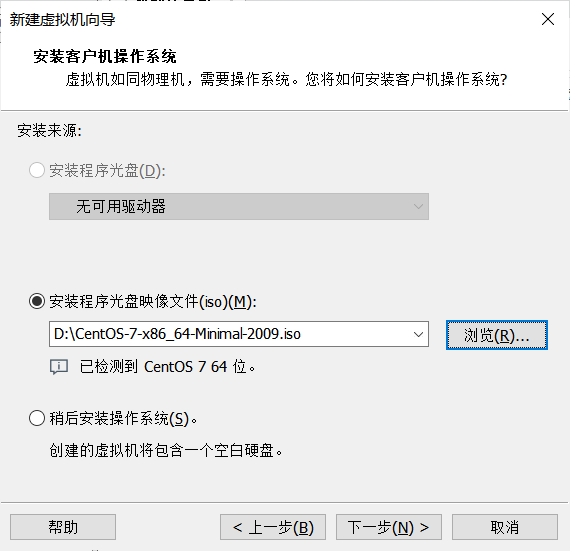
修改名称与安装位置
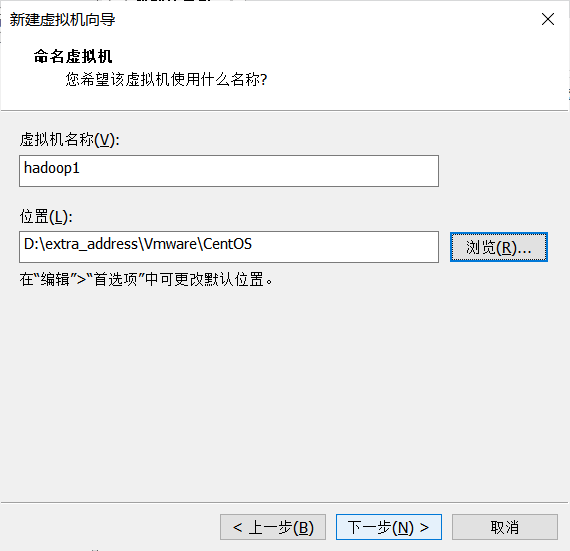
分配内存。
一般是默认系统的安装内存(20G),我的电脑内存剩余太小了,怕炸掉所以用了10G,注意选择将虚拟磁盘拆分成多个文件。
完成之后点击配置,即可以看到现有的系统配置,可以选择默认配置,下一步。
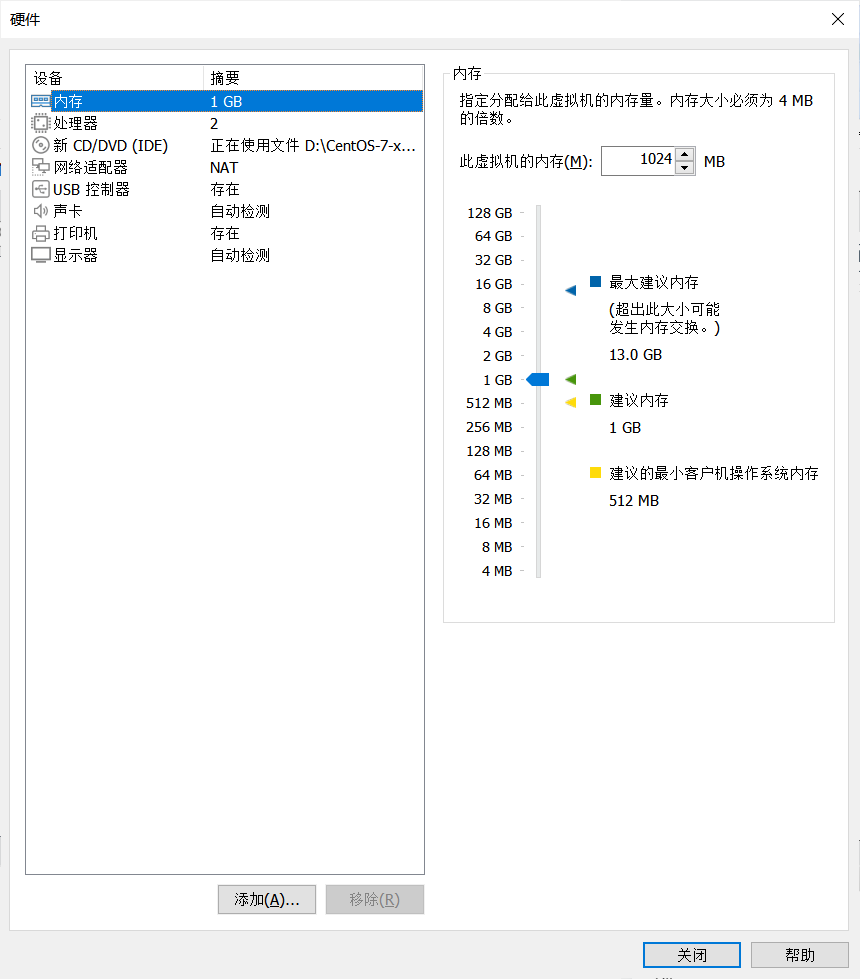
点击完成就结束了单个虚拟机的硬件安装过程。
运行CentOS系统,开始安装系统软件
选择时区为上海,语言为中文
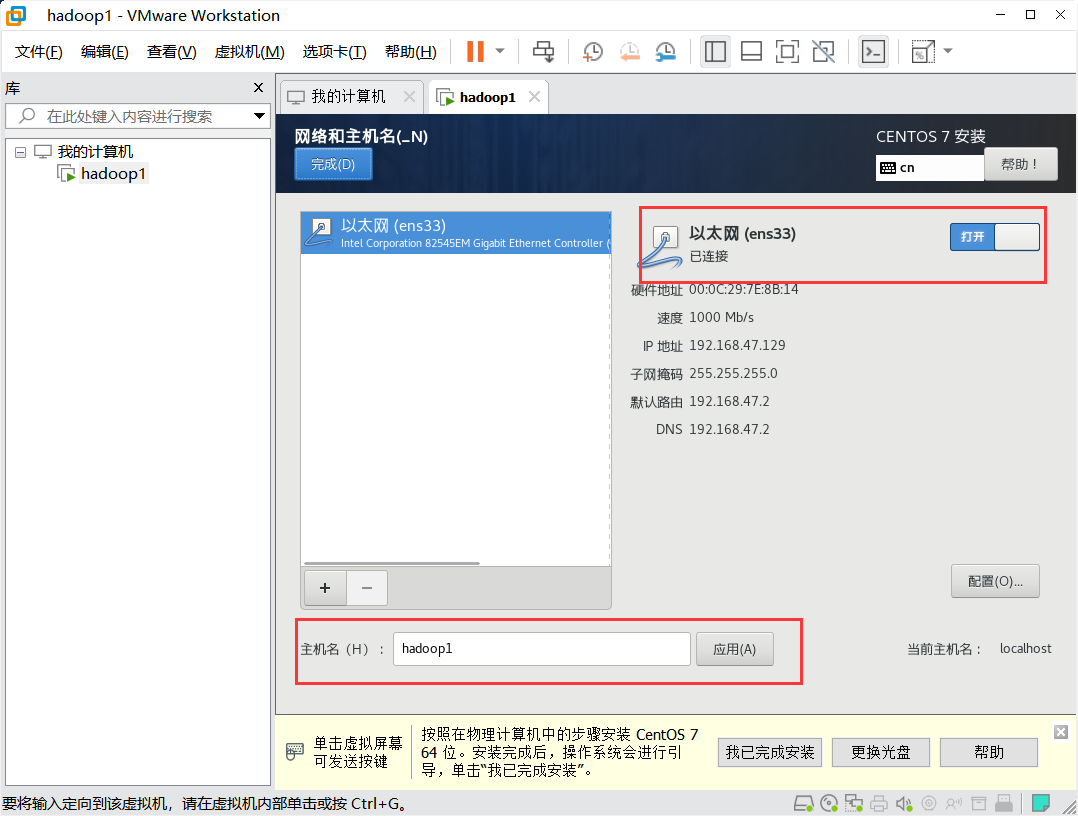
配置系统网络并连接
注意设置主机名
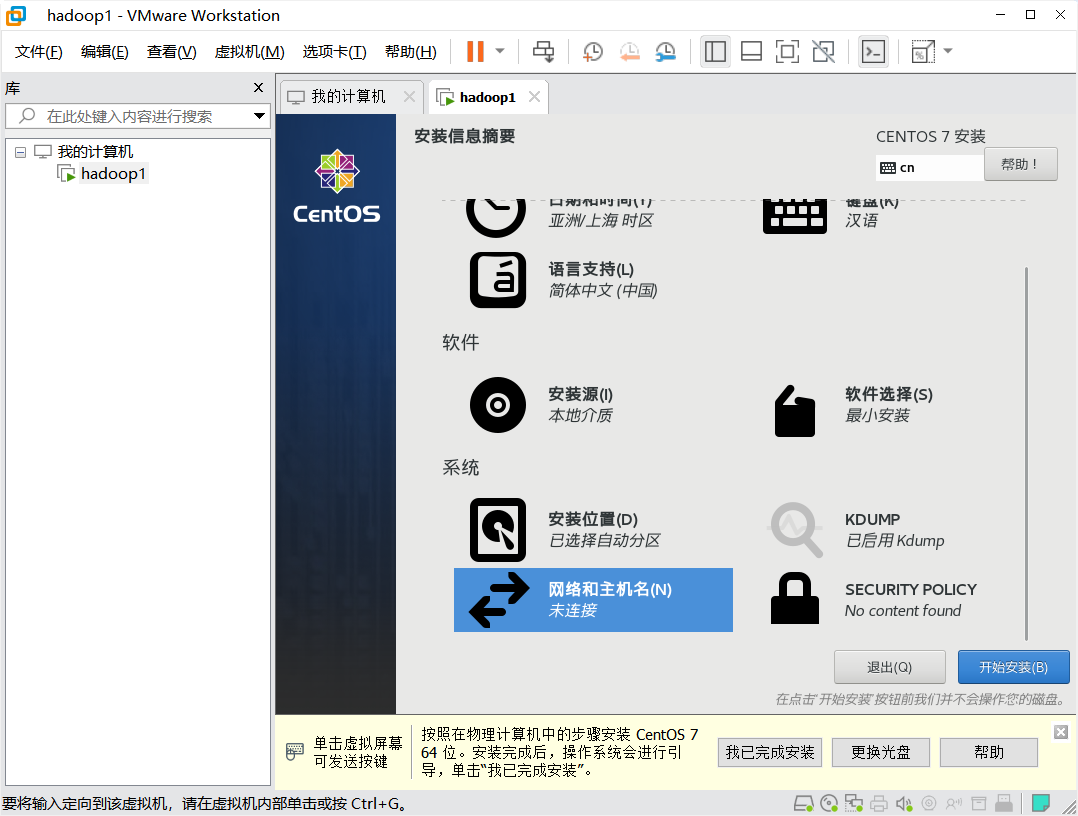
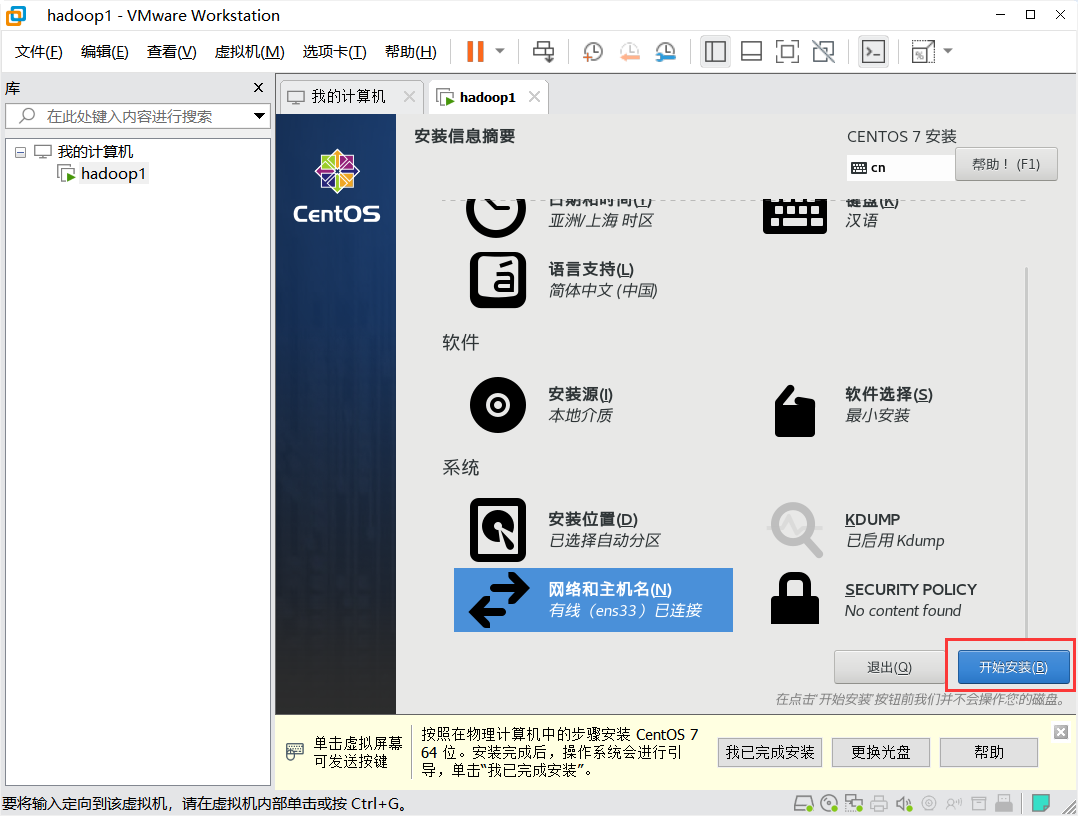
点击开始安装,设置用户名和密码,不创建用户(默认为root)。
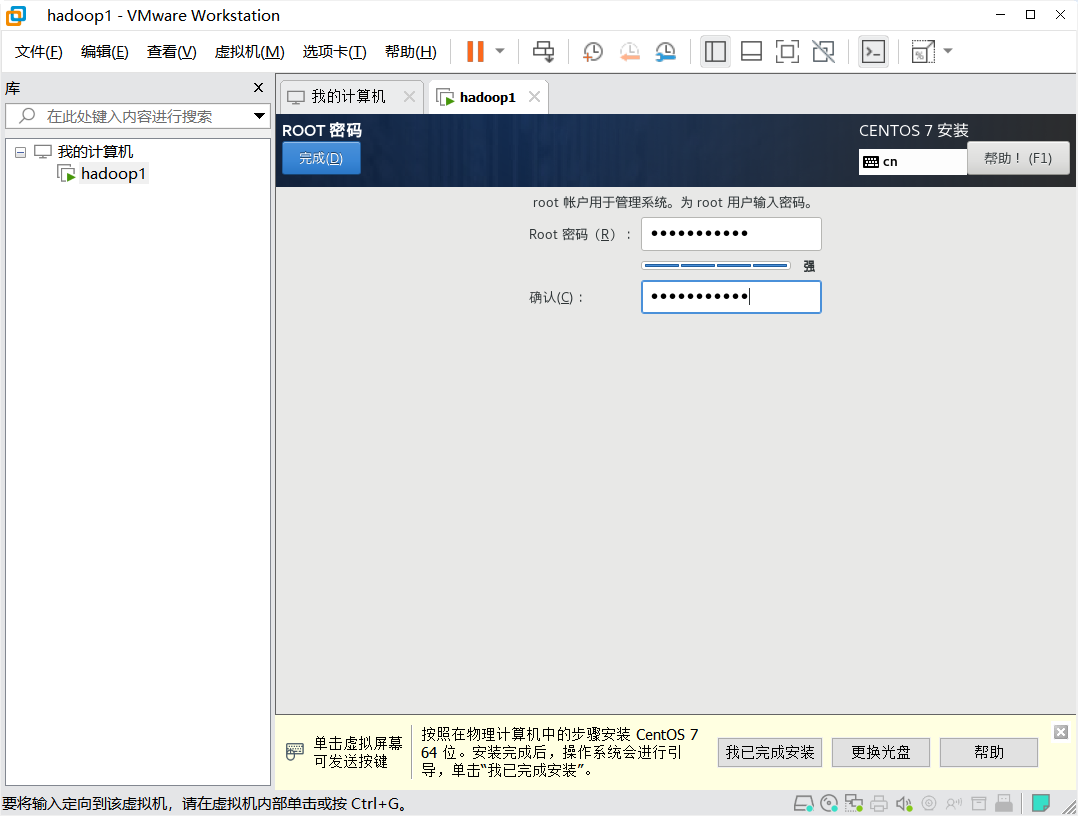
完成安装,重启。
使用root账户【用户名:root;密码为自设密码】登录系统
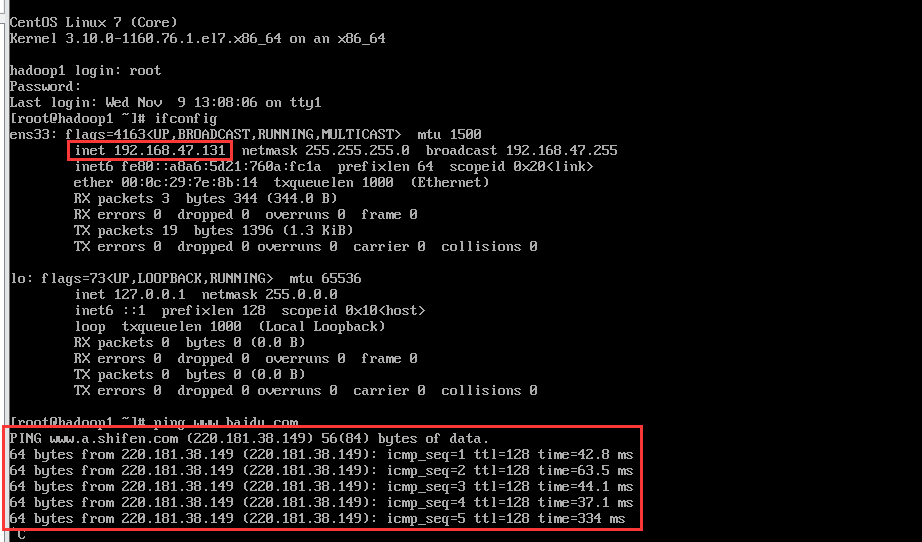
使用ping指令测试一下网络是否联通

地址配置
安装net-tools工具
net-tools工具可以便于之后操作网络地址信息
1 | |
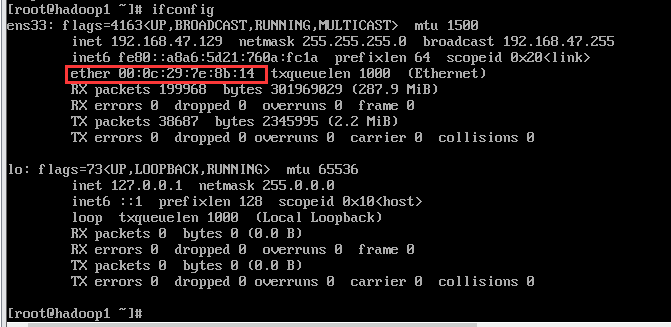
查看MAC物理地址和ip地址范围
1 | |
将【enter】后面的mac地址记录下来,之后用到。
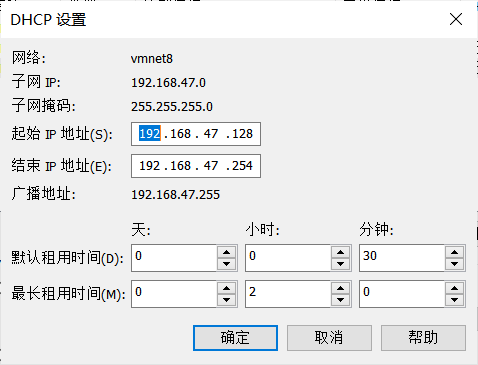
然后点击当前虚拟机下的网络编辑器,【编辑->虚拟网络编辑器】,选择NAT模式下的VMnet8网络,点击【DHCP配置】
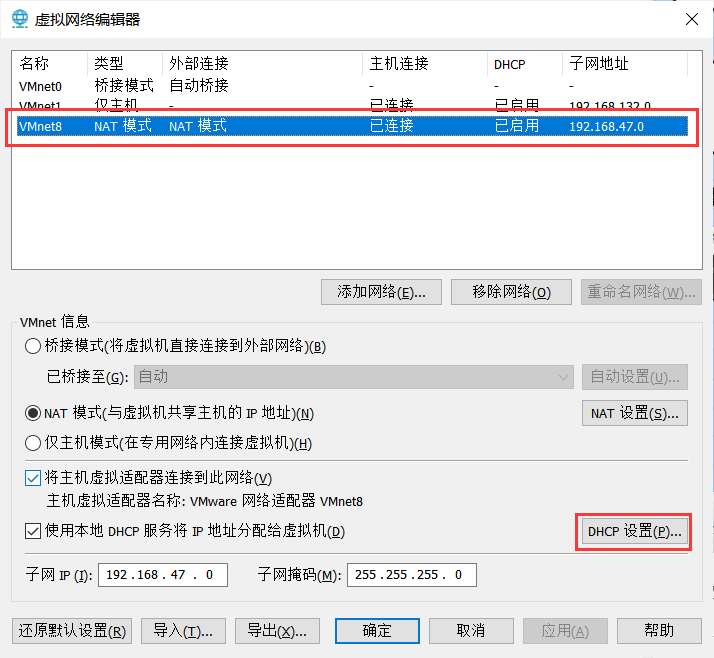
这里的起始和结束地址就是虚拟机的公用地址范围,可以默认将【192.168.XX.131】记下来作为hadoop1的ip地址,如我这里就是【192.168.47.131】。
修改网络配置文件
进入网络配置文件,修改之
1 | |
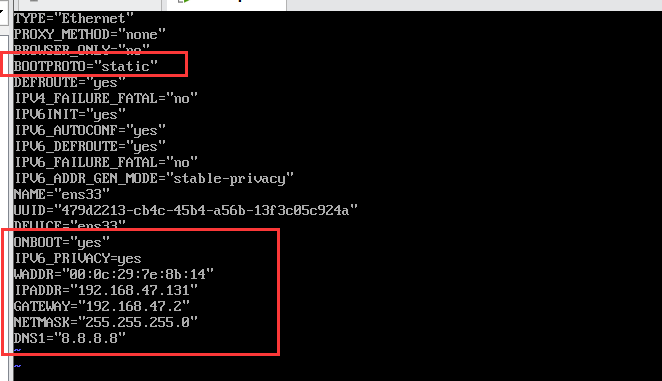
修改BOOTPROTO的镜像模式为”static”,若ONBOOT为=”no”则修改为”yes”,然后在配置文件后加入下面的配置信息
1 | |
重启网络和系统,然后查看是否配置成功
1 | |
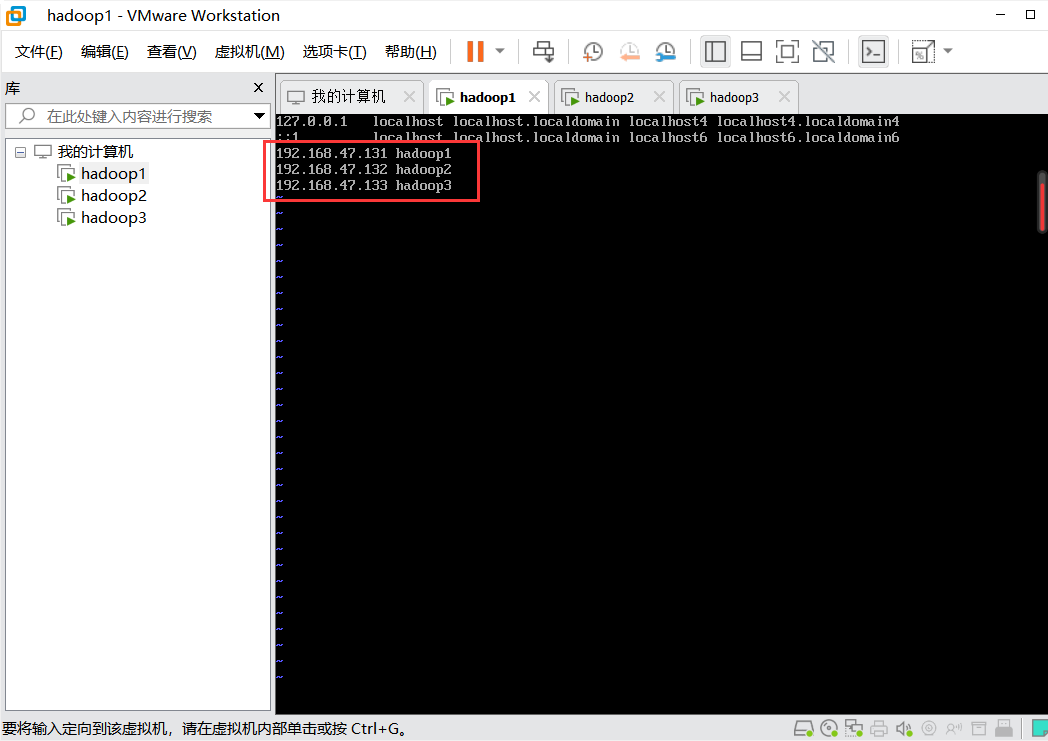
虚拟机克隆
完成单个虚拟机的配置之后,将虚拟机克隆两次,并另外命名为hadoop2和hadoop3,作为数据节点。
克隆
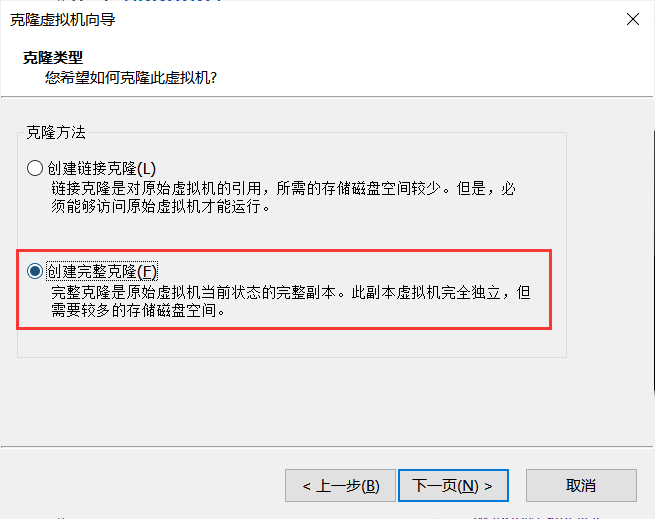
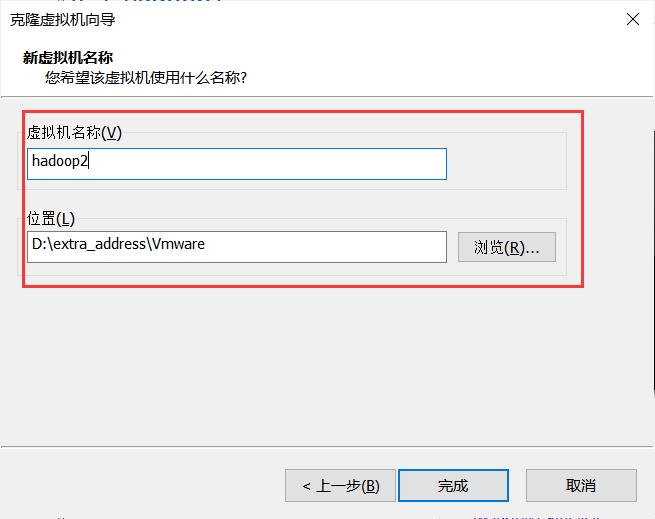
右键hadoop1虚拟机,【管理->克隆】,注意创建完整克隆
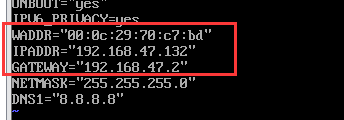
二次地址配置
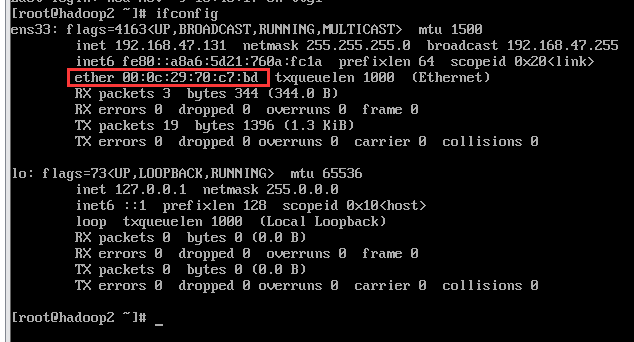
完成克隆之后,需要按照第一个虚拟机的方法再次进行两次地址配置,这里不再赘述过程,放出来图片供大家参考
1 | |
1 | |
1 | |

免密登录
为了以免之后主机链接客机的时候每次都得填密码(那会累死的),设置一下ssh的免密登录。
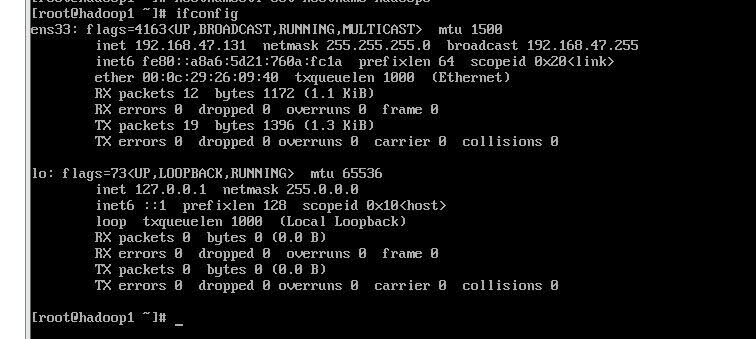
修改hosts文件
首先修改hosts文件的配置,将主机和客机都加进去
1 | |
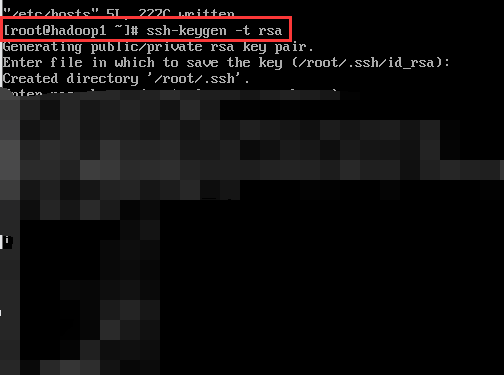
生成密钥文件
1 | |
回车三次即可,如果是已有密钥文件,回车四次。
复制密钥
将本机公钥文件复制到其它虚拟机上(接收方需先开机),在三个主机上都需要分别输入下列复制文件,保证三台主机都能够免密登录。
1 | |
使用ssh指令测试一下是否成功
1 | |

安装Hadoop和JDK
首先在每个主机下创建三个文件夹,data用于存数据、servers用于存储服务器配置、software用于存储软件包等。
1 | |
下载安装包
推荐使用更为稳定的hadoop-2.7.4版本和jdk8。
hadoop-2.7.4.tar.gz :Apache Hadoop
jdk-8u161-linux-x64.tar.gz :Java Archive Downloads - Java SE 8 (oracle.com)
安装Xshell
安装Xshell软件,这个软件能够方便的进行多主机协同,相对于虚拟机在UI和功能上更为友好。
家庭/学校免费 - NetSarang Website (xshell.com),直接用免费的就好,然后和普通软件一样下一步*n。
配置Xshell中的节点环境
打开Xshell后点击文件并选择新建,名称填hadoop1,主机填写hadoop1的IP地址。
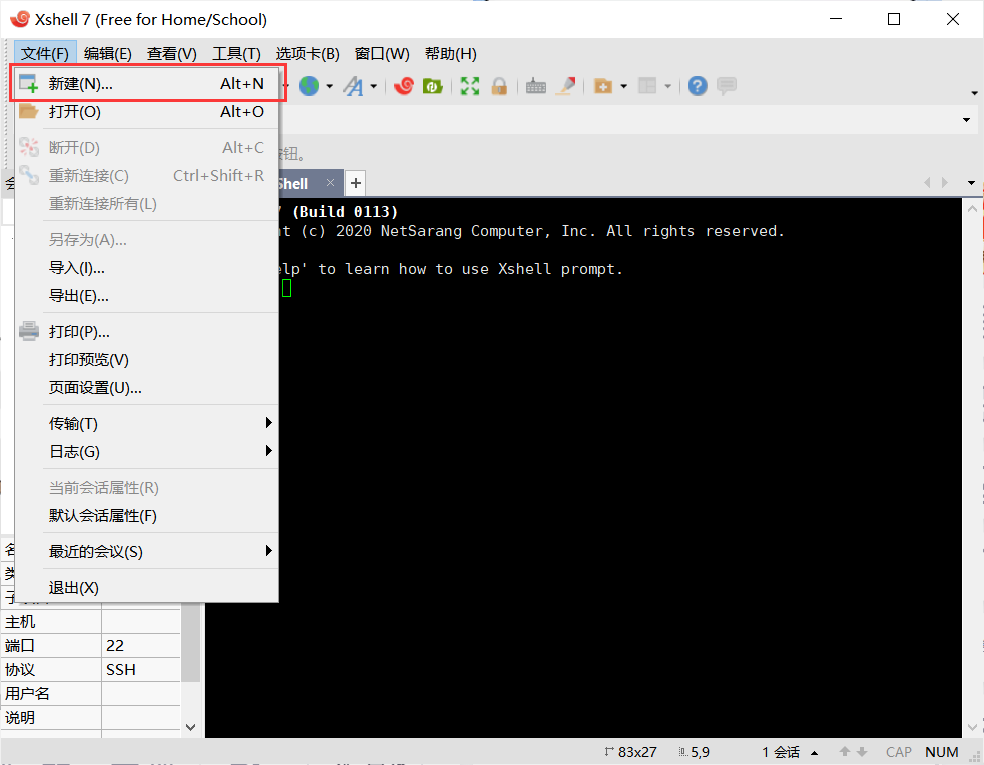
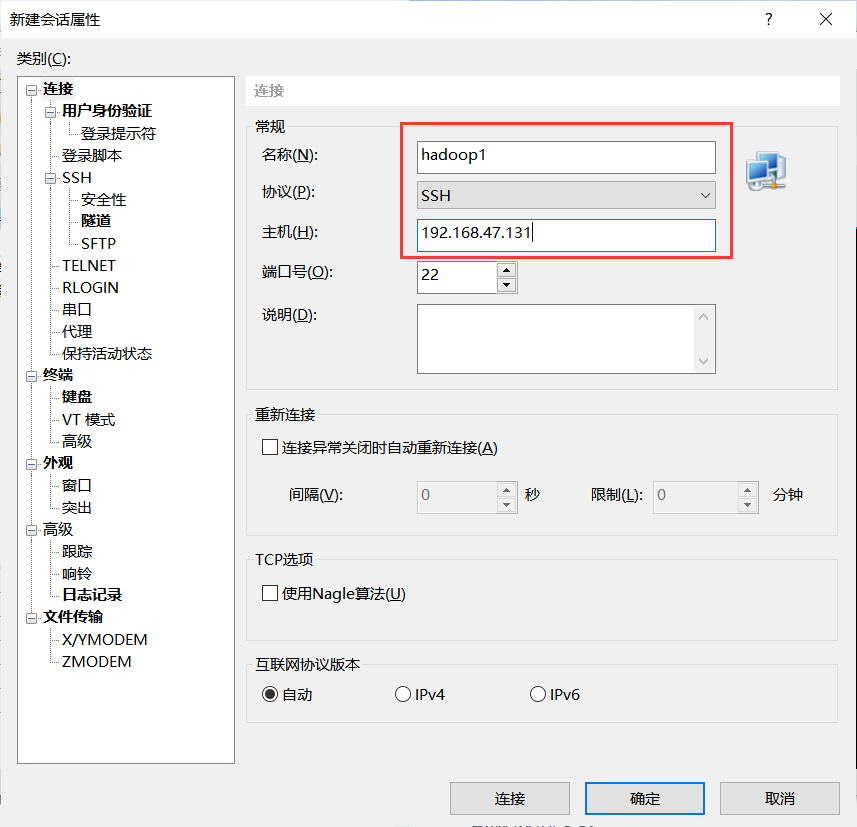
再点击用户身份验证,把hadoop1的账号,密码输入,就可以通过Xshell控制虚拟机,方便后续软件的传输。
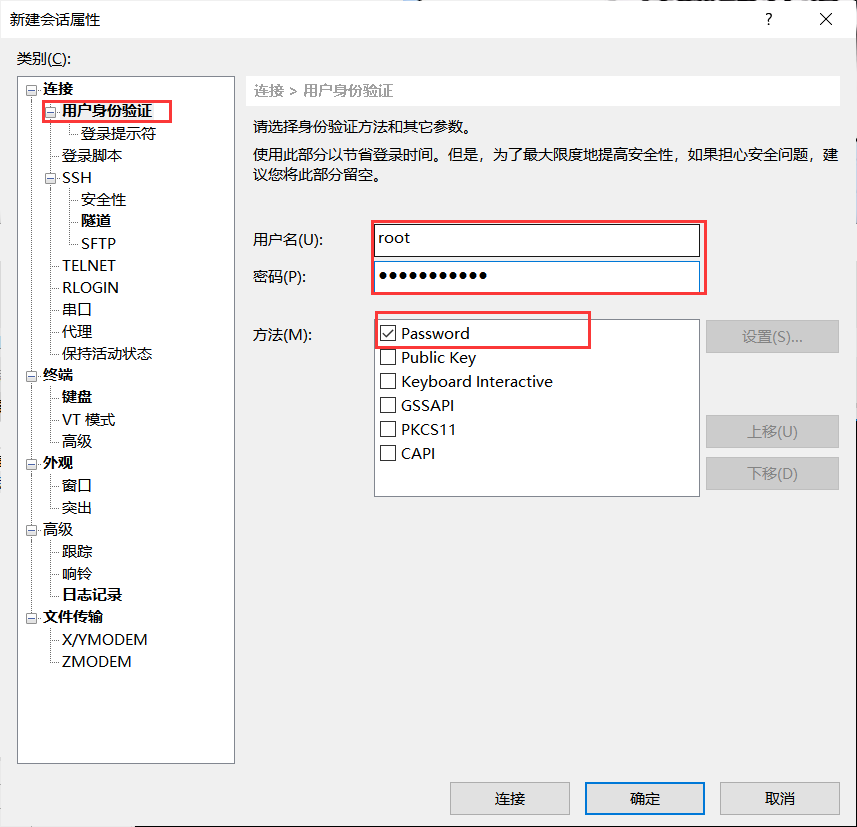
重复步骤新建会话控制hadoop2,hadoop3。
上传文件(以hadoop1为例)
安装一个插件方便上传文件,提供资源管理器的UI
1 | |
rz指令之后会进入资源管理器,将hadoop文件和jdk文件上传到系统中
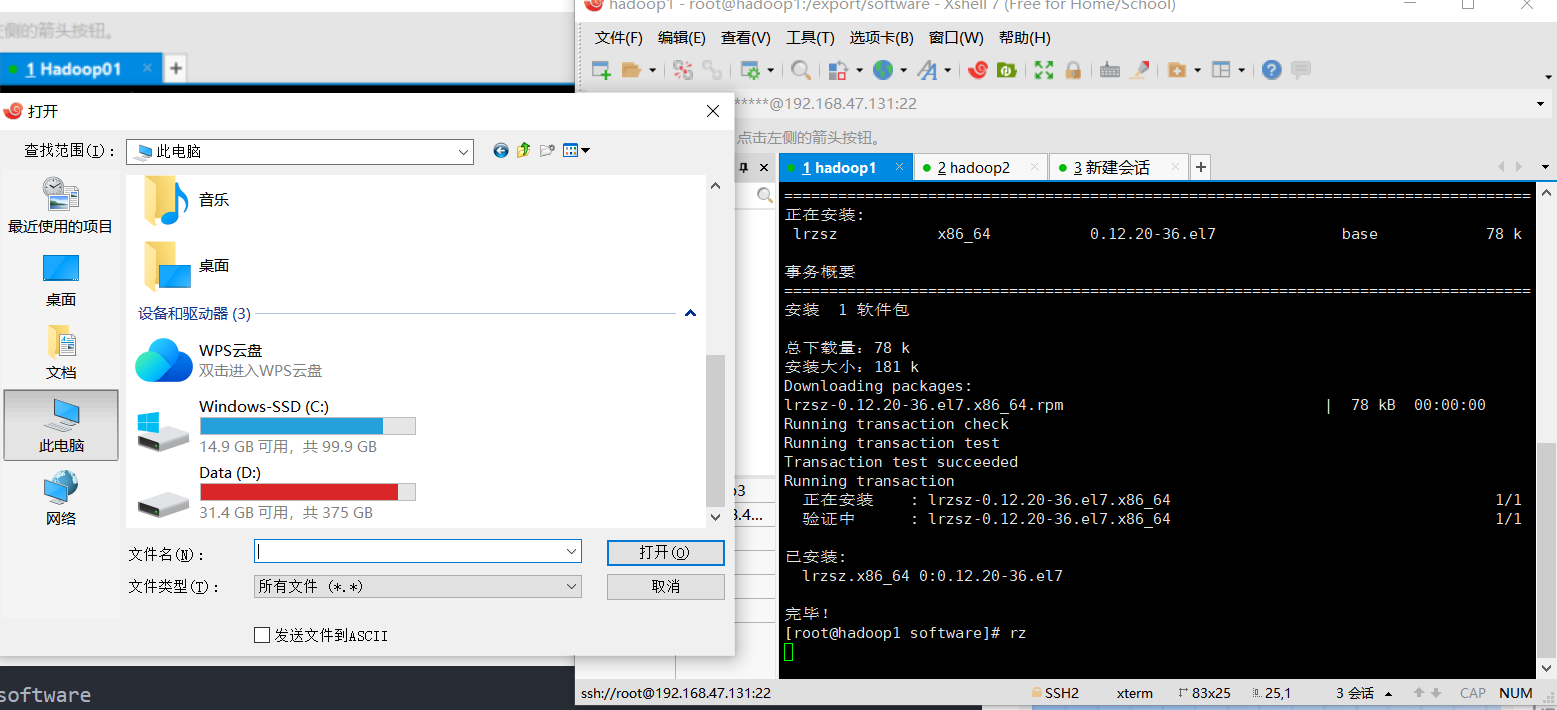
之后解压hadoop和jdk的压缩包到software文件夹下。
1 | |
软件配置(以hadoop1为例)
将hadoop和jdk的配置信息加到全局配置中
1 | |
1 | |
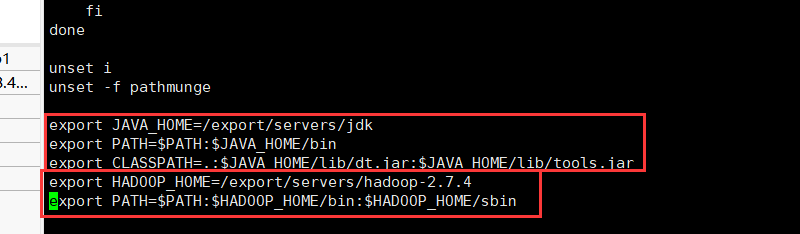
更新配置文件使之生效
1 | |
这样就完成了两个软件的配置,可以分别使用java -version和hadoop version查看是否成功安装。

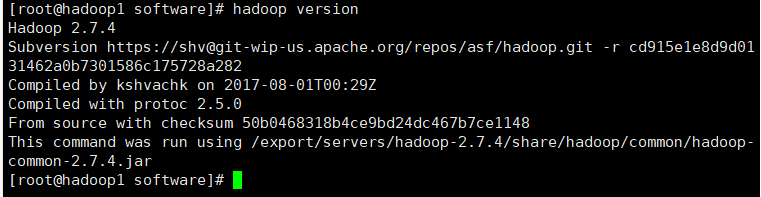
上述两个小步骤需要在hadoop2和hadoop3分别完成。
Hadoop集群配置
(vi编辑器:i为编辑模式,esc为退出编辑模式,:wq为保存并退出)
首先进入主节点hadoop1的配置目录
1 | |
java地址配置
修改hadoop中对于java环境地址的配置
1 | |
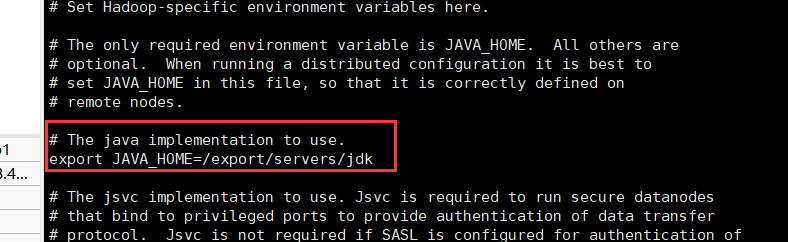
核心配置文件
修改core-site.xml文件
1 | |
1 | |
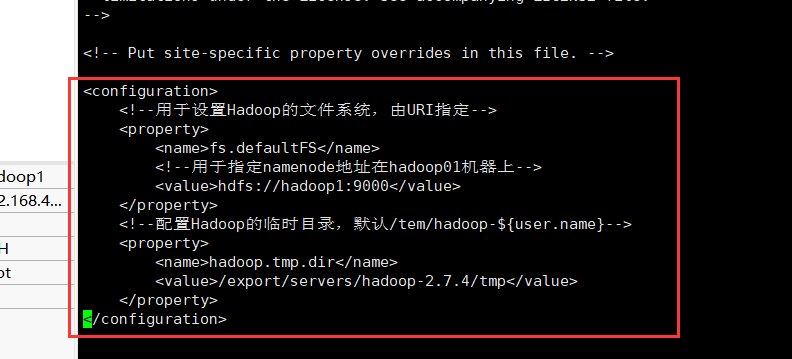
修改hdfs-site.xml文件,其中hdfs的每个部分的含义可以参见以下链接。
hadoop配置文件详解系列(二)-hdfs-site.xml篇 - 程序员姜小白 - 博客园 (cnblogs.com)
1 | |
1 | |
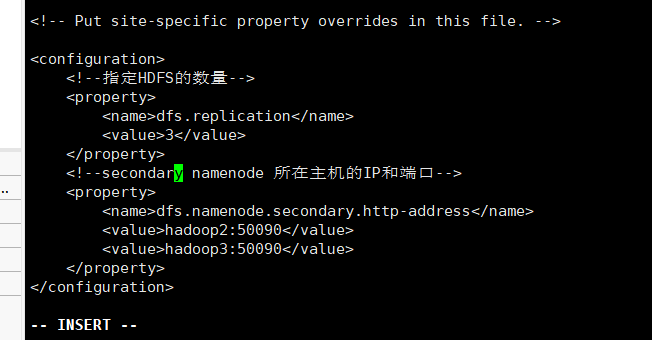
附属配置文件
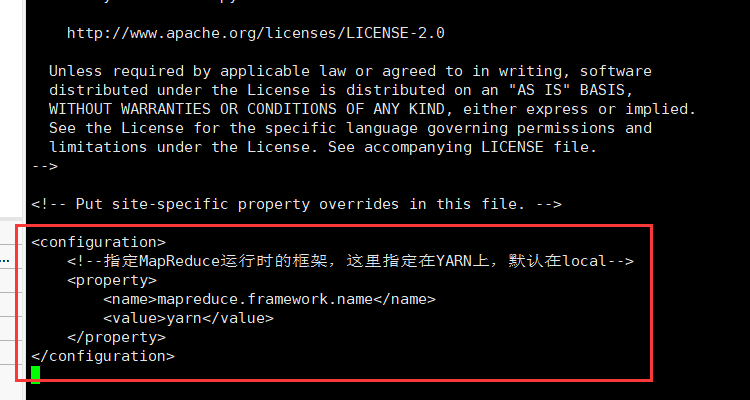
修改mapred-site.xml文件。
1 | |
1 | |
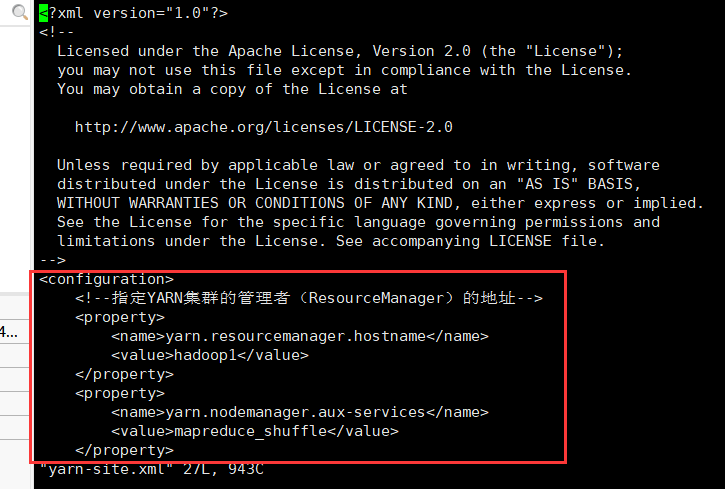
修改yarn-site.xml文件
1 | |
1 | |
节点配置
修改slaves文件
1 | |
复制配置到子结点
将主节点中配置好的文件和hadoop目录copy给子节点,其中主节点为hadoop1,子结点为hadoop2和hadoop3。
1 | |
去到hadoop2和hadoop3主机中,使新传过来的配置信息生效
1 | |
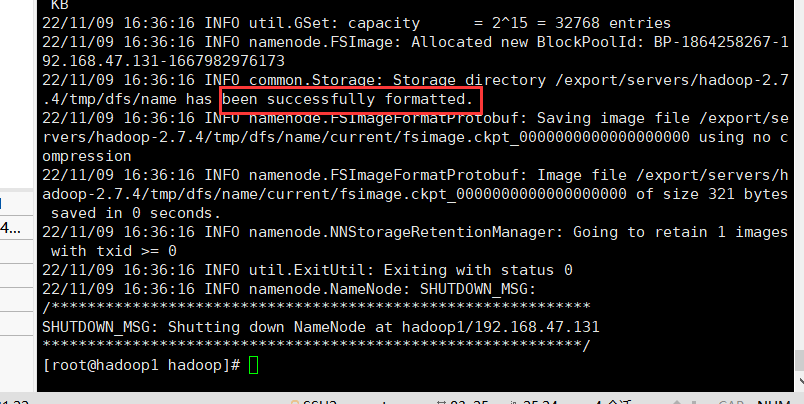
格式化文件系统
在主节点格式化文件系统,初始化hadoop的文件系统配置。如图片中的红框,给出【successfully formatted】即代表已经成功格式化文件系统。
1 | |
集群启动
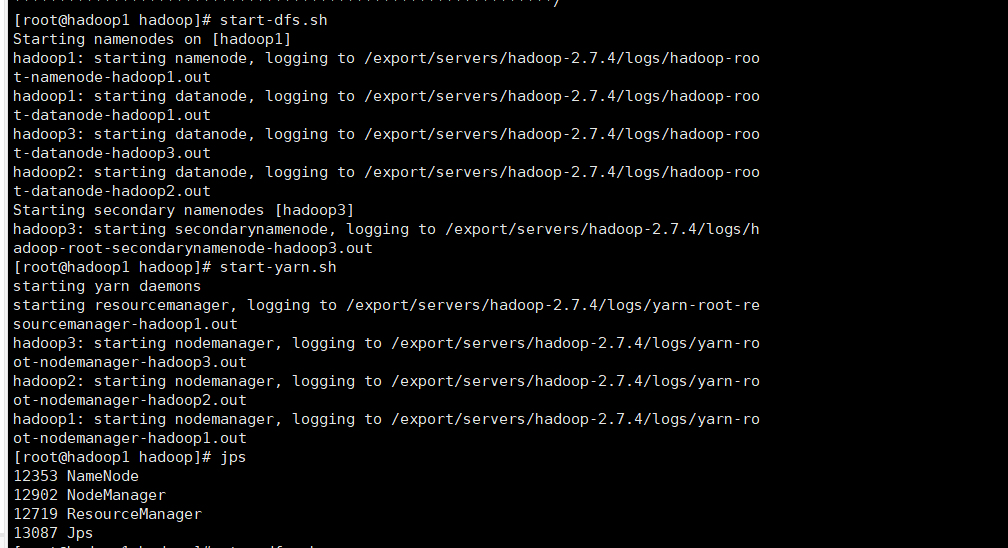
启动进程
在主节点启动dfs和yarn服务进程
1 | |
在主节点会显示ResourceManager(Yarn)、Namenode(主节点)、NodeManager(Hadoop)、在次主节点会显示SecondaryNamenode。
关闭进程可以使用stop进程
1 | |
关闭防火墙(所有虚拟机都要操作)
1 | |
本次配置
打开window下的【C:\Windows\System32\drivers\etc】,以管理员权限打开hosts文件,在文件末添加三行代码:
1 | |
在windows系统下访问http://hadoop1:50070,即可查看hdfs集群状态;访问http://hadoop1:8088,查看Yarn集群状态。
这样就完成了整个hadoop文件系统的配置,个人觉得比较麻烦,需要一步步很细节的去完成。