CS224N课程P4:依存分析
本文最后更新于:几秒前
课程词汇
1 | |
课程内容
Two views of linguistic structure
- Constituency = phrase structure & grammar = context-free grammars (CFGs)
- Dependency structure
成分语法和上下文无关语法
上下文无关语法使用短语作为非终结符,句子是由短语作为基本单位组成,短语可以嵌套,终结符是最小的短语(基本上是单词),含嵌套的短语作为变元,其可以一直拆解到终结符;通过变元不断组成产生式,句子可以被表示出来。

示例如下:

依存语法的引入
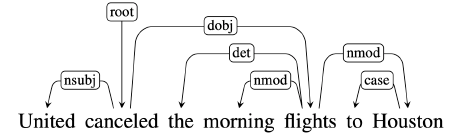
依存结构显示了哪些单词**依赖于(修饰、附加到或是其他单词的参数)**哪些单词; 依赖语法提供了一种更简单的方法,即描述词之间的关系,并确定几个中心词作为句子的主体结构,由其他成分依赖中心词。
如下图所示,整个结构是由依赖关系组成,其中介词in是名词crate的一个依赖,这个是由于依存文法需要保证其在大部分的语言系统中能够使用,因此其应用了格标记系统,将[in the crate]看作一个标记(这里暂时没弄懂,记住罢)。

正规的标记系统示例如下:
语言歧义
介词短语连接的歧义
在英语中,由于介词短语位置的问题,其修饰对象的不同会导致句子出现多种理解,进而导致二义性甚至多义性。
如下面的句子,其中句子后面的[by … ]/[of … ]/[for … ]/[at … ]都是介词短语,英语句法遵循后面的介词短语修饰前面的成分,这个句子的修饰可能性遵循卡特兰数,人类语言的句子其实是十分模糊的,这里的$n=4$。
卡特兰数是一个指数增长模型,因此句子的解析难度会随着长度而指数增加。

协调范围模糊
[Shuttle veteran] and [longtime NASA executive Fred Gregory] appointed to board —— 2 people
[Shuttle veteran and longtime NASA executive] Fred Gregory appointed to board —— 1 people
形容词/副词修饰歧义
Students get [first hand] [job] experience
Students get [first] [hand job] experience
依存语法和依存结构
依存语法假定句法结构由词汇项之间的关系组成,通常为二元非对称关系(“箭头”),称为依赖关系。在依存结构中,箭头通常会标记成语法关系的类型(如aux/obl/…),每个箭头连接一个起始头和依赖项,这些依赖关系会构成一个连通的、无环的、单根的依赖树。
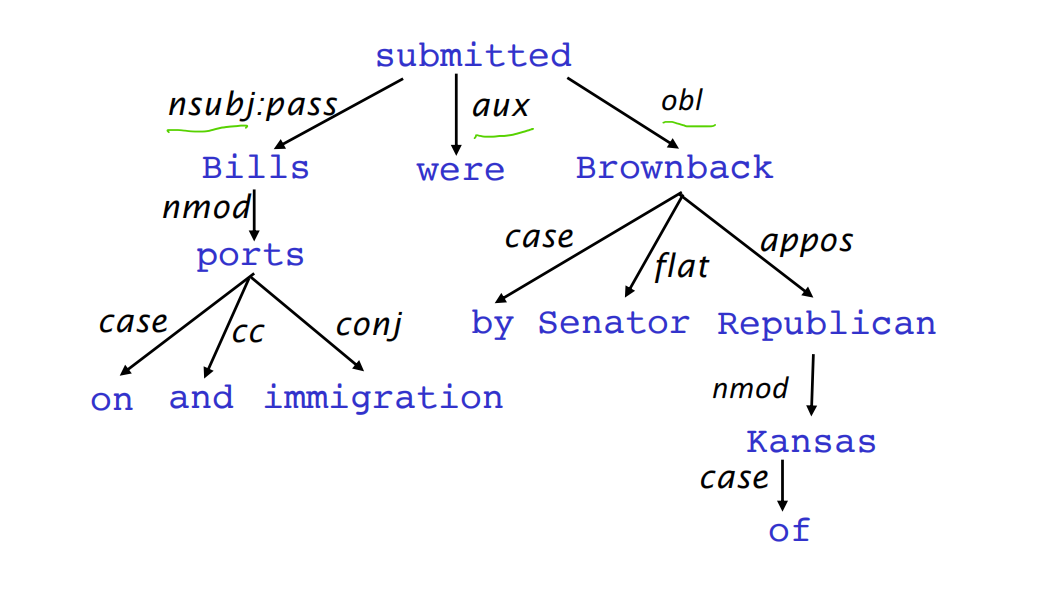
箭头的指向方式习惯是由头部指向依赖项,通常我们也会加入一个root点作为假的根节点,从而保证所有词语都有一个树中的父节点。
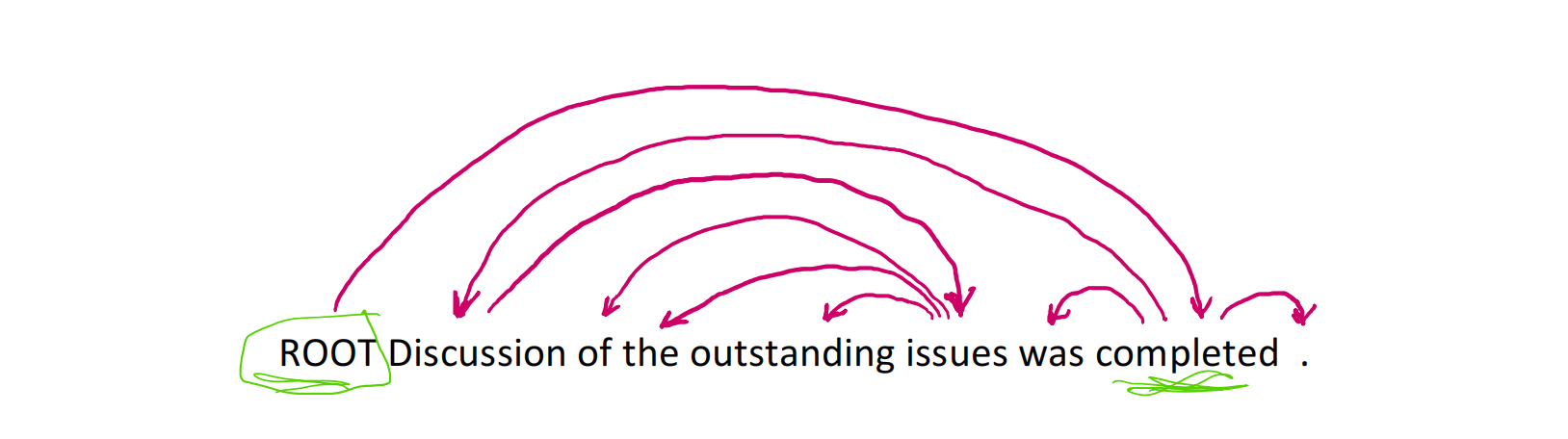
含注释的标注数据
从一开始,构建 treebank 似乎比构建语法慢得多,也没有那么有用
但其会带来许多东西,有以下优点:
- 标签的可重用性
- 广泛的应用范围,不只是直觉上的应用
- 使用频率和可分配信息
- 评估NLP系统的一种方法或指标
依存分析的首选项
- 双词汇亲和(Bilexical affinities):discussing issues会比较合理,而discussing outstanding就不合理;
- 依存间距(Dependency distance):一般相邻的词语才会有依存关系
- 中间词语(Intervening material):如果中间词语是动词或标点,则两边的词语不太可能有依存
- 关系头的效价(Valency of Heads):不同词性的词在作为关系首部时有自己习惯的依存关系,如限定词(Determiner)一般都会在名词(N)左边,如a cat,反过来则很少成立。
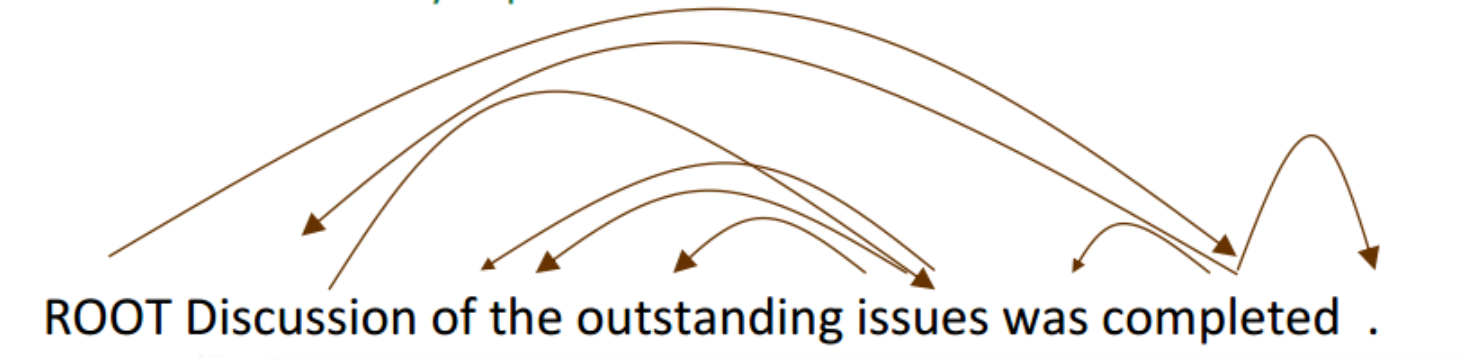
依存分析的过程
依存分析的过程是:一个句子通过对每个单词选择一个头部(包括假根),使其能够成为一个依存关系(A sentence is parsed by choosing for each word what other word (including ROOT) it is a dependent of)
在依存分析的过程中需要注意以下要求:
- 只有一个单词可以是ROOT的依赖项
- 不可出现依赖循环(A->B && B->A)
这可以使得依存分析的结果形成一棵依存分析树。

投影问题
在上面的解析过程中,我们可以发现give->tomorrow和networks->talk两个关系出现了交叉,出现交叉的解析结果我们称之为非投影的,反义则为可投影。
投影解析的定义如下:当单词以线性顺序排列时,没有交叉依赖弧,所有的弧都在单词之上(There are no crossing dependency arcs when the words are laid out in their linear order, with all arcs above the words)
与CFG树并行的依赖树必须是可投影的,通过将每个类别的一个子类别作为头来形成依赖关系。但依赖理论通常会允许非投射结构,用来解释移位的成分,如果没有这些非投射的依赖关系,部分结构的语义会很难获得或理解
例如:

在这句话中,from放在了who的后面,形成了非投影关系,但这句话若没有交叉依赖的话,则会表示成:
1 | |
可投影的依赖表示在这句英语中会很难表达其结构的语义,from who的结构在英语问句中十分少见,因此需要对非投射结构进行兼容。
依存分析的方法
- 动态规划(Dynamic programming):Eisner(1996)提出了一种复杂度为 O(n3) 的聪明算法,它生成头部位于末尾而不是中间的解析项;
- 图算法:为一个句子创建一个最小生成树McDonald et al.’s (2005) MSTParser 使用ML分类器独立地对依赖项进行评分(他使用MIRA进行在线学习,但它也可以是其他东西);
- 约束解析(Constraint Satisfaction):去掉不满足硬约束的边 Karlsson(1990), etc.
- 基于转换的分析或确定性依赖解析(“Transition-based parsing” or “deterministic dependency parsing”) :良好的机器学习分类器 MaltParser(Nivreet al. 2008) 指导下的依存贪婪选择。已证明非常有效。
基于转换的依存分析模型
源于论文[Greedy transition-based parsing [Nivre 2003]]的解析器是贪婪判别依赖解析器的一种简单形式,解析器执行一系列自底向上的操作,大致类似于shift-reduce解析器中的“shift”或“reduce”,但“reduce”操作专门用于创建头在左或右的依赖项(这块我不是太清楚)。
解析器由以下几部分构成:
- 栈$\sigma$:以ROOT符号开始,由若干个单词$w_i$组成;
- 缓存$\beta$:以输入序列开始,由若干个单词$w_i$组成;
- 一个依存弧的集合$A$,一开始为空,每条边的形式为$(w_i,r,w_j)$,其中$r$描述了节点的依存关系;
- 一组操作。
下面给出一个基本的基于转换的依存解析器的例子:
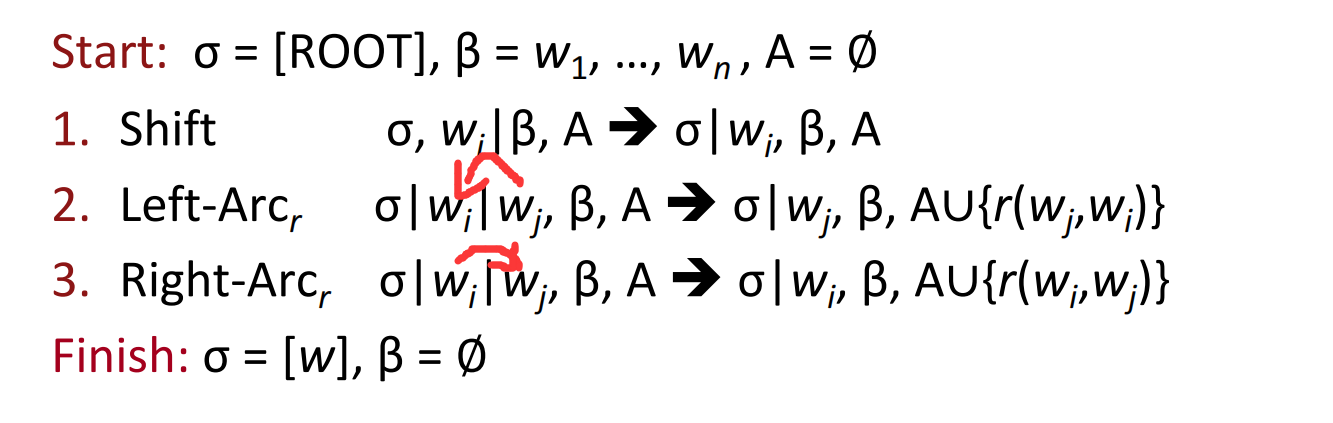
具体的,shift操作会将下一个单词取出,放到栈$\sigma$中;左弧和右弧操作都需要将栈顶的两个单词取出,其中左弧操作和右弧操作的成弧指向不同,放入集合$A$的弧也有所不同,且余留在栈中的单词也不同,但一定是为首选项的那个。
下面给出一个句子并完成其依存分析的过程:(Analysis of “I ate fish”),注意这只是其中一种转换方案,在这里算是正确的方案,可选择的转换方案其实有很多种。
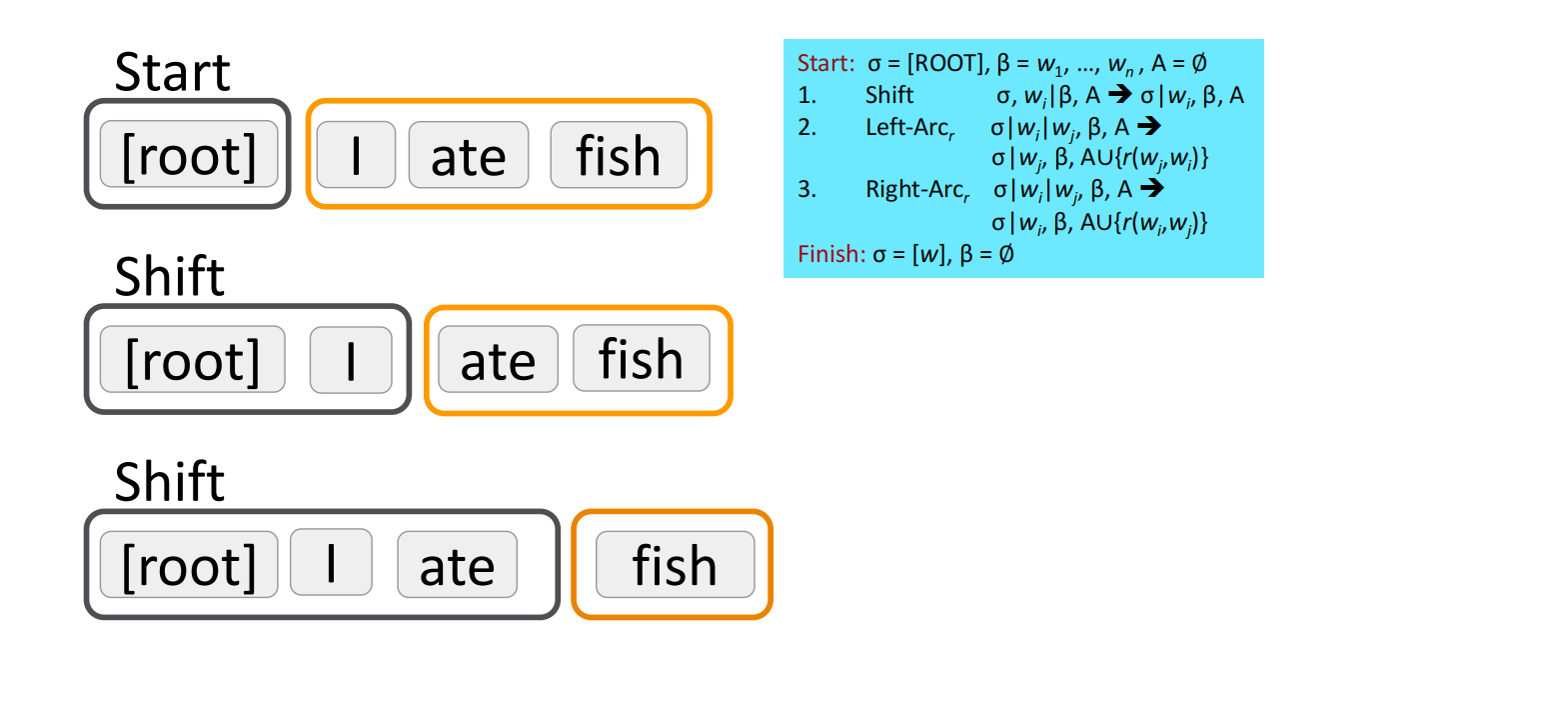
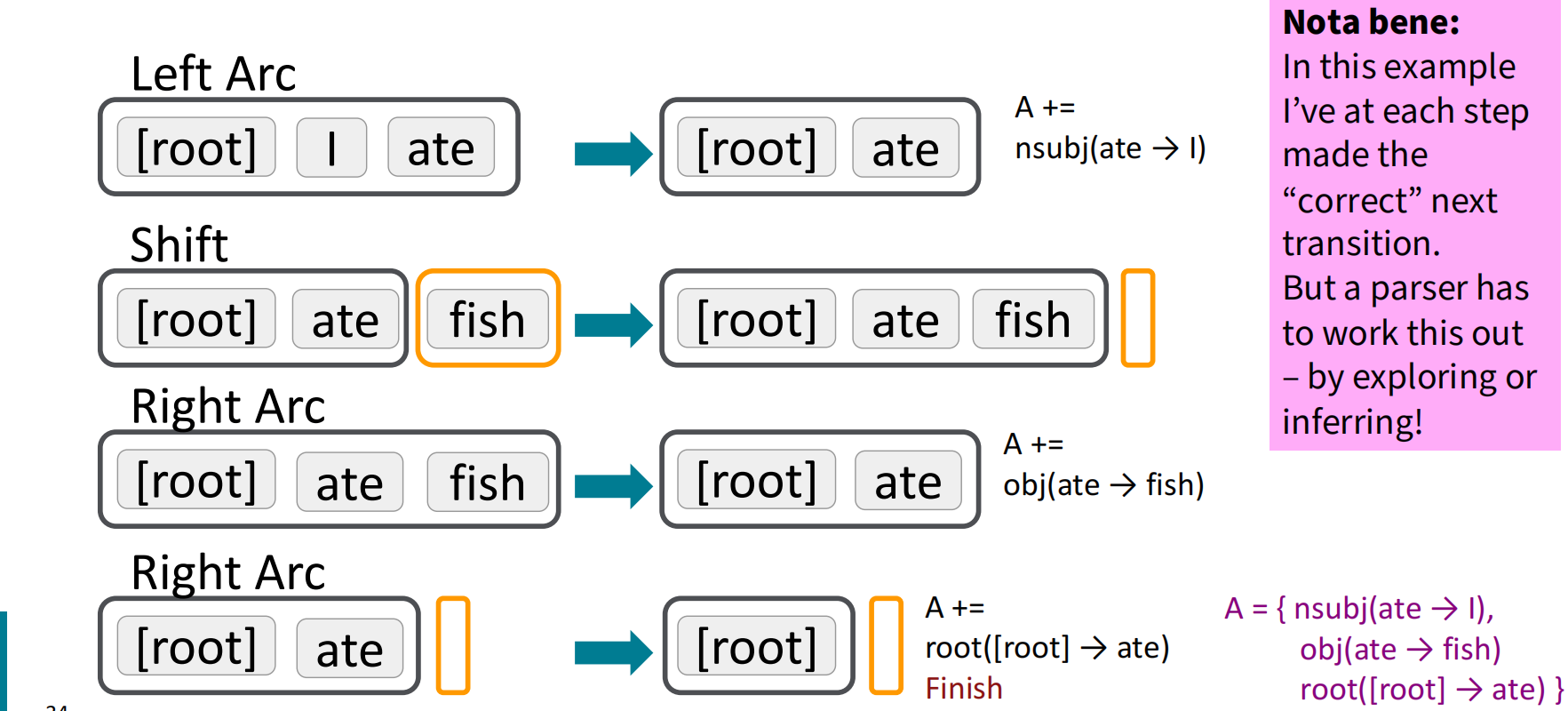
源于MaltParser [Nivre and Hall 2005]的解析器在预测下一步动作上有所进步,使用了机器学习的有区别分类器来预测下一步的动作:最多三种无类型的选择,当带有类型时最多有$|\mathcal R|\times 2+1$种选择。分类器的特征包括:栈顶单词,POS;缓存中第一个单词,POS;等等。
在最简单的形式中是没有搜索的,但是,如果你愿意,你可以有效地执行一个 Beam search 束搜索(虽然速度较慢,但效果更好):你可以在每个时间步骤中保留$k$个好的解析前缀。该模型的精度略低于依赖解析的最高水平,但它提供了非常快的线性时间解析,性能非常好。
传统特征表示
在依存解析器中,传统的特征表示使用二元的稀疏向量表示特征,特征模板通常由配置中的1-3个元素组成,由于配置中的元素组合可能性有极多,因此稀疏向量的维度一般在$10^6-10^7$的规模。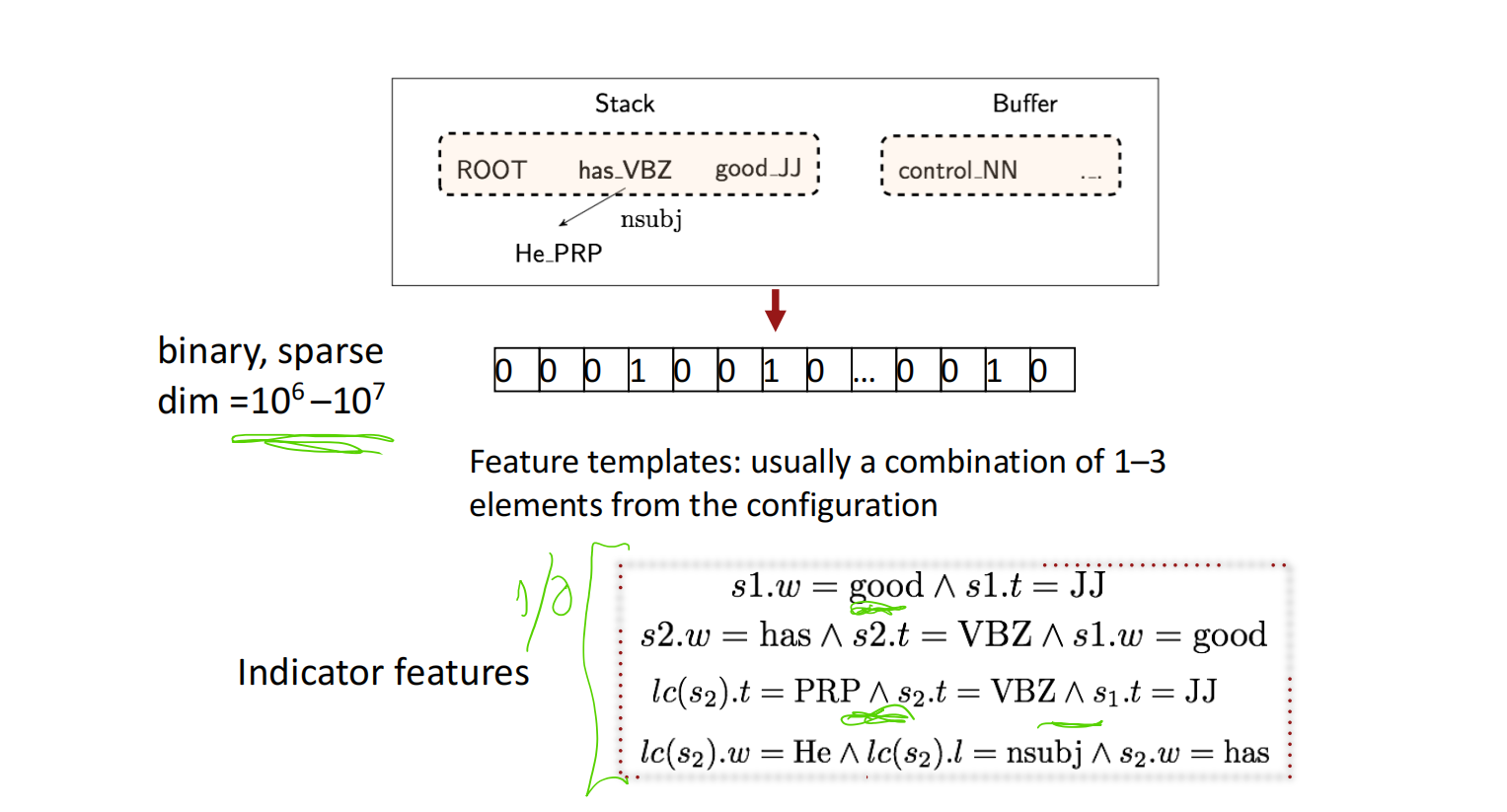
依存分析的评估:两个指标
在依存分析的评估中,常用的有UAS(Unlabeled Accuracy Score)和LAS(Labeled Accuracy Score)两种:
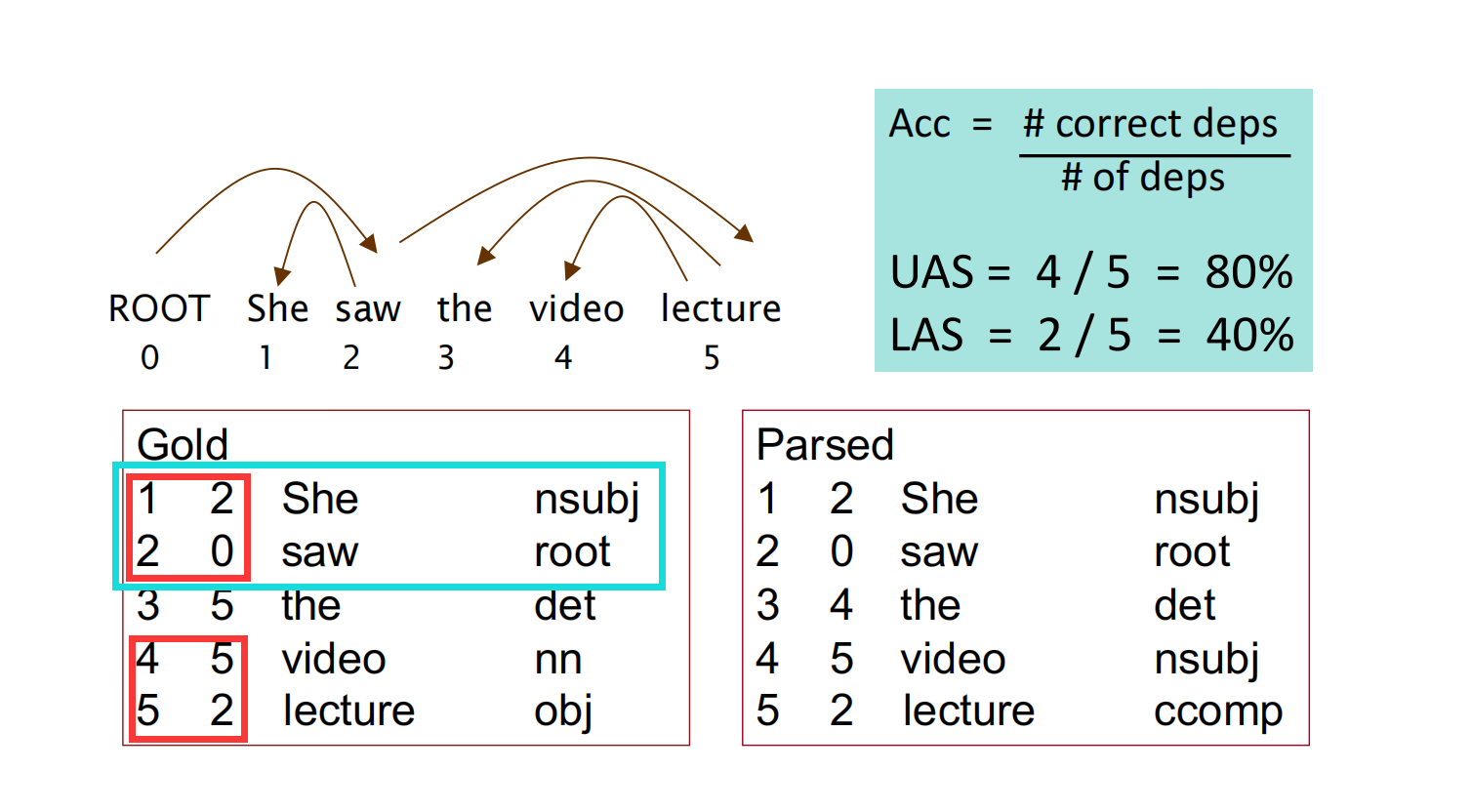
如图所示,首先句子从ROOT开始标记序号,然后分别写出<序号、依赖首选项序号、单词、关系类型>,最后和正确结果做比对,UAS不关注关系类型是否预测正确,只关注依赖弧是否正确;而LAS则一同关注依赖弧和关系类型。
神经网络依存分析器
在前文讲到的依存分析的指示特征中,特征的向量规模达到了$10^6-10^7$的等级,过于稀疏,且特征的出现依赖于固定词汇出现与否,具有不完全性;多于95%的时间都用在了特征计算上,这显然不是我们希望看到的,因此依存分析也可以和word2vec一样引入稠密向量,向量的距离可以表示其相似程度。
源于论文[A neural dependency parser [Chen and Manning 2014]]我们将每个词都表示成$d$维稠密向量,相似的词汇有相近的距离;同时,对于单词词性(POS)和依存关系标签也都表示为$d$维向量。

我们根据堆栈/缓冲区位置提取一组Token:
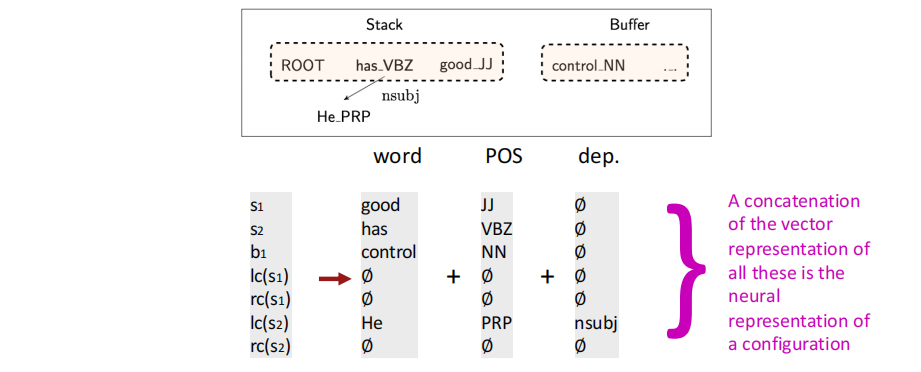
其中$s_i$表示Stack中的第i个单词,$b_i$表示缓冲区的第$i$个单词,$lc(·)$和$rc(·)$分别代表左弧和右弧两个操作,和之前的依存解析器是同一种表示,所有这些向量表示的连接就是一个构型的神经表示。
其次,在稠密向量的神经网络解析器中,深度学习分类器是一个非线性的分类器,顶层使用softmax分类器,底层结合多层神经网络,将原训练空间通过矩阵乘法进行变换,实现非线性。
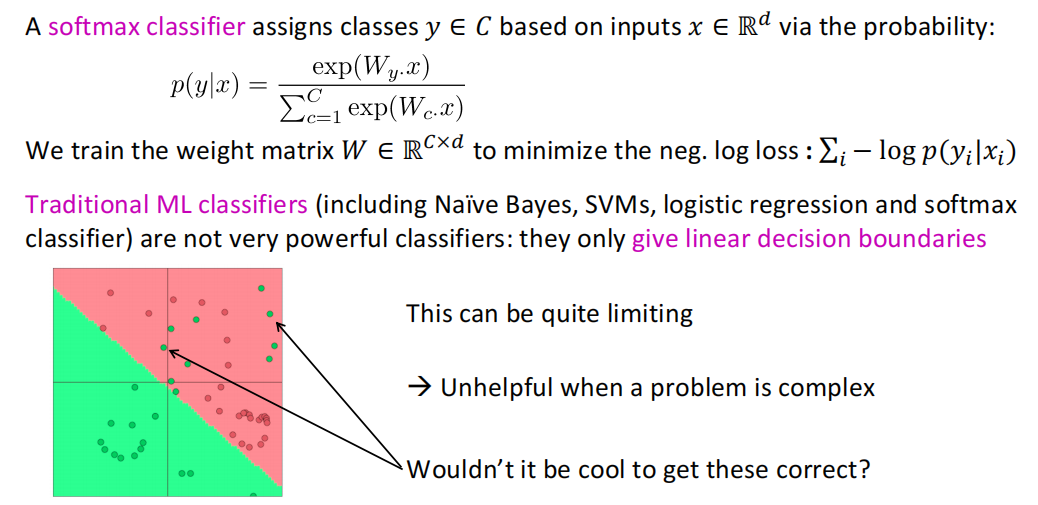
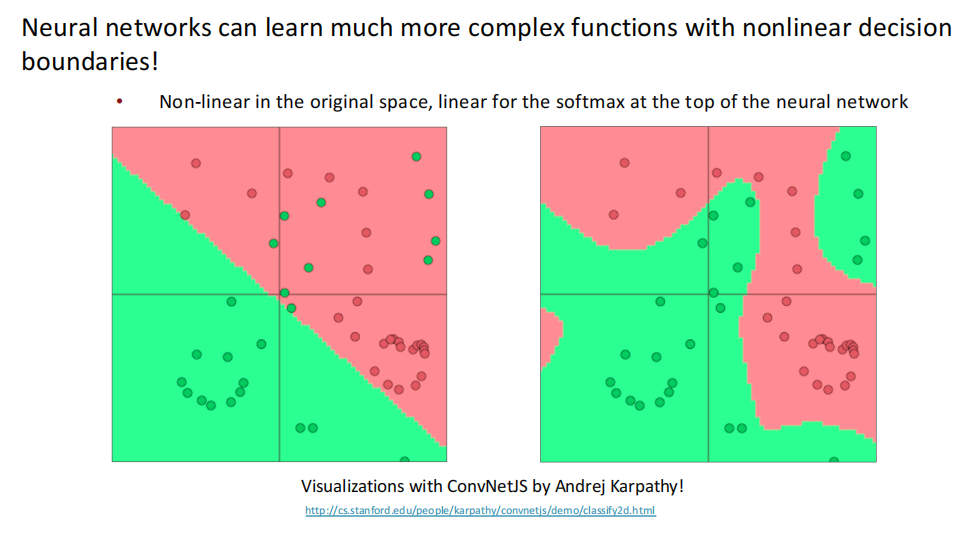
一个简单的前馈神经网络多类别分类器大致如下:
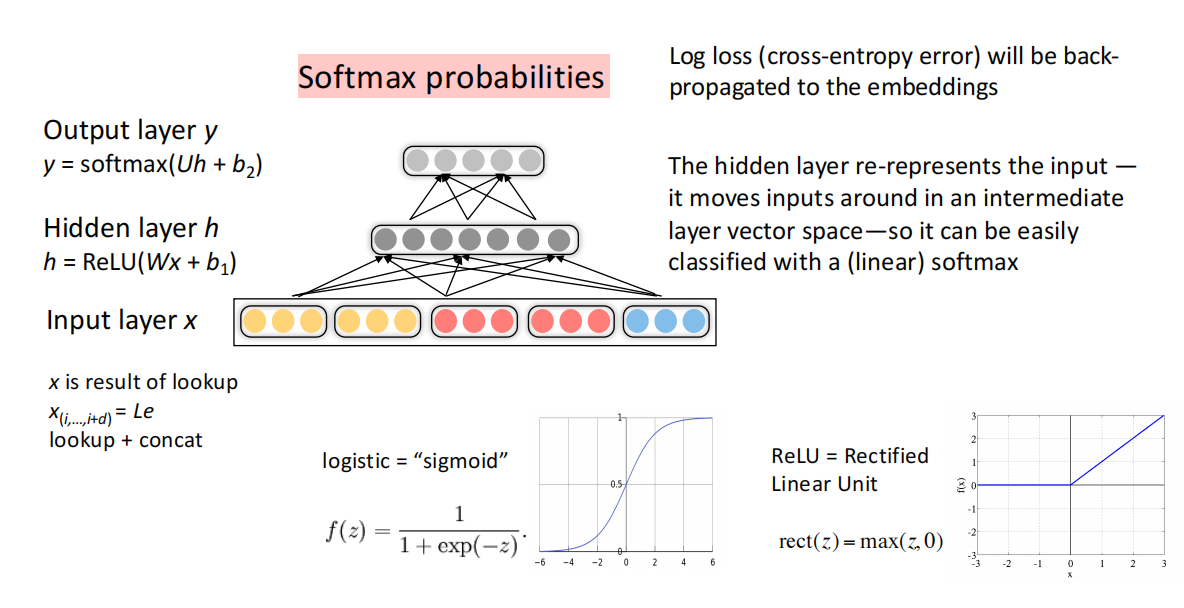
其中包括以下几个部分:
- 输入层$x$:词汇的稠密向量
- 隐藏层$h$:非线性变换(如ReLU,可能有n个),适度降低输入维度
非线性的方法有很多,这里举了比较典型的ReLU做例子。 - 输出层$y$:softmax分类、
在密集的输入层之下,实际上还有一层转换层,用于将含词语词性等特征的独热编码向量转换为稠密向量,这个过程可以理解为矩阵乘法变换。
课后问题
本节课暂无。