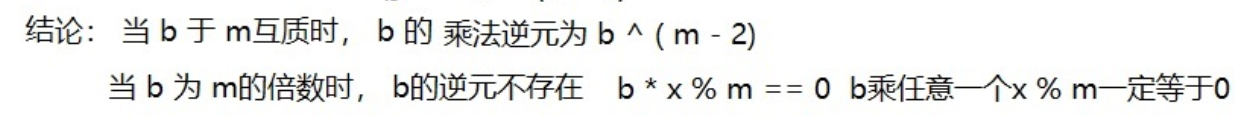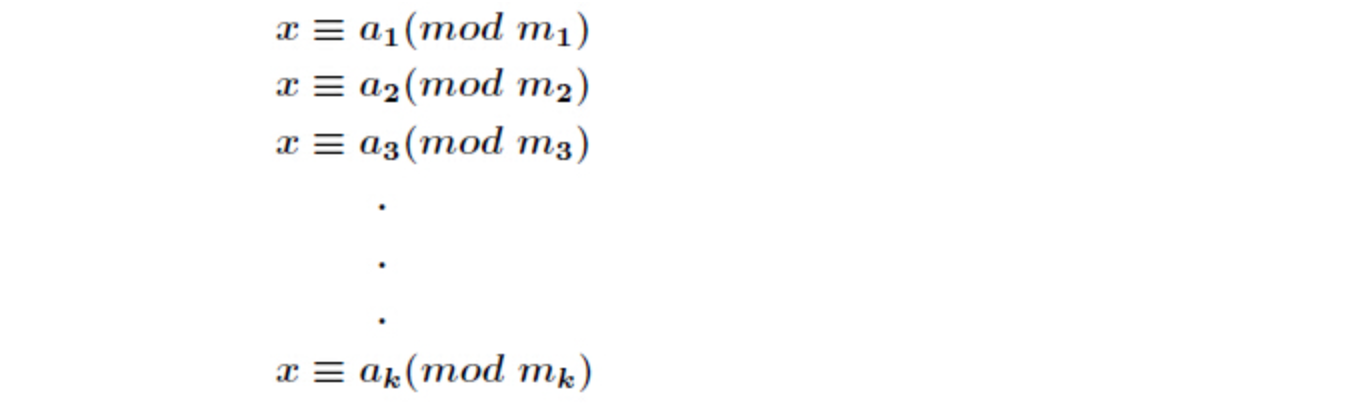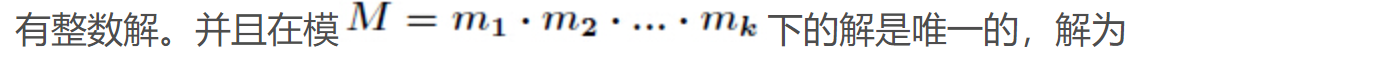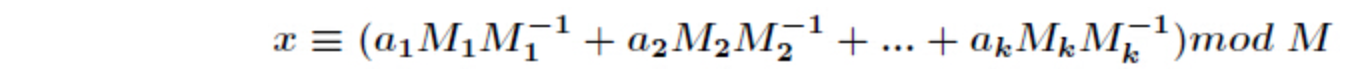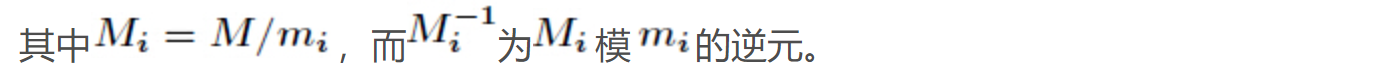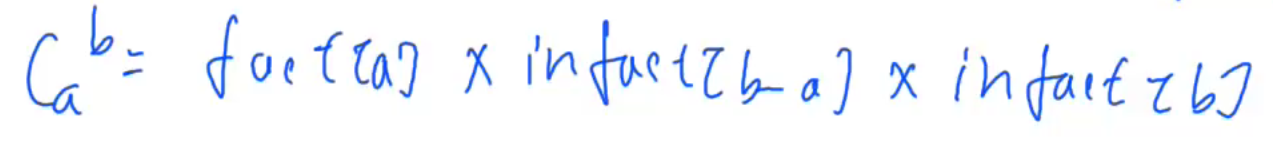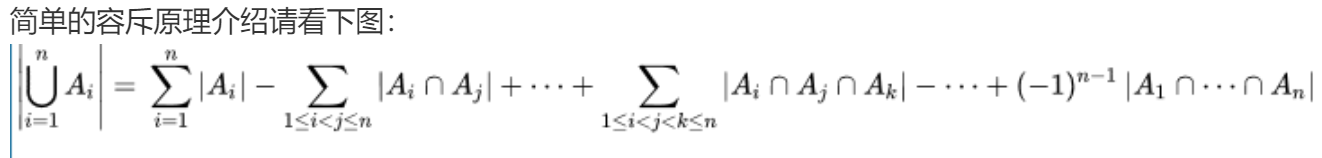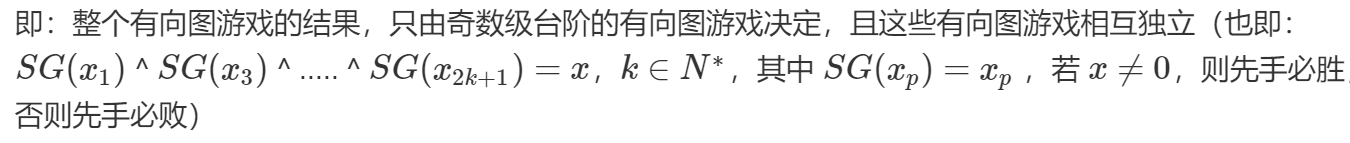本文最后更新于:几秒前
SF 1、数组越界;2、数组开小了
快速排序 1、特判
2、取l,r为端点外边
3、循环(l<r),使用do-while
4、递归调用,其中使用最后的r作为分割点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void quicksort (int num[],int left,int right) if (left >= right)return ;int l = left-1 ;int r = right+1 ;int t = num[(left+right-1 )/2 ];while (l < r){do l++; while (num[l] < t);do r--; while (num[r] > t);if (l < r){int tmp = num[l];quicksort (num,left,r);quicksort (num,r+1 ,right);
归并排序 1、特判
2、先对两边sort
3、再对两边循环,merge
4、如果两段中有未完成循环的接到最后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void mergesort (int num[],int l,int r) if (l >= r)return ;int m = (l+r)/2 ;int tmp[r-l+1 ];mergesort (num,l,m); mergesort (num,m+1 ,r);int i = l;int j = m+1 ;int k = 0 ;while (i <= m&&j <= r){if (num[i] < num[j]){else {while (i <= m){while (j <= r){0 ;for (int a = l;a <= r;a++){
二分排序 1、确定判断条件:如小于等于k的最大值
2、while(l<r){
int m = (l+r+1)/2; //取中点 ,如果有l=m则需取上分界
//小于等于:<=
if(f[m] <= k) l = m; //判断条件:我们需要找到最大值 ,因此需要尽量往右推,因为等于k的时候满足条件,所以右推的时候是l = m,不去除m对应的点防止丢失
else r = m+1;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 int divide_right (int num[],int q,int l,int r) while (l < r){int m = (l+r+1 )/2 ;if (num[m] <= q) l = m;else r = m-1 ;if (num[l] != q)return -1 ;return l;
浮点数二分 1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> using namespace std;int main () double n;cin >> n;double l = -10000 ;double r = 10000 ;while (r-l > 1e-8 ){ double m = (l+r)/2 ;if (m * m * m >= n)r = m; else l = m;printf ("%1f" ,l);return 0 ;
高精度计算(记成所有方法都要去除前导零) 加法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 首先**倒序**将各个数字存到vector里(使用a[i]-'0' )vector<int > add (vector<int > a,vector<int > b) {int > r;int c = 0 ;int i = 0 ;while (i < a.size () || i < b.size ()){if (i < a.size ()) c+=a[i];if (i < b.size ()) c+=b[i];push_back (c%10 );10 ;i++;if (c) r.push_back (c);return r;
减法: 减法我觉得有一些些恶心
首先,减法的操作是用大数减小数,所以首先要判断一个两个数的大小
1 2 3 4 5 6 7 8 9 10 11 bool cmp (vector<int >a, vector<int > b) if (a.size () != b.size ()) return a.size () >= b.size ();else {for (int i = a.size ()-1 ;i >= 0 ;i--){if (a[i] != b[i])return a[i] > b[i];return true ;
然后进行减法操作,操作如下:
1、设置一个t存储当前的借位,默认为0;
2、对两个序列a,b进行操作,注意借位
1 2 3 4 5 6 7 8 9 10 11 12 13 a-t-b,然后(t+10 )%10 判断是否借位for (int i = 0 ;i < a.size ();i++){if (i < b.size ()) t -= b[i];push_back ((t+10 )%10 );if (t<0 ) t = 1 ;else t = 0 ;
3、去除前导0
1 while (r.size ()>1 && r.back ()==0 ) r.pop_back ();
乘法 乘法的思路相对简单一些:
1、首先读入的值是一个vector和一个int,vector存高精度数
2、迭代的时候需要多迭代一次,即从0-size,因为到i==size的时候t可能有数字(超过现在的位数)
思路:如果i<size,则当前位为(a[i]*b+t)%10,进位为(a[i] * b+t)/10;
3、去除前导零
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 for (int i = 0 ;i <= a.size ();i++){if (i < a.size ()){push_back ((a[i]*b+t) % 10 );10 ;else {push_back (t);0 ;while (r.size () > 1 && r.back () == 0 )r.pop_back ();return r;int t = 0 ;for (int i = 0 ;i <= a.size ();i++){if (i < a.size ()){push_back ((a[i]*b+t)%10 );10 ;else {push_back (t);0 ;while (r.size () > 1 &&r.back ()==0 )r.pop_back ();
除法 与前面不同,除法操作是从高位开始的, 所以读入时需要注意从高位开始压入
存余数的话可以使用一个地址变量不断更新
除法的算法如下:
1、获取当前被除数值的大小 t = r*10+a[i];
2、获取结果与余数
结果 res.push_back(t / b);
余数 r = t%b;
使用int &r将余数返回到主函数
3、倒转结果
4、去除前导零
1 2 3 4 5 6 7 8 9 10 11 12 vector<int > div (vector<int > a,int b,int &r) {int > res;0 ;for (int i = 0 ;i < a.size ();i++){int t = r*10 +a[i];push_back (t/b);reverse (res.begin (),res.end ());while (res.size () > 1 &&res.back () == 0 )res.pop_back ();return res;
前缀和 一维前缀和 s[i] = a[i] + s[i-1]从1开始
求解[l,r] :s[r]-s[l-1] //注意是l-1
二维前缀和 s[i,j] = s[i,j-1]+s[i-1,j] - s[i,j]+a[i,j];
求解[x1,y1] -> [x2,y2] :s[x2,y2]-s[x1-1,y2]-s[x2,y1-1]+s[x1-1,y1-1] //注意x1-1,y1-1
差分 一维差分:求某一段的和 a[i] = s[i] - s[i-1];
求解在[l,r]范围+c:a[l] += c;a[r-1]-=c;
理解:对a[l]的操作在l之后的所有元素都产生影响
二维差分 1 2 3 4 5 6 void inv (int x1,int y1,int x2,int y2,int w) 1 ][y1] -= w;1 ] -= w;1 ][y2+1 ] += w;
步骤:
1、输入
2、inv(i,j,i,j,s[i,j]);
3、inv(x1,y1,x2,y2,w);
4、求和:a[i,j] += a[i,j-1]+a[i-1,j]-a[i-1,j-1];
双指针算法 板子:
1 2 3 4 5 6 7 8 9 for (int i = a,j = b;i <= n;i++){while (c[f[i]] > 1 ){
最长不连续子序列 快慢指针法:i指向右端点,j指向左端点
1 2 3 4 5 6 7 for (int i = 1 ,j = 1 ;i <= n;i++){while (c[f[i]] > 1 ){max (r,i-j+1 );
数组元素的目标和 1 2 3 4 5 6 7 for (int i = 1 ,j = m-1 ;i <= n;i++){while (a[i]+b[j] > x) j--;if (a[i] + b[j] == x){" " << j;break ;
判断子序列 1 2 3 4 5 6 for (int i = 1 ,j = 1 ;i <= n;i++){while (a[i] != b[j] && j<=m) j++;if (j <= m) {
离散化 理解:将x,l,r单独压入一个vector,访问时只使用vector中的下标进行访问
如何找到对应index:使用二分查找
1、排序,模拟数轴
2、去重 all.erase(unique(all.begin(),all.end()),all.end());
1 2 3 sort (all.begin (),all.end ());erase (unique (all.begin (),all.end ()),all.end ());
3、对原位置的操作换成对二分之后的位置的操作
4、前缀
区间合并 1、按左边排序
2、两种判断情况:包含与交叉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vector<PII> merge (vector<PII> &a) {sort (a.begin (),a.end ());int l = -2e9 ;int r = -2e9 ;for (auto item:a){if (r < item.first){if (l != -2e9 )res.push_back ({l,r});else r = max (r,item.second);if (l != -2e9 )res.push_back ({l,r});return res;
链表 单链表 e[idx] = b;ne[idx] = h[a];h[a] = idx++;
删除:ne[k] = ne[ne[k]];
双链表 初始化:r[0] = 1;r[1] = 0;idx=2;
传入左节点地址k和值x
e[idx] = x;r[idx] = r[k];l[idx] = k;l[r[k]] = idx;r[k] = idx;
删除中间结点k
r[l[k]] = r[k];
l[r[k]] = l[k];
艾海舟,孙立峰,袁春
模拟线性表 栈 数组模拟,top指针,从数组高位操作
表达式求值 1、建表
2、建计算
1 2 3 4 5 6 7 8 9 10 11 12 void eval () char c = operators.top ();operators.pop ();int b = operant.top ();operant.pop ();int a = operant.top ();operant.pop ();switch (c){case '+' : operant.push (a+b);break ;case '-' : operant.push (a-b);break ;case '*' : operant.push (a*b);break ;case '/' : operant.push (a/b);break ;default :break ;
3、判断条件
①是数值 ②是左括号 ③是右括号 ④判断是否需要计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if (isdigit (s[i])){int t = 0 ;while (isdigit (s[i])){10 +s[i]-'0' ;i++;push (t);else if (s[i] == '(' )operators.push ('(' );else if (s[i] == ')' ){while (operators.top () != '(' ){eval ();pop ();else {while (operators.size () && p[operators.top ()] >= p[s[i]]) eval ();push (s[i]);
队列 数组模拟,双指针,从数组高位操作push,低位操作pop
单调栈与单调队列 单调栈:判断栈顶是否大于当前值即可
给定一个长度为 N 的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出 −1。 滑动窗口 注意!!!这道题用数组的单调队列 做
对于每次操作的算法 :
1、判断fr对应的值是否已经出栈
2、判断栈尾的值是否大于当前值,如果大于则栈尾的值一定不是最小值,出栈
3、将当前值压栈
4、输出栈顶值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for (int i = 0 ;i < n;i++){if (fr <= rr && q[fr] < i-m+1 ) fr++;while (fr <= rr && f[q[rr]] >= f[i]) {if (i >= m-1 ) cout << f[q[fr]] << " " ;for (int i = 0 ;i < n;i++){if (fr<=rr && q[fr]<i-m+1 )fr++;while (fr<=rr && f[q[rr]]>=f[i]) rr--;if (i > m)cout << f[q[fr]] << " " ;
KMP 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cin >> m >> p+1 >> n >> s+1 ;for (int i = 2 ,j = 0 ;i <= n;i++){while (j && p[i] != p[j+1 ]) j = ne[j];if (p[i] == p[j+1 ])j++;for (int i = 1 ,j = 0 ;i <= n;i++){while (j && s[i] != p[j+1 ]) j = ne[j];if (s[i] == p[j+1 ])j++;if (j == m){" " ;
Trie //原理:使用一棵树来存储字符串
使用son[N,26]存储树,cnt[N]数组存每个位置的计数,对应不同的字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int cnt[N],son[N][26 ],idx;void insert (char s[]) int p = 0 ;for (int i=0 ;s[i];i++){int t = s[i]-'a' ;if (!son[p][t]) son[p][t]=++idx;int query (char s[]) int p = 0 ;for (int i=0 ;s[i];i++){int t = s[i] - 'a' ;if (!son[p][t]) return 0 ;return cnt[p];void query (char s[]) int p = 0 ;for (int i = 0 ;s[i];i++){int t = s[i]-'a' ;if (!son[p][t])return 0 ;return cnt[p];
最大异或对 原理:下溯的时候溯与当前位相反的数(保证异或最大)
注意:建树的时候从高到低
1 2 3 4 5 6 7 8 9 10 11 12 int query (int s) int r = 0 ,p = 0 ;for (int i = 30 ;i >= 0 ;i--){int t = s >> i & 1 ;if (son[p][!t]){1 << i;else p = son[p][t];return r;
并查集*** 并查集可以用来进行集合处理
合并集合 1、首先将每个数做成一个集合
2、合并的时候将p[a] = b;
三种操作:注意这里找父节点用的是find函数 p[find[a]] = find[b] find[a] == find[b] p[a] = find(p[a])
并查集操作:
1 2 3 4 5 int find (int x) if (p[x] != x) p[x] = find (p[x]);return p[x];
连通块中点的数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (s[0 ] == 'C' ){if (find (a) != find (b)){find (b)] += cnt[find (a)];find (a)] = find (b); else if (s[1 ] == '1' ){if (find (a)==find (b)) cout << "Yes" << endl;else cout << "No" << endl;else if (s[1 ] == '2' ){find (a)] << endl;
模拟堆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 if (!strcmp (op,"I" )){int t;scanf ("%d" , &t);up (s);else if (!strcmp (op,"PM" )){1 ] << endl;else if (!strcmp (op,"DM" )){heap_swap (1 ,s);down (1 );void up (int x) while (x/2 > 0 && h[x/2 ] > h[x]) swap (h[x/2 ],h[x]);2 ;void down (int x) int t = x;if (2 *x<=s && h[2 *x] < h[t]) t = 2 *x;if (2 *x+1 <=s&& h[2 *x+1 ] < h[t]) t = 2 *x+1 ;if (t != x){heap_swap (t,x);down (t);
模拟哈希 拉链法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 const int N = 100003 ;int h[N],e[N],ne[N],idx;void insert (int x) int k = (x%N+N)%N;int find (int x) int k = (x%N+N)%N;for (int i = h[k];i != -1 ;i = ne[i]){if (e[i] == x) return 1 ;return 0 ;int main () -1 int k = (x%N+N)%N;memset (h,-1 ,sizeof h);
字符串哈希
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 const int N = 100010 ;const int P = 131 ;typedef unsigned long long ULL; int h[N],p[N];ULL get (int l,int r) {return h[r] - h[l-1 ] * p[r-l+1 ];int main () 0 ] = 0 ;p[0 ] = 1 ;for (int i = 1 ;i <= n;i++) {-1 ] * P + str[i];-1 ] * P;while (m--){int l1,r1,l2,r2;if (get (l1,r1) == get (l2,r2)) cout << "Yes" << endl;else cout << "No" << endl;return 0 ;
DFS 排列数字 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int n,s[N],p[N];void DFS (int u) if (u > n){for (int i = 1 ;i <= n;i++){" " ;for (int i = 1 ;i <= n;i++){if (s[i] == 0 ){DFS (u+1 );0 ;0 ;int main () DFS (1 );return 0 ;
N皇后 只记迭代每个位置的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void DFS (int r,int c,int t) if (c > n){1 ;if (r > n){if (t == n){for (int i = 1 ;i <= n;i++){for (int j = 1 ;j <= n;j++){return ;DFS (r,c+1 ,t);if (!row[r] && !col[c] && !dg[r+c] && !udg[c-r+n]){1 ;'Q' ;DFS (r,c+1 ,t+1 );0 ;'.' ;
BFS 走迷宫 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <iostream> #include <queue> #include <cstring> #include <unordered_map> using namespace std;const int N = 110 ,M = 110 ;typedef pair<int ,int > MM;int n,m;int h[N][M];int d[N][M];int dx[4 ]={0 ,-1 ,0 ,1 };int dy[4 ]={1 ,0 ,-1 ,0 };void BFS () memset (d,-1 ,sizeof d);1 ][1 ]=0 ;while (!q.empty ()){int x = q.front ().first;int y = q.front ().second;pop ();if (x == n && y == m){break ;else {for (int i = 0 ;i < 4 ;i++){int px = x+dx[i];int py = y+dy[i];if (px > 0 && px <= n && py > 0 && py <= m && h[px][py] != 1 && d[px][py]== -1 ){1 ;push ({px,py});int main () for (int i = 1 ;i <= n;i++){for (int j = 1 ;j <= m;j++){push ({1 ,1 });BFS ();return 0 ;
八数码 特征:矩阵移动性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 void bfs (string s) "12345678x" ;push (s);0 ;int dx[4 ] = {1 ,-1 ,0 ,0 };int dy[4 ] = {0 ,0 ,1 ,-1 };while (!q.empty ()){、front ();pop ();int dt = d[t];if (t == e) {break ;int xx = t.find ('x' );int tx = xx / 3 ;int ty = xx % 3 ;for (int i = 0 ;i < 4 ;i++){int px = tx + dx[i];int py = ty + dy[i];if (px >= 0 && px < 3 && py >= 0 && py < 3 ){int dp = d[t]+1 ;swap (t[px*3 +py],t[xx]);if (!d.count (t)){push (t);swap (t[px*3 +py],t[xx]);if (d.count (e)) cout << d[e];else cout << -1 ;
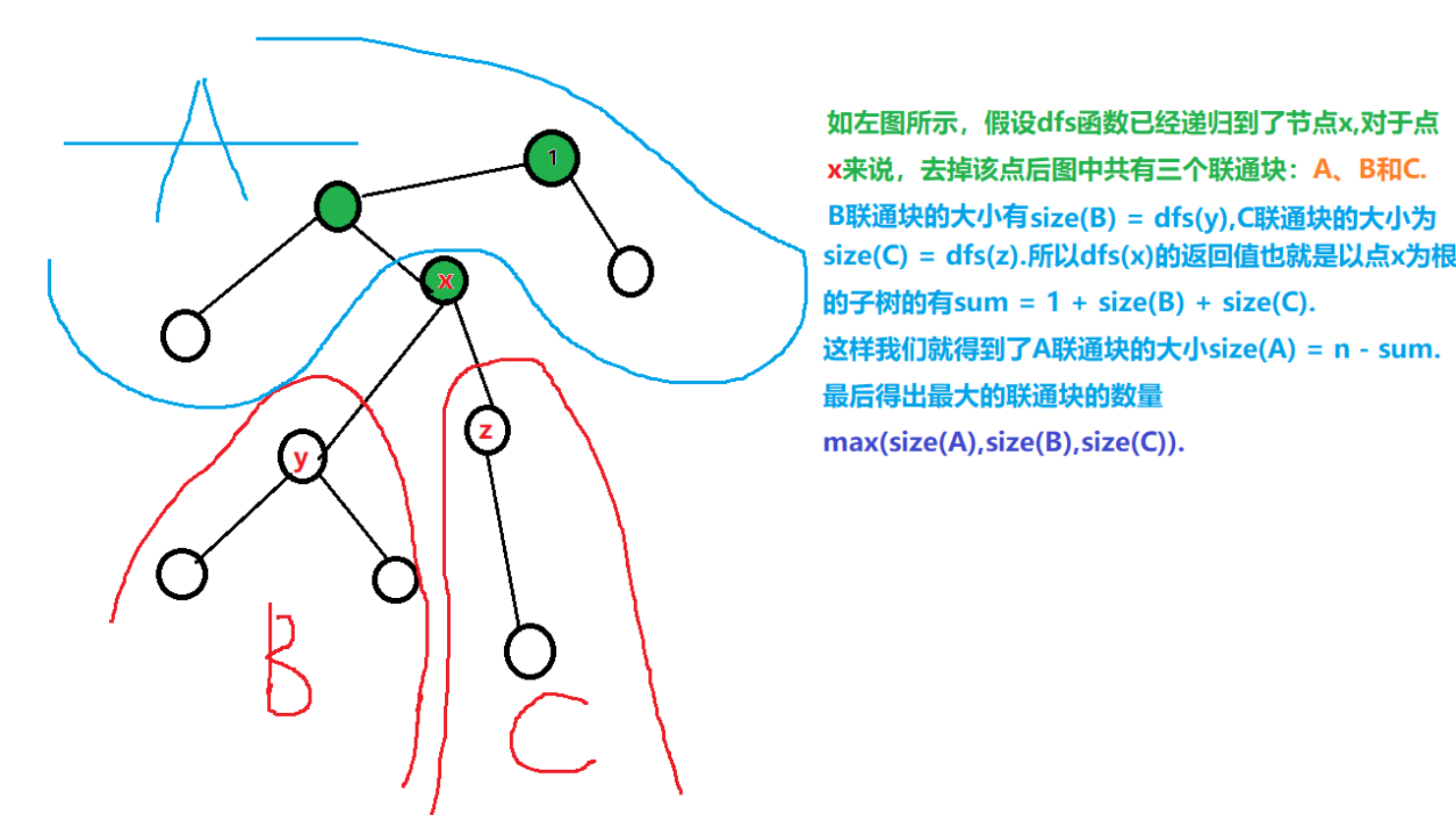
树与图的深度优先遍历 树的重心
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int dfs (int u) int res = 0 ; true ; int sum = 1 ; for (int i = h[u]; i != -1 ; i = ne[i]) {int j = e[i];if (!st[j]) {int s = dfs (j); max (res, s); max (res, n - sum); min (res, ans); return sum;
树与图的广度优先遍历 图中点的层次 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void bfs () memset (d,-1 ,sizeof d);1 ] = 0 ;push (1 );while (q.size ()){int t = q.front ();pop ();for (int i = h[t];i != -1 ;i = ne[i]){if (d[e[i]] == -1 ){1 ;push (e[i]);if (t == n){return ;-1 ;
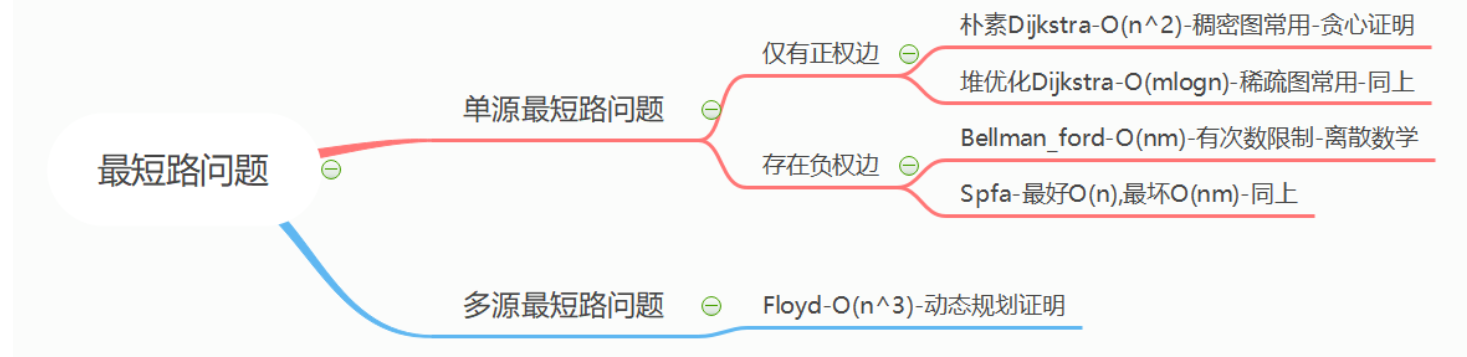
图的排序与最短路 拓扑排序
注意:图中可能存在重边和自环
策略:宽搜+入度计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 while (m--){int a,b;add (a,b);bool topsort () int count = 0 ;for (int i = 1 ;i <= n;i++){if (d[i] == 0 )q.push (i);while (q.size ()){int tmp = q.front ();pop ();count++;push_back (tmp);for (int i = h[tmp];i != -1 ;i = ne[i]){int link = e[i];if (d[link] == 0 )q.push (link);if (count == n)return true ;else return false ;
Dijkstra算法:非负权,有自环重边 Dijkstra 的整体思路比较清晰进行n(n为n的个数)次迭代 去确定每个点到起点的最小值 ,最后输出的终点的即为我们要找的最短路的距离
步骤
迭代n次,每次迭代都找到一个符合条件的点加入 ,确定一个点的最短路的值,符合的条件为:
1、没有被处理过(即没有加入当前的连通分量)
2、距离最短
找到j点之后将use数组置1,然后对于所有和j点相连的点更新最短路。
初始化memset时无限大是0x3f,memset是按字节填充 int 4 个字节,判断的时候所以是0x3f3f3f3f
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int g[N][N];int dist[N];int use[N];int n,m;int dijkstr () memset (dist,0x3f ,sizeof dist);memset (use,0 ,sizeof use);1 ] = 0 ;for (int i = 1 ;i <= n;i++){int t = -1 ;for (int j = 1 ;j <= n;j++){if (!use[j] && (t == -1 || dist[t] > dist[j])) t = j;1 ;for (int j = 1 ;j <= n;j++){if (dist[j] > dist[t]+g[t][j]){if (dist[n] != 0x3f3f3f3f ) return dist[n];return -1 ;int main () memset (g,0x3f ,sizeof g);int a,b,w;while (m--){min (g[a][b],w);int r = dijkstr ();return 0 ;
堆优化Dijkstra 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int disj () memset (dist,0x3f ,sizeof dist);push ({0 ,1 });while (!q.empty ()){auto t = q.top ();q.pop ();int d = t.first;int v = t.second;if (use[v])continue ;true ;for (int i = h[v];i != -1 ;i = ne[i]){int k = e[i];if (dist[k] > d+w[i]){push ({d+w[i],k});if (dist[n] == 0x3f3f3f3f ) return -1 ;return dist[n];
贝尔曼算法:含负权,有重边自环,图中可能 存在负权回路 。 步骤:
如果限制最短路上只有k条边,则最外层迭代k次,内层迭代m(边数)次,然后对每个边{a,b,w},判断dist[b] = min(dist[b],dist[a]+w),即松弛操作。
由于在代码中前面的操作可能会影响后面的操作,因此需要先保存上一次的处理结果,即对dist数组进行备份(注意语法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 struct edge {int a,b,w;int n,m,k;int dist[N],backup[N];int bellman_ford () memset (dist,0x3f ,sizeof dist);1 ] = 0 ;for (int i = 0 ;i < k;i++){memcpy (backup,dist,sizeof dist);for (int j = 0 ;j < m;j++){int a = e[j].a;int b = e[j].b;int w = e[j].w;min (dist[b],backup[a]+w);if (dist[n] > 0x3f3f3f3f /2 ) return 0x3f ;else return dist[n];int main () int i = 0 ;for (int i = 0 ;i < m;i++){int a,b,w;int r = bellman_ford ();if (r == 0x3f )cout << "impossible" ;else cout << r;return 0 ;
spfa算法:含负权,可能存在重边和自环,判断是否有负环 求最短路 spfa是根据贝尔曼算法所做的优化,Bellman_ford算法会遍历所有的边,但是有很多的边遍历了其实没有什么意义,我们只用遍历那些到源点距离变小的点所连接的边即可,只有当一个点的前驱结点更新了,该节点才会得到更新; 因此考虑到这一点,我们将创建一个队列每一次加入距离被更新的结点。
值得注意的是 1) st数组的作用: 判断当前的点是否已经加入到队列当中了;已经加入队列的结点就不需要反复的把该点加入到队列中了 ,就算此次还是会更新到源点的距离,那只用更新一下数值而不用加入到队列当中。即便不使用st数组最终也没有什么关系 ,但是使用的好处在于可以提升效率。
SPFA算法看上去和Dijstra算法长得有一些像但是其中的意义还是相差甚远的:
Dijkstra算法里使用的是优先队列保存的是当前未确定最小距离的点 ,目的是快速的取出当前到源点距离最小的点;SPFA算法中使用的是队列(你也可以使用别的数据结构) ,目的只是记录一下当前发生过更新的点。
⭐️Bellman_ford算法里最后return-1的判断条件写的是dist[n]>0x3f3f3f3f/2;而spfa算法写的是dist[n]==0x3f3f3f3f;其原因在于Bellman_ford算法会遍历所有的边,因此不管是不是和源点连通的边它都会得到更新; 但是SPFA算法不一样,它相当于采用了BFS,因此遍历到的结点都是与源点连通的,因此如果你要求的n和源点不连通,它不会得到更新,还是保持的0x3f3f3f3f。
⭐️ Bellman_ford算法可以存在负权回路,是因为其循环的次数是有限制的 因此最终不会发生死循环;但是SPFA算法不可以,由于用了队列来存储,只要发生了更新就会不断的入队,因此假如有负权回路请你不要用SPFA否则会死循环。
⭐️求负环一般使用SPFA算法 ,方法是用一个cnt数组记录每个点到源点的边数,一个点被更新一次就+1,一旦有点的边数达到了n那就证明存在了负环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int d[N],st[N];int > q;void add (int a,int b,int c) int spfa () memset (d,0x3f ,sizeof d);1 ]=0 ;push (1 );1 ] = 1 ;while (q.size ()){int t = q.front ();q.pop ();0 ;for (int i = h[t];i != -1 ;i = ne[i]){int et = e[i];int wt = w[i];if (d[et] > d[t]+wt){if (!st[et]){push (et);1 ;if (d[n] == 0x3f3f3f3f )return -1 ;return d[n];
求负环(最常用) 1、初始的时候将所有点入队,因为负权回路可能是从任意一个点开始
2、在更新点的时候设置一个cnt数组存储x点到虚拟源点最短路的边数 ,初始每个点到虚拟源点的距离为0,只要他能再走n步,即cnt[x] >= n,则表示该图中一定存在负环,由于从虚拟源点到x至少经过n条边时,则说明图中至少有n + 1个点,表示一定有点是重复使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int spfa () memset (d,0x3f ,sizeof d);1 ] = 0 ;for (int i = 1 ;i <= n;i++){push (i);st[i] = 1 ;while (q.size ()){int t = q.front ();q.pop ();0 ;for (int i = h[t];i != -1 ;i = ne[i]){int et = e[i];int wt = w[i];if (d[et] > d[t] + wt){1 ;if (!st[et]){push (et);1 ;if (cnt[et] >= n) return true ;return false ;
Floyd算法:多源最短路 三层循环,原理是dp
1 2 3 4 5 6 7 8 9 void floyd () for (int a = 1 ;a <= n;a++){for (int b = 1 ;b <= n;b++){for (int c = 1 ;c <= n;c++){min (d[b][c],d[b][a]+d[a][c]);
注意使用邻接矩阵处理含重边和自环的图时需要进行预处理
重边:d[a,b] = min(d[a,b],w)
自环(默认自环为0):d[a,a] = 0;
1 2 3 4 5 6 7 8 9 for (int i = 1 ; i <= n; i++)for (int j = 1 ; j <= n; j++)if (i == j) d[i][j] = 0 ;else d[i][j] = INF;while (m--) {min (d[x][y], z);
图的处理总结
最小生成树 prim算法 和dijkstra算法十分像。
联系:Dijkstra算法是更新到起始点的距离,Prim是更新到集合S的距离
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int prim () memset (d,0x3f ,sizeof d);1 ] = 0 ;int r = 0 ;for (int i = 0 ;i < n;i++){int t = -1 ;for (int j = 1 ;j <= n;j++){if (!st[j] && (t==-1 || d[t] > d[j])){if (d[t] == INF) return INF;1 ; for (int j = 1 ;j <= n;j++){min (d[j],g[t][j]);return r;
Kruskal算法 1、对边按照权值从小到大排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 int p[N];struct Edge {int a,b,w;bool cmp (const Edge& a,const Edge&b) return a.w < b.w;int find (int a) if (p[a]!=a) p[a] = find (p[a]);return p[a];for (int i = 1 ;i <= n;i++)p[i] = i;for (int i = 0 ;i < m;i++){int a,b,w;sort (e,e+m,cmp);for (int i = 0 ;i < m;i++){int a = e[i].a;int b = e[i].b;int w = e[i].w;if (find (a) != find (b)){find (a)] = find (b);if (cnt == n)cout << r;else cout << "impossible" ;
染色法判定二分图
遍历所有点,对于每个点为起点进行dfs。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 bool j = true ;for (int i = 1 ;i <= n;i++){if (!color[i]){if (!dfs (i,1 )) {false ;break ;bool dfs (int k,int c) for (int i = h[k];i!=-1 ;i = ne[i]){if (color[e[i]] == 0 ){if (!dfs (e[i],3 -c))return false ;else if (color[e[i]]==c)return false ;return true ;
匈牙利算法判断二分图的最大匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int g[N][N];int st[N];int match[N];bool find (int x) for (int i = 1 ;i <= n2;i++){if (!st[i] && g[x][i]){true ;if (!match[i] || find (match[i])){return true ;return false ;bool find (int a) for (int i = h[a];i != -1 ;i = ne[i]){int et = e[i];if (!st[et]){true ;if (!match[et] || find (match[et])){return true ;return false ;
质数求解 试除法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (m<2 ) {"No" << endl;continue ;for (int i = 2 ;i <= m/i;i++){if (m % i == 0 ){"No" << endl;0 ;break ;if (k)cout << "Yes" << endl;
筛质数 埃式筛法 1 2 3 4 5 6 7 8 9 10 11 12 int c= 0 ;for (int i = 2 ;i <= n;i++){if (!st[i]){for (int j = i;j <= n;j+=i){1 ;
线性筛法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 for (int i = 2 ;i <= n;i++){if (!st[i]){1 ;for (int j = 0 ;p[j] <= n/i;j++){ 1 ;if (i % p[j] == 0 )break ;for (int i = 2 ;i <= n;i++){if (!st[i]){1 ;for (int j = 0 ;prime[j]<=n/i;j++){1 ;if (i%prime[j])break ;
约数求解 试除法求约数 1 2 3 4 5 6 7 8 9 10 11 vector<int > v;for (int i = 1 ;i <= a/i;i++){if (a % i == 0 ){push_back (i);if (i != a/i)v.push_back (a/i);sort (v.begin (),v.end ());for (auto t:v){" " ;
求约数个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 while (n--){int a;for (int i = 2 ;i <= a/i;i++){if (a % i == 0 ){while (a % i == 0 ){if (a > 1 )m[a]++;for (auto a:m){1 )) % N;
约数和:秦九韶算法
最大公约数:辗转相除法 1 2 3 int gcd (int a,int b) return b==0 ?a:gcd (b,a%b);
欧拉函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 while (n--){int a;long long r = a;for (int i = 2 ;i <= a/i;i++){if (a % i == 0 ){-1 )/i;while (a % i == 0 ) a/=i;if (a > 1 )r = r*(a-1 )/a;
筛法求欧拉和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void ruler (int n) for (int i = 2 ;i <= n;i++){if (!st[i]){-1 ;1 ;for (int j = 0 ;p[j] <= n/i;j++){1 ;if (i % p[j] == 0 ){break ;else phi[p[j]*i] = phi[i]*(p[j]-1 );for (int i = 2 ;i <= n;i++) r+=phi[i];
快速幂 板子 快速幂需要注意%p的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 typedef long long LL;int qmi (LL a,int b,int p) 1 ;while (b){if (b&1 ) r = (LL)((r*a)%p);1 ;return r;
快速幂求逆元
1 2 3 4 5 6 else cout << qmi (a,p-2 ,p) << endl;
扩展欧几里得算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int exgcd (int a,int b,int &x,int &y) if (!b){1 ;y=0 ;return a;int d = exgcd (b,a%b,y,x);
求线性同余方程
1 2 3 4 5 6 7 8 9 10 11 12 int a,b,m,x,y;int d = exgcd (a,m,x,y);if (b % d != 0 ) cout << "impossible" << endl;else cout << (LL)x *(b/d) % m << endl;
中国剩余定理 表达整数的奇怪方式
推导过程:
组合数问题 第一种解法:公式法递推 运用公式:Cb/a = Cb/a-1+Cb-1/a-1;
首先将所有的组合数情况用类似DP的方法给计算出来,然后直接哈希对应
1 2 3 4 5 6 7 8 9 10 void init () for (int i = 0 ;i <= 2000 ;i++){for (int j = 0 ;j <= i;j++){if (!j) f[i][j] = 1 ;else f[i][j] = (f[i-1 ][j-1 ]+f[i-1 ][j])%mod;
第二种解法:初始化阶乘值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int qmi (int a,int k,int q) int res = 1 ;while (k){if (k&1 ) res = (LL)res*a%q;1 ;return res;int main () int n;0 ] = inf[0 ] =1 ;for (int i = 1 ;i < N;i++){-1 ]*i% mod;-1 ]*qmi (i,mod-2 ,mod) % mod;while (n--){int a,b;return 0 ;
第三种解法:卢卡斯定理 如何应用:直接应用公式
首先:注意LL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std;typedef long long LL;int p;LL qmi (int a,int k,int p) {1 ;while (k){if (k&1 ) res = (LL)res*a%p;1 ;return res;LL C (LL a,LL b) {1 ;for (int i = 1 ,j = a;i <= b;i++,j--){qmi (i,p-2 ,p) % p;return res;LL lucas (LL a,LL b) {if (a < p && b < p)return C (a,b);else return (LL)C (a%p,b%p) * lucas (a/p,b/p) % p;int main () int n;while (n--){lucas (a,b) << endl;return 0 ;
第四种解法:高精度乘法+质数分解抵消 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <iostream> #include <vector> using namespace std;const int N = 5010 ;int prime[N],cnt;int sum[N],st[N];void get_prime (int a) for (int i = 2 ;i <= a;i++){if (!st[i])prime[cnt++] = i;for (int j = 0 ;prime[j] <= a/i;j++){true ;if (i % prime[j]==0 )break ;int get (int a,int p) int res = 0 ;while (a){return res;vector<int > mul (vector<int > a,int b) {int t = 0 ;int > res;for (int i = 0 ;i < a.size ();i++){push_back (t%10 );10 ;while (t){push_back (t%10 );10 ;while (res.size () && res.back ()==0 ) res.pop_back ();return res;int main () int a,b;get_prime (a);for (int i = 0 ;i < cnt;i++){get (a,prime[i])-get (a-b,prime[i])-get (b,prime[i]);int > ans;push_back (1 );for (int i = 0 ;i < cnt;i++){for (int j = 0 ;j < sum[i];j++){mul (ans,prime[i]);for (int i = ans.size ()-1 ;i >= 0 ;i--){return 0 ;
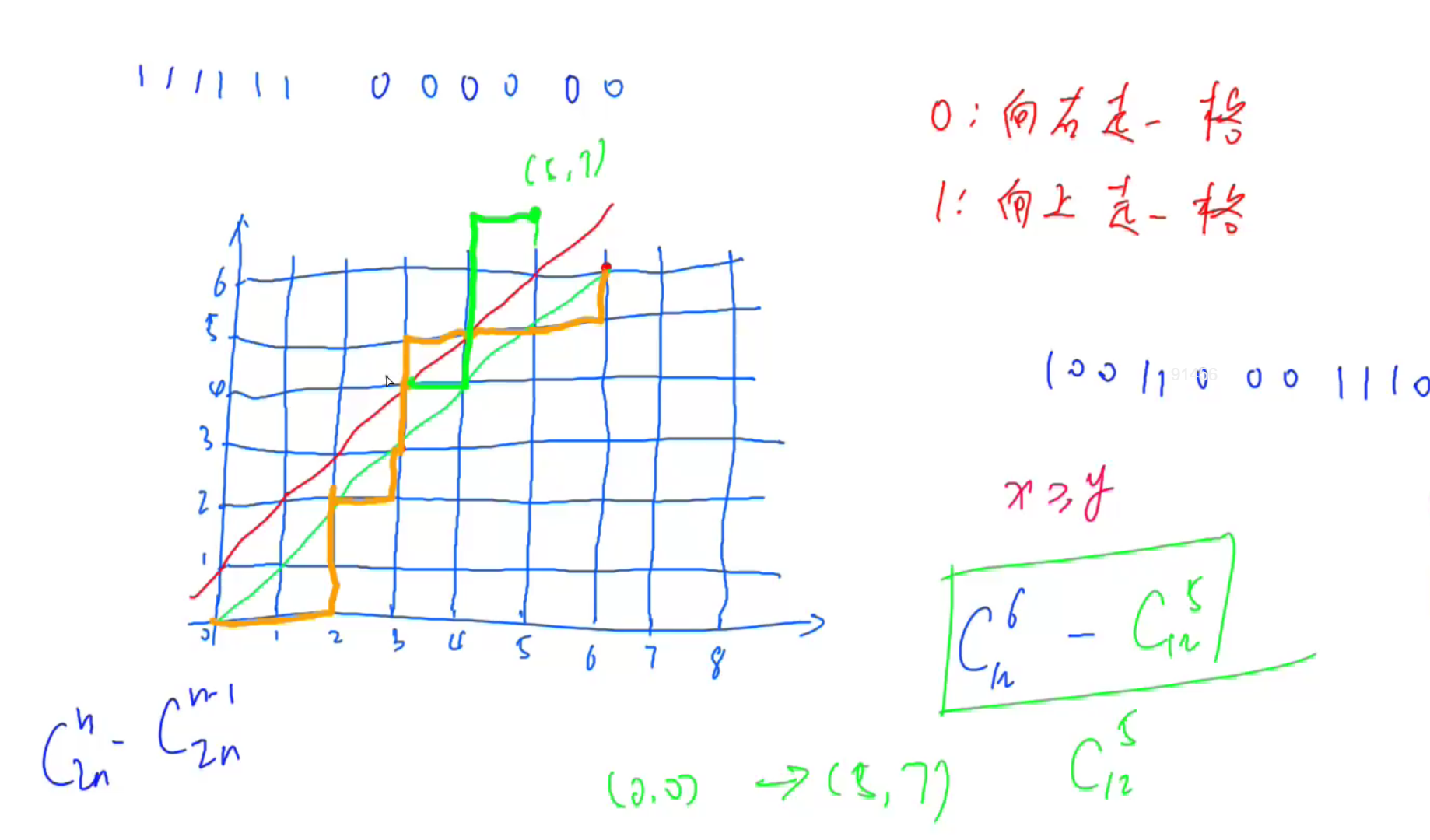
满足条件的01序列
红色线是高压红线。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <cstring> #include <algorithm> using namespace std;typedef long long LL;const int N = 200010 ,mod = 1e9 +7 ;LL qmi (int a,int k,int q) {int res = 1 ;while (k){if (k&1 ) res = (LL)res*a%q;1 ;return res;void init () 0 ] = inf[0 ] = 1 ;for (int i = 1 ;i < N; i++){-1 ]*i%mod;-1 ]*qmi (i,mod-2 ,mod)%mod;int main () int n;cin >> n;init ();int res = (LL)f[2 * n]*inf[n] % mod * inf[n] % mod * qmi (n + 1 , mod - 2 ,mod) % mod;return 0 ;
容斥原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> using namespace std;typedef long long LL;const int N = 1e9 +7 ,M = 20 ;int n,m,f[M];int main () for (int i = 0 ;i < m;i++){int res=0 ;for (int i = 1 ;i < 1 << m;i++){1 ;int s = 0 ;for (int j = 0 ;j < m;j++){if (i>>j&1 ){if ((LL)t*f[j] > n){-1 ;break ;if (t != -1 ){if (s%2 ==1 ) res += n/t;else res -= n/t; return 0 ;
博弈论 公平组合游戏
台阶NIM问题
解:保证奇数点的数量保持一致不变,这样我们一定可以及时走下去
1 2 3 4 5 6 7 8 9 int cnt = 1 ;int res = 0 ;while (n--){int a;cin >> a;if (cnt&1 )res ^= a;if (res) cout << "Yes" ;else cout << "No" ;
集合NIM问题
SG函数:到不了的自然数最小值+1
SG(x) = 0的话,其对应点无法走到终点,因为没有一条数字下降的路。
SG(x) != 0的话,一定能找到一条路,其路可以指向终点SG(0)
多个图的处理:SG(x1)^SG(x2)^…^SG(xn) = 0必败,!=0必胜,其中x1,x2,…,xn是每个图的起点
1.Mex运算:
2.SG函数
3.有向图游戏的和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 int sg (int x) if (f[x] != -1 )return f[x];int > S;for (int i = 0 ;i < n;i++){if (x>=s[i])S.insert (sg (x-s[i]));for (int i=0 ;;i++){if (!S.count (i))return f[x] = i;int sg (int x) if (f[x]!=-1 )return f[x];int > S;for (int i = 0 ;i < n;i++){if (x>=s[i])S.insert (sg (x-s[i]));for (int i = 0 ;;i++){if (!s.count (i))return f[x]=i;int main () for (int i = 0 ;i < n;i++)cin >> s[i];int res = 0 ;memset (f,-1 ,sizeof f);for (int i = 0 ;i < k;i++){int m;cin >> m;sg (m);if (res) cout << "Yes" ;else cout << "No" ;return 0 ;
拆分NIM游戏
1 2 3 4 5 6 7 8 9 10 11 12 int sg (int x) if (f[x]!=-1 )return f[x];int > S;for (int i = 0 ;i < x;i++){for (int j = 0 ;j <= i;j++){insert (sg (i)^sg (j));for (int i = 0 ;;i++){if (!S.count (i)) return f[x] = i;
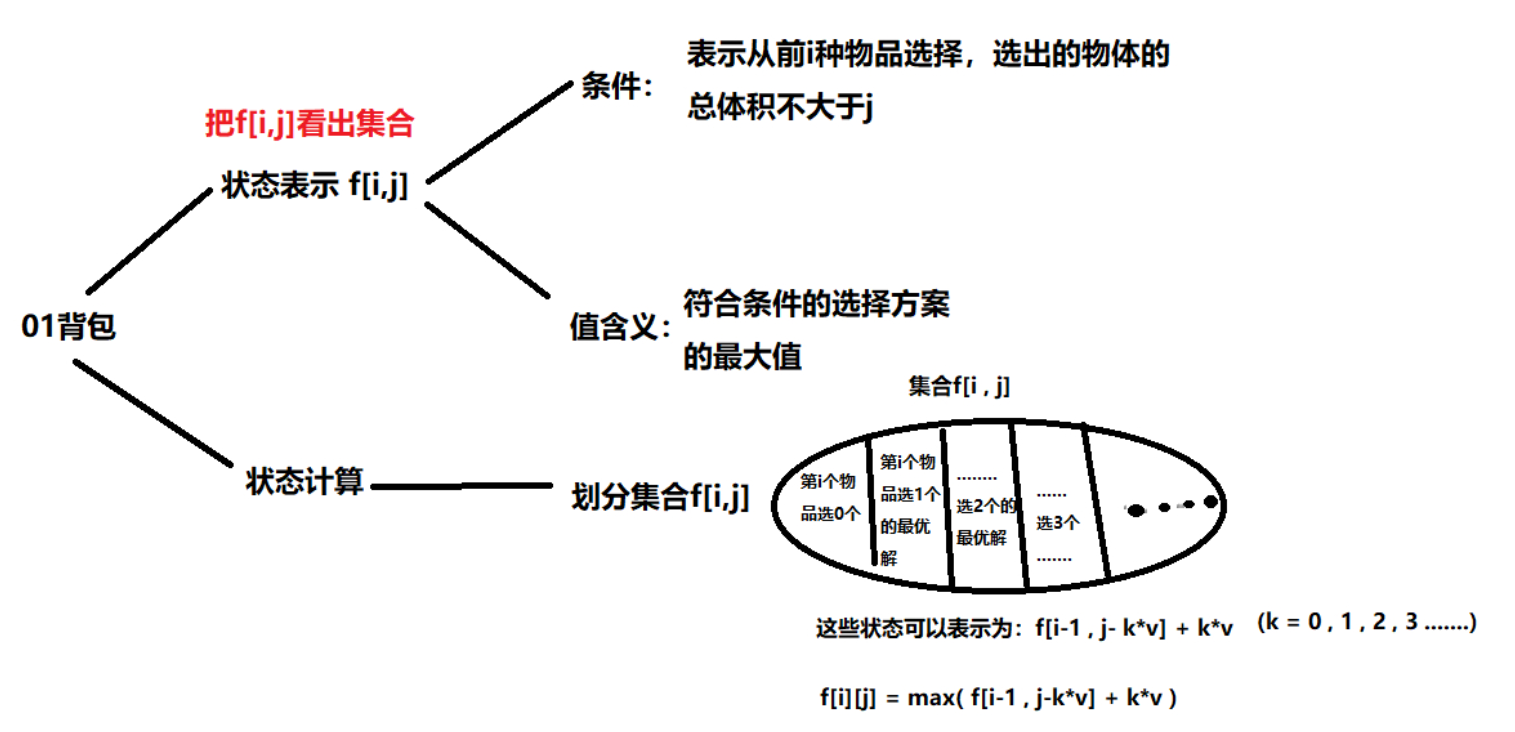
背包问题
01背包:每个物品只有一件
二维解法 1 2 3 4 5 6 7 8 9 10 11 int f[N][N];int w[N],v[N];for (int i = 0 ;i <= n;i++){for (int j = 0 ;j <= m;j++){if (j >= v[i]){max (f[i-1 ][j],f[i-1 ][j-v[i]]+w[i]);
一维解法 1 2 3 4 5 6 7 8 9 10 11 12 13 int f[N][N];int w[N],v[N];for (int i = 1 ;i <= n;i++){for (int j = m;j >= v[i];j--){max (f[j],f[j-v[i]]+w[i]);
完全背包:不规定物品件数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 for (int i = 1 ;i <= n;i++){for (int j = v[i];j <= m;j++){max (f[j],f[j-v[i]]+w[i]);
两个代码其实只有一句不同(注意下标)
f[i][j] = max(f[i][j],f[i-1][j-v[i]]+w[i]);//01背包
f[i][j] = max(f[i][j],f[i][j-v[i]]+w[i]);//完全背包问题
多重背包:规定每个物品的件数
在01背包的基础上加入一套循环,每次加入k件物品,进行判断(O(N3))
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ;i <= n;i++){int v,w,s;for (int j = m;j >= v;j--){for (int k = 1 ;k <= s;k++){if (j >= k*v) f[j] = max (f[j],f[j-k*v]+k*w);
优化:使用快速幂的思路,重新创造一个物品列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct Good {int v,w;int main () int n,m;for (int i = 1 ;i <= n;i++){int v,w,s;clear ();for (int j = 1 ;s >= j;j*=2 ){push_back ({j*v,j*w});if (s)g.push_back ({s*v,s*w});for (auto a:g){for (int j = m;j >= a.v;j--){max (f[j],f[j-a.v]+a.w);return 0 ;
分组背包:每个组内01背包
1 2 3 4 5 6 7 8 9 10 11 for (int i=1 ;i<=n;i++){for (int j=0 ;j<s[i];j++)for (int i=1 ;i<=n;i++){for (int j=m;j>=0 ;j--){for (int k=0 ;k<s[i];k++)if (v[i][k]<=j) f[j]=max (f[j],f[j-v[i][k]]+w[i][k]);
线性DP问题 线性DP问题一般都涉及到位置计算。
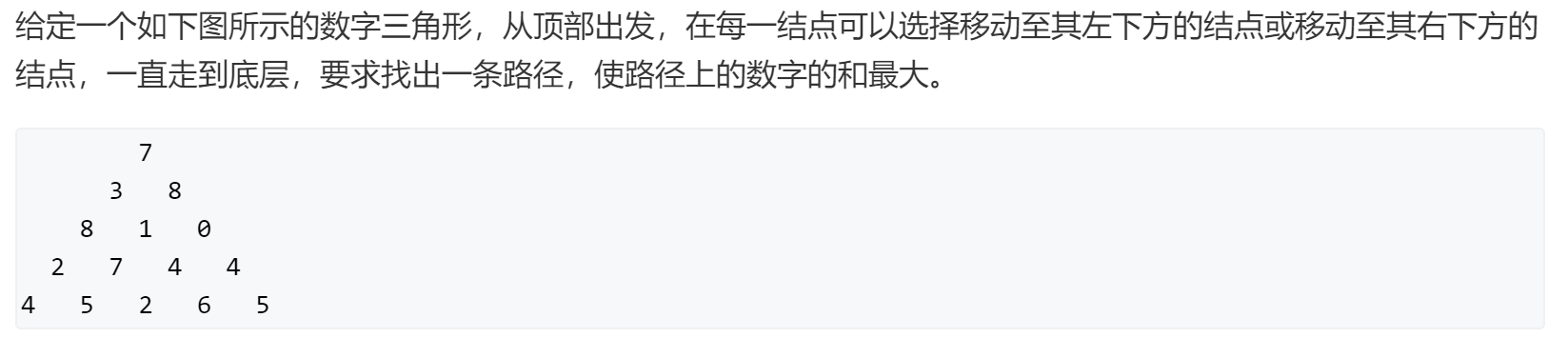
数字三角形
1 2 3 4 5 6 for (int i = n-1 ;i > 0 ;i--){for (int j = 1 ;j <= i;j++){max (f[i+1 ][j],f[i+1 ][j+1 ])+f[i][j];
最长上升子序列:使用二分进行优化 原理:
题解中最难理解的地方在于栈中序列虽然递增,但是每个元素在原串中对应的位置其实可能是乱的,那为什么这个栈还能用于计算最长子序列长度?而是【以stk[i]结尾的子串长度最长为i】 或者说【长度为i的递增子串中,末尾元素最小的是stk[i]】 。理解了这个问题以后就知道为什么新进来的元素要不就在末尾增加,要不就替代第一个大于等于它元素的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> using namespace std;const int N = 100010 ;int f[N],n;int g[N];int main () for (int i = 1 ;i <= n;i++)cin >> f[i];1 ] = f[1 ];int t = 1 ;for (int i = 2 ;i <= n;i++){if (g[t] < f[i]){1 ] = f[i];else {int l = 1 ,r = t;while (l < r){int m = (l+r)/2 ;if (g[m] >= f[i]) r = m;else l = m+1 ;return 0 ;
最长公共子序列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (int i = 1 ;i <= n;i++){for (int j = 1 ;j <= m;j++){if (a[i]==b[j]) f[i][j] = f[i-1 ][j-1 ]+1 ;else {max (f[i-1 ][j],f[i][j-1 ]);
最短编辑距离 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 for (int i = 0 ;i <= m;i++)f[0 ][i] = i;for (int i = 0 ;i <= n;i++)f[i][0 ] = i;for (int i = 1 ;i <= n;i++){for (int j = 1 ;j <= m;j++){min (f[i-1 ][j]+1 ,f[i][j-1 ]+1 );min (f[i][j],f[i-1 ][j-1 ]+(a[i]!=b[j]));
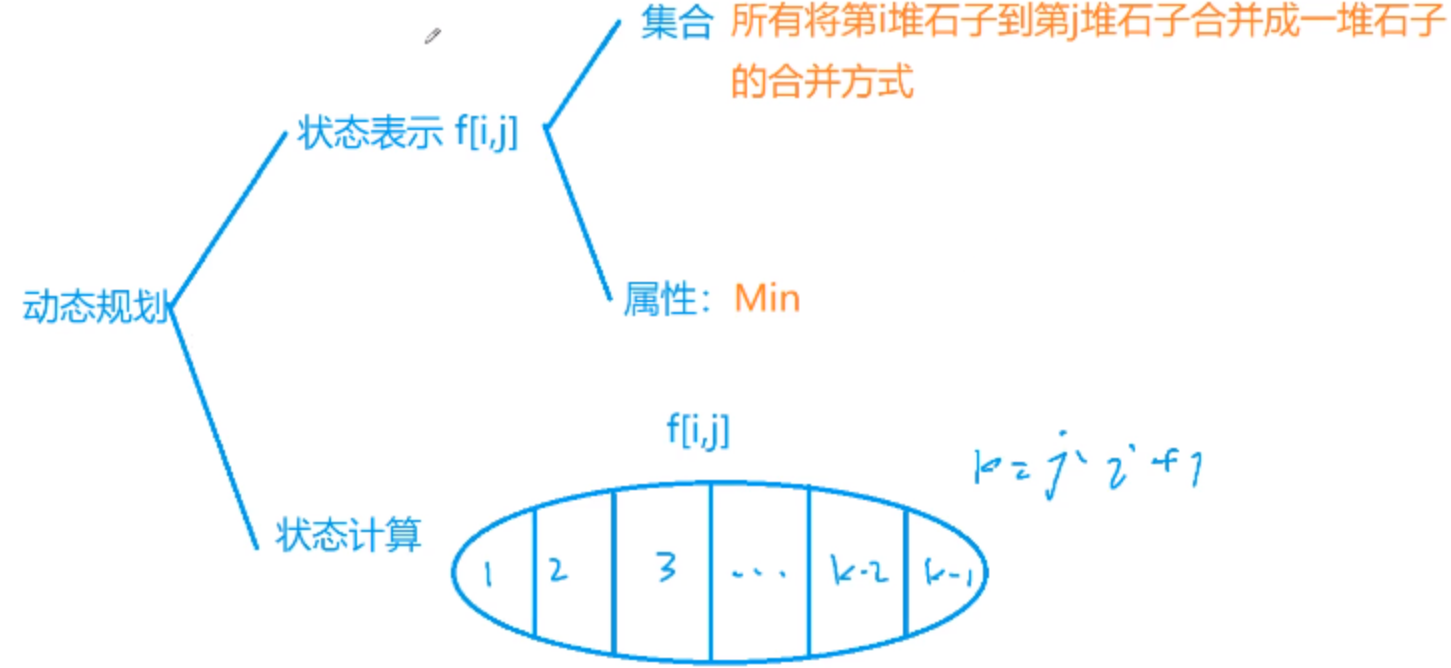
区间DP 石子合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <cstring> using namespace std;const int N = 310 ;int n;int s[N],a[N],f[N][N];int main () for (int i = 1 ;i <= n;i++)cin >> a[i];for (int i = 1 ;i <= n;i++)s[i] = a[i]+s[i-1 ];for (int len = 2 ;len <= n;len++){ for (int i = 1 ;i + len-1 <= n;i++){ int j = i+len-1 ; 1e7 ;for (int k = i;k <= j-1 ;k++){ min (f[i][j],f[i][k]+f[k+1 ][j]);-1 ];1 ][n];return 0 ;
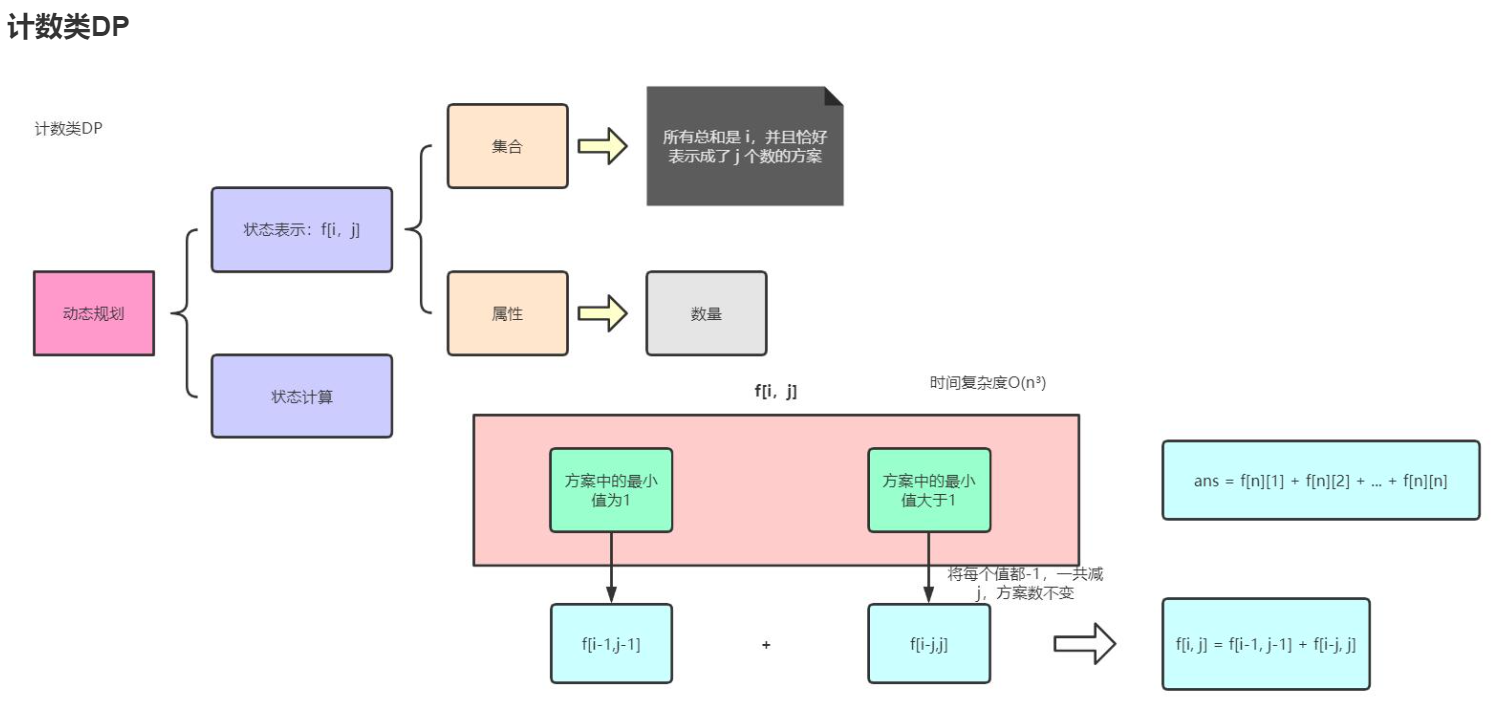
计数DP
数位统计DP 计数问题 状态压缩DP 蒙特卡罗的梦想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <bits/stdc++.h> using namespace std;const int N=12 , M = 1 << N; long long f[N][M] ;bool st[M]; int >> state (M); int m , n;int main () while (cin>>n>>m, n||m){ for (int i=0 ; i< 1 <<n; i++){int cnt =0 ;bool isValid = true ; for (int j=0 ;j<n;j++){ if ( i>>j &1 ){ if (cnt &1 ) { false ;break ;0 ; else cnt++; if (cnt &1 ) isValid =false ; for (int j=0 ;j< 1 <<n;j++){ clear (); for (int k=0 ;k< 1 <<n;k++){ if ((j&k )==0 && st[ j| k] ) push_back (k); memset (f,0 ,sizeof f); 0 ][0 ]=1 ;for (int i=1 ;i<= m;i++){ for (int j=0 ; j< 1 <<n; j++){ for ( auto k : state[j]) -1 ][k]; 0 ]<<endl;
最短哈密顿路径(旅行商问题)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 memset (g,0x3f ,sizeof g);1 ][0 ] = 0 ;for (int i = 0 ;i < 1 <<n;i++){for (int j = 0 ;j < n;j++){ if (i>>j & 1 ){for (int k = 0 ;k < n;k++){if (i>>k & 1 ){min (g[i][j],g[i-(1 <<j)][k]+f[k][j]);1 <<n)-1 ][n-1 ];
树形DP 没有上司的酒会
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void dfs (int n) 1 ] = happy[n];for (int i = h[n];i != -1 ;i = ne[i]){int down = e[i];dfs (down);0 ] += max (f[down][1 ],f[down][0 ]);1 ] += f[down][0 ];int main () memset (h,-1 ,sizeof h);for (int i = 1 ;i <= n;i++)cin >> happy[i];for (int i = 0 ;i < n-1 ;i++){int a,b;add (b,a);1 ;int root = 1 ;while (upper[root])root++;dfs (root);max (f[root][0 ],f[root][1 ]) << endl;return 0 ;
记忆化搜索 记忆化搜索一般跟着dfs一起使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int dp (int x,int y) if (f[x][y]) return f[x][y];1 ;for (int i=0 ;i<4 ;i++)int xx=x+dx[i];int yy=y+dy[i];if (xx>=1 &&xx<=n&&yy>=1 &&yy<=m&&h[x][y]>h[xx][yy])max (f[x][y],dp (xx,yy)+1 );return f[x][y];
划分数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <cstring> #include <algorithm> using namespace std;typedef long long LL;const int N = 12 ;int main () while (cin >> a >> b){memset (f,0 ,sizeof f);for (int i = 1 ; i <= a; ++i)0 ] = 0 ;for (int j = 1 ; j <= b; ++j)0 ][j] = 1 ;for (int i = 1 ;i <= a;i++){for (int j = 1 ; j <= b;j++){if (i >= j)f[i][j] = f[i][j-1 ]+f[i-j][j];else f[i][j] = f[i][i];return 0 ;
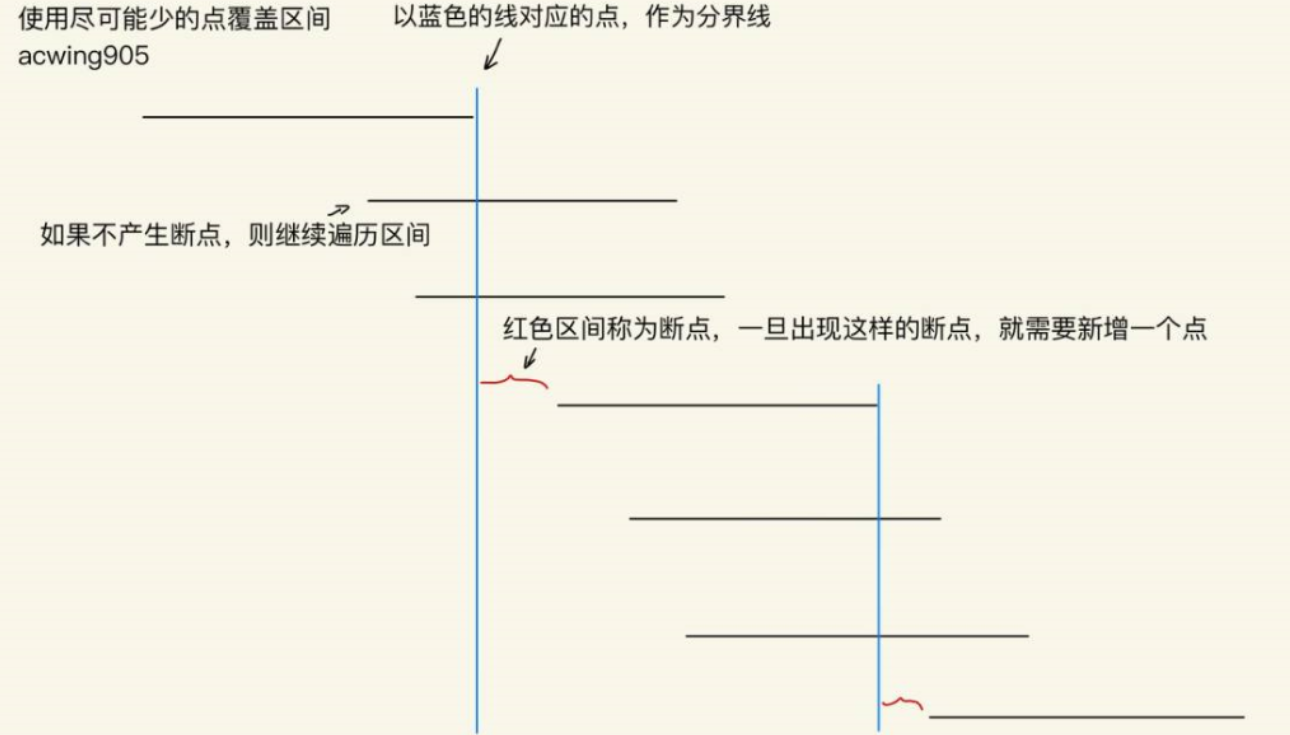
区间问题 区间选点(最大不相交区间数)
右端点排序。 每次优先找最右端点,如果当前最右点小于下一个区间的最左点,则前面所有区间的最右边和下一区间的最左边没有相交,即多一个新的区间。·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for (int i = 0 ;i < n;i++){int l,r;sort (e,e+n,cmp);int r = -2e9 ;int sum = 0 ;for (int i = 0 ;i < n;i++){int tl = e[i].l;if (r<tl){
区间分组(教室安排问题) 左端点排序。 找到最靠左的右端点,如果最靠左的max_r < l,代表存在一个组可以放入这个区间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 sort (p,p+n,cmp);int ,vector<int >,greater<int >> q;for (int i = 0 ;i < n;i++){int l = p[i].l;if (q.empty () || l <= q.top ()){push (p[i].r);r++;else {pop ();q.push (p[i].r);sort (p,p+n,cmp);for (int i = 0 ;i < n;i++){if (q.empty ()||p[i].l <= q.top ()){push (p[i].r);else {pop ();q.push (p[i].r);
区间覆盖
左端点排序 ,在左端点小于s的情况下优先找右端点最大的区间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (int i = 0 ;i < n;i++){int j = i,r = -2e9 ;while (j < n && p[j].l <= s){max (r,p[j].r);if (r < s) break ;if (r >= t){true ;break ;-1 ;if (sc) cout << res;else cout << -1 ;
总结 区间选点问题:右排序 ,优先选择最右点
区间分组问题:左排序 ,如果最小分组的max_r都大于当前区间的l,则代表区间与所有分组有冲突,新开一组
区间覆盖问题:左排序 ,如果l<s,则找到其符合条件区间的最右端点并更新成s,注意判断断点和结束点
哈夫曼树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int ,vector<int >,greater<int >> q;while (n--){int t;push (t);int r = 0 ;while (q.size ()>1 ){int a = q.top ();q.pop ();int b = q.top ();q.pop ();int c = a+b;r+=c;push (c);
排序不等式
绝对值不等式 货仓选址
优先向中间建货仓
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <algorithm> using namespace std;int n;const int N = 100010 ;int f[N];int main () for (int i = 0 ;i < n;i++)cin >> f[i];sort (f,f+n);int r = 0 ;int m = n/2 ;for (int i = 0 ;i < n;i++){abs (f[i]-f[m]);return 0 ;
公式推导 日期类 1 2 3 4 5 6 7 8 9 10 int months[2 ][13 ] = {0 ,31 ,28 ,31 ,30 ,31 ,30 ,31 ,31 ,30 ,31 ,30 ,31 },0 ,31 ,29 ,31 ,30 ,31 ,30 ,31 ,31 ,30 ,31 ,30 ,31 },bool isLeap (int y) return (y%4 ==0 &&y%100 !=0 )||y%400 ==0 ;int years[2 ] = {365 ,366 };10 ]={"Friday" ,"Saturday" ,"Sunday" ,"Monday" ,"Tuesday" ,"Wednesday" ,"Thursday" };