注意力机制与外部记忆笔记
本文最后更新于:几秒前
注意力机制与外部记忆
鸡尾酒会效应
人脑处理过载的输入信息时,会使用注意力和记忆机制来解决。
鸡尾酒会效应内容是:当一个人在吵闹的鸡尾酒会上和朋友聊天时,尽管周围噪音干扰很多,他还是可以听到朋友的谈话内容,而忽略其他人的声音(聚焦式注意力)。同时,如果背景声中有重要的词(比如他的名字),他会马上注意到(显著性注意力)。这就体现了注意力机制中十分重要的两种机制:聚焦和显著。
- 聚焦式注意力(会聚):指有预定目的、依赖任务的,主动有意识地聚焦于某一对象的注意力。
- 显著性注意力(汇聚):是由外界刺激驱动的注意,不需要主动干预,也和任务无关,对于重点信息造成的刺激会进行捕捉。
注意力机制
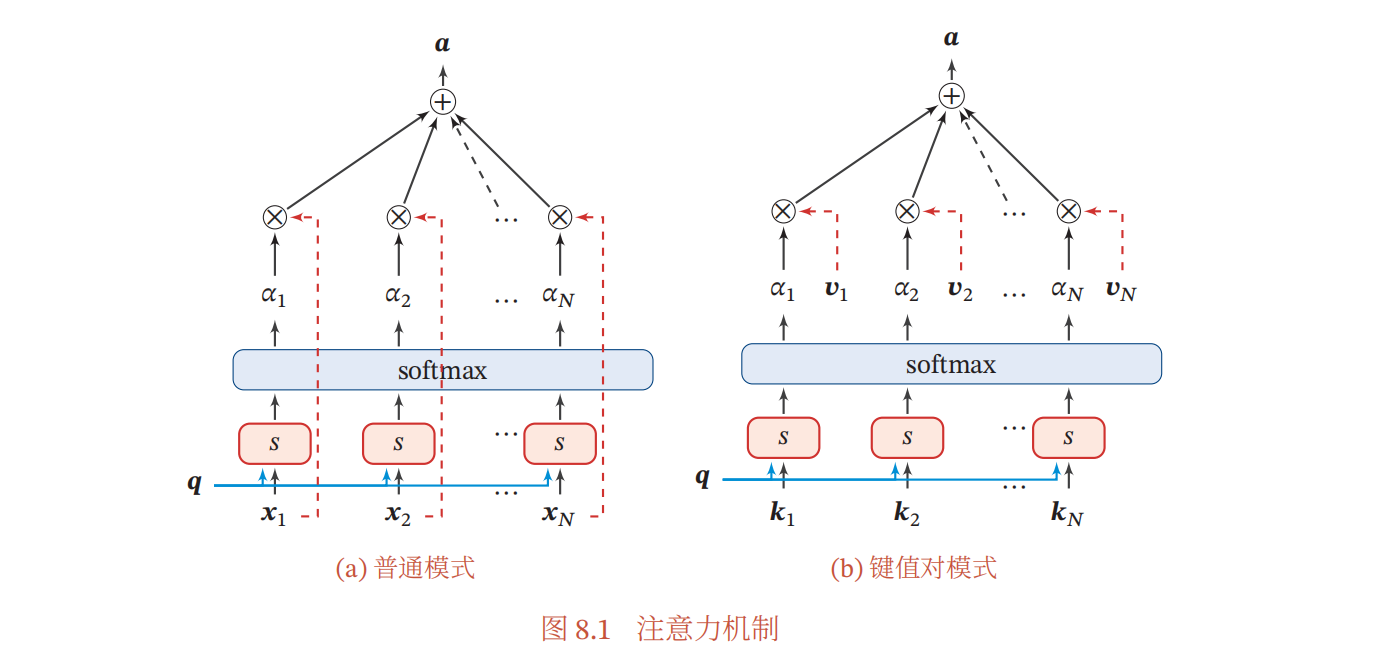
用$\pmb X=[\pmb x_1,…,\pmb x_n]\in \mathbb R^{D\times N}$表示$N$组输入信息,其中$D$维向量$\pmb x_n\in \mathbb R^D,n\in[1,N]$表示一组输入信息,注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均。
软性注意力
软性注意力不是0-1分布(选or不选),而是依概率$p$分布,以$p$的概率选择,这样方便求导操作,从而便于搭模型。
软性注意力机制可以分为以下两步:
计算注意力分布$\alpha$;
$$
\alpha_n=p(z=n|\pmb X,\pmb q)=softmax(s(\pmb x_n,\pmb q))= { { \exp(s(\pmb x_n,\pmb q)) }\over { { \sum_{j=1}^N}\exp(s(\pmb x_n,\pmb q)) } }
$$
其中$s(\pmb x_n,\pmb q)$是打分函数,是用来计算其重要程度,分数越高其重要性越强。打分函数的模型有以下几种:
根据$\alpha$来计算输入信息的加权平均;
$$
att(\pmb X,\pmb q)=\sum_{n=1}^N \alpha_n\pmb x_n=\mathbb E_{z\sim p(\pmb z|\pmb X,\pmb q)}[\pmb {x_z}]
$$
为了能够有效计算,引入查询向量来计算注意力分布。
注意力机制在自然语言处理方向中有很多的应用在:
硬性注意力
离散的注意力机制,输出结果是0-1向量,即选或不选。硬性注意力一般会选取最高概率$att(\pmb X,\pmb q)=\pmb x_\hat n$来进行最大采样或在注意力分布上随机采样来实现。这会使得最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练。因此,硬性注意力通常需要使用强化学习来进行训练,为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。
键值对注意力
更一般地,我们可以用键值对(key-value pair)格式来表示输入信息,其中“键”用来计算注意力分布$\alpha_n$,“值“用来计算聚合信息。
$$
att( [ \pmb K, \pmb V],\pmb q)=\sum_{n=1}^N \alpha_ n \pmb v_ n= \sum_{n=1}^N{ { \exp(s( \pmb k_ n, \pmb q))} \over{ \sum_ j \exp(s( \pmb k_ j, \pmb q))} } \pmb v_ n
$$
当$\pmb{K=V}$时,键值对注意力就会退化成软性注意力。
多头注意力
多头注意力是利用多个查询$\pmb Q=[\pmb q_1,…,\pmb q_M]$来并行地从输入信息中选取多组信息,用多个查询并行处理,每个注意力关注输入信息的不同部分。
$$
att((\pmb K,\pmb V),\pmb Q)=att((\pmb K,\pmb V),\pmb q_1)\oplus\ …\ \oplus att((\pmb K,\pmb V),\pmb q_M)
$$
结构化注意力
设定输入信息本身具有层次结构,比如文本可以分为词、句子、段落、篇章等不同粒度的层次,彼此之间有着关联影响,我们可以使用层次化的注意力来进行更好的信息选择。此外,还可以假设注意力为上下文相关的二项分布,然后就可以用一种图模型来构建更为复杂的结构化注意力分布。
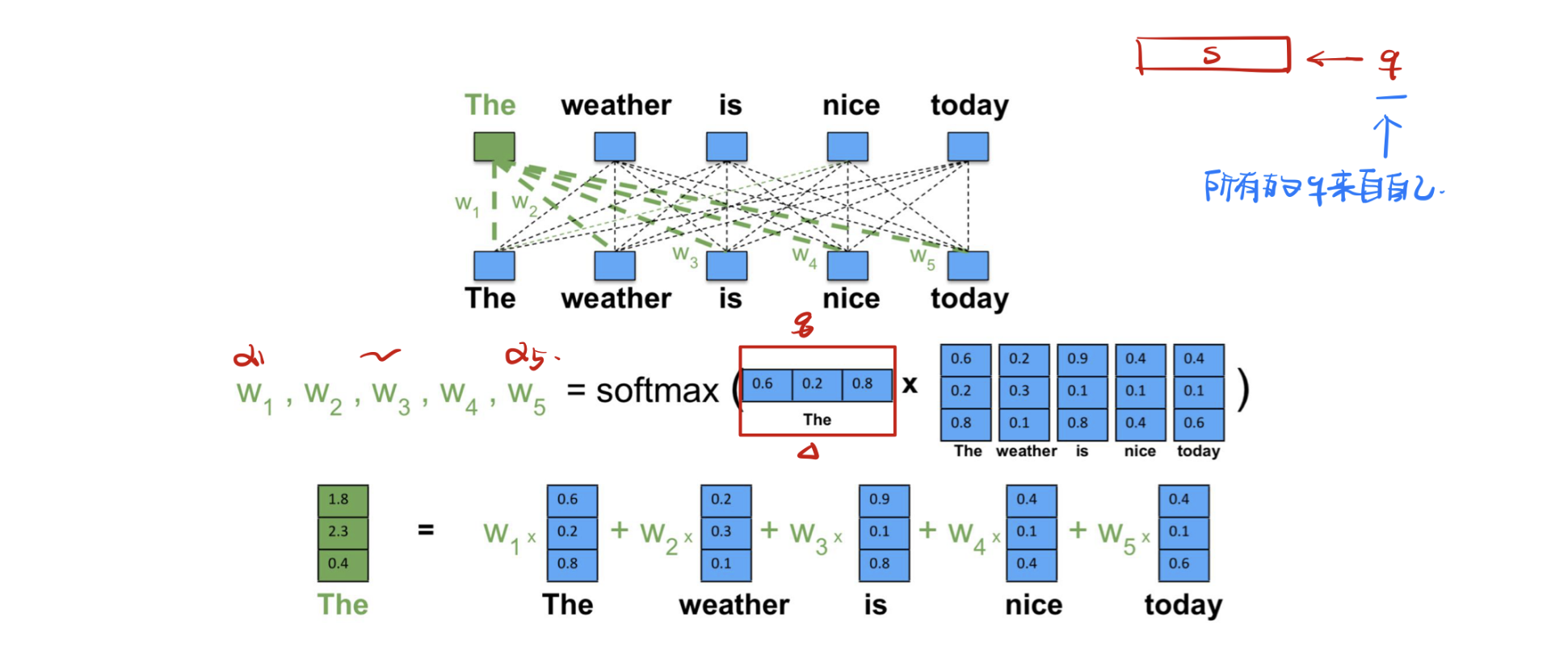
指针网络
我们可以只利用注意力机制中的第一步,将注意力分布作为一个软性的指针来指出相关信息的位置。
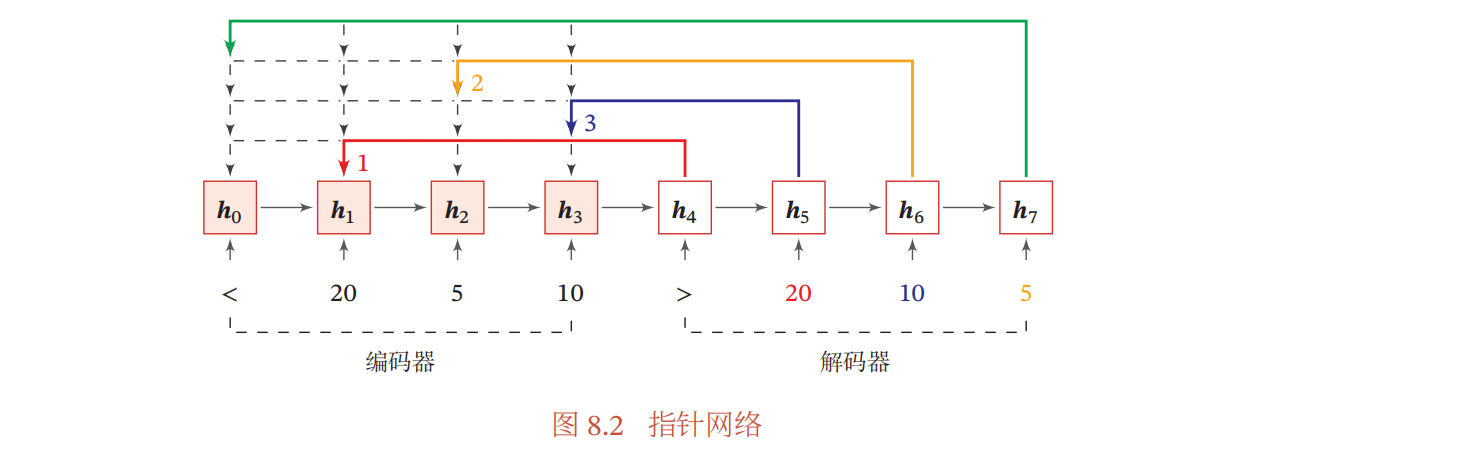
如上图所示,收到’>’信息之后,模型开始计算注意力分布,$h_4$的隐状态输出和$h_1$的相似度最大,因此取$h_5$输入20,$h_5$注意力计算出隐状态和$h_3$相似度最大,故$h_6$输入10,以此类推,实现文本数据从大到小排序。$h_i$的隐状态可以通过RNN实现。
自注意力机制
当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列。
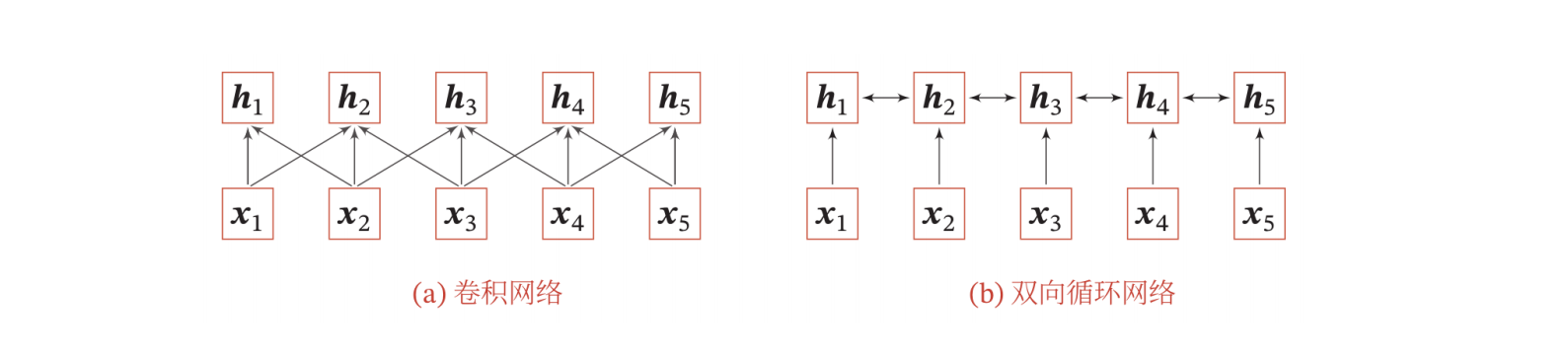
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:一种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互;另一种方法是使用全连接网络。全连接网络是一种非常直接的建模远距离依赖的模型,但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型。
为了提高模型能力,自注意力模型经常采用查询-键-值(Query-Key-Value,QKV)模式:
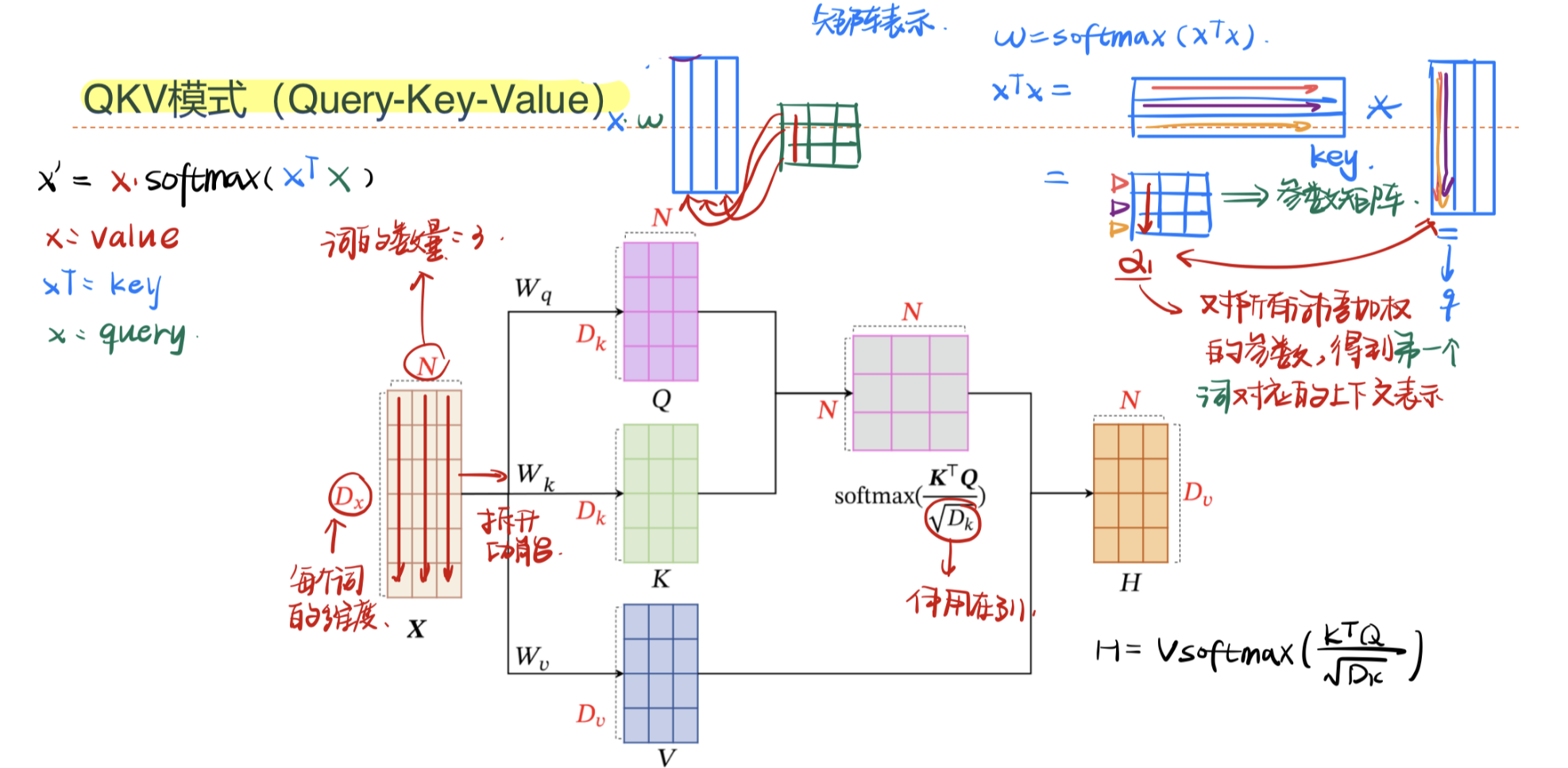
自注意力的计算方式如下:假设输入序列为$\pmb X=[\pmb x_1,…,\pmb x_N]\in \mathbb R^{D_x\times N}$,输出序列为$\pmb H=[\pmb h_1,…,h_N]\in \mathbb R^{D_v \times N}$;自注意力首先会分别与三个权重矩阵相乘,生成$\pmb {Q,K,V}$三个向量序列,分别代表查询向量、键向量和值向量:
$$
\begin{align}
\pmb Q=\pmb W_q\pmb \in \mathbb R^{D_k\times N} \\
\pmb K=\pmb W_k\pmb \in \mathbb R^{D_k\times N} \\
\pmb V=\pmb W_v\pmb \in \mathbb R^{D_v\times N}
\end{align}
$$
通过$\pmb {K,V}$来进行键值对注意力机制求解,获得隐状态$h_n$
$$
\pmb h_n = att((\pmb K,\pmb V),\pmb q_n)=\sum_{j=1}^N\alpha_{nj}\pmb v_j=\sum_{j=1}^N softmax(s(\pmb k_j,\pmb q_n))\pmb v_j
$$
其中$n,j\in[1,N]$为输出和输入向量序列的位置,$\alpha_{nj}$表示第$n$个输出关注到第$j$个输入的权重。自注意力的”自”就来源于查询向量$\pmb Q$是自有的。
如果使用缩放点积来作为注意力打分函数,输出向量序列可以简写为
$$
\pmb H = \pmb V softmax({ {\pmb K^\top \pmb Q} \over {\sqrt{D_k}} })
$$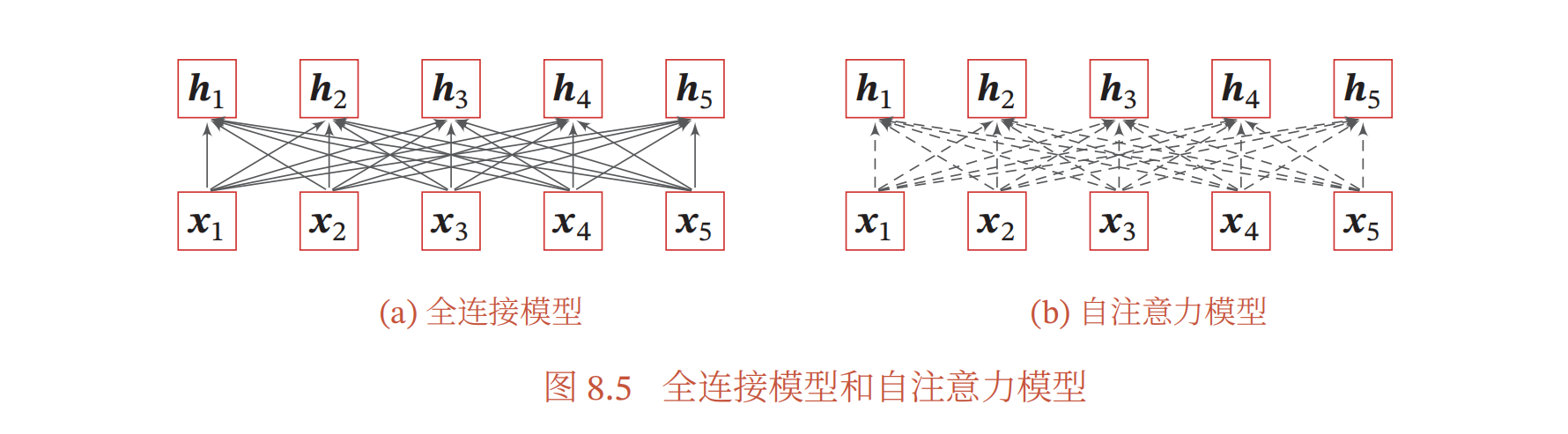
其中实线表示可学习的权重,虚线表示动态生成的权重.由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列。
多头自注意力
自注意力也可以扩展到多头形式,将一个向量矩阵通过不同参数矩阵形成不同的结果,然后拼接起来。
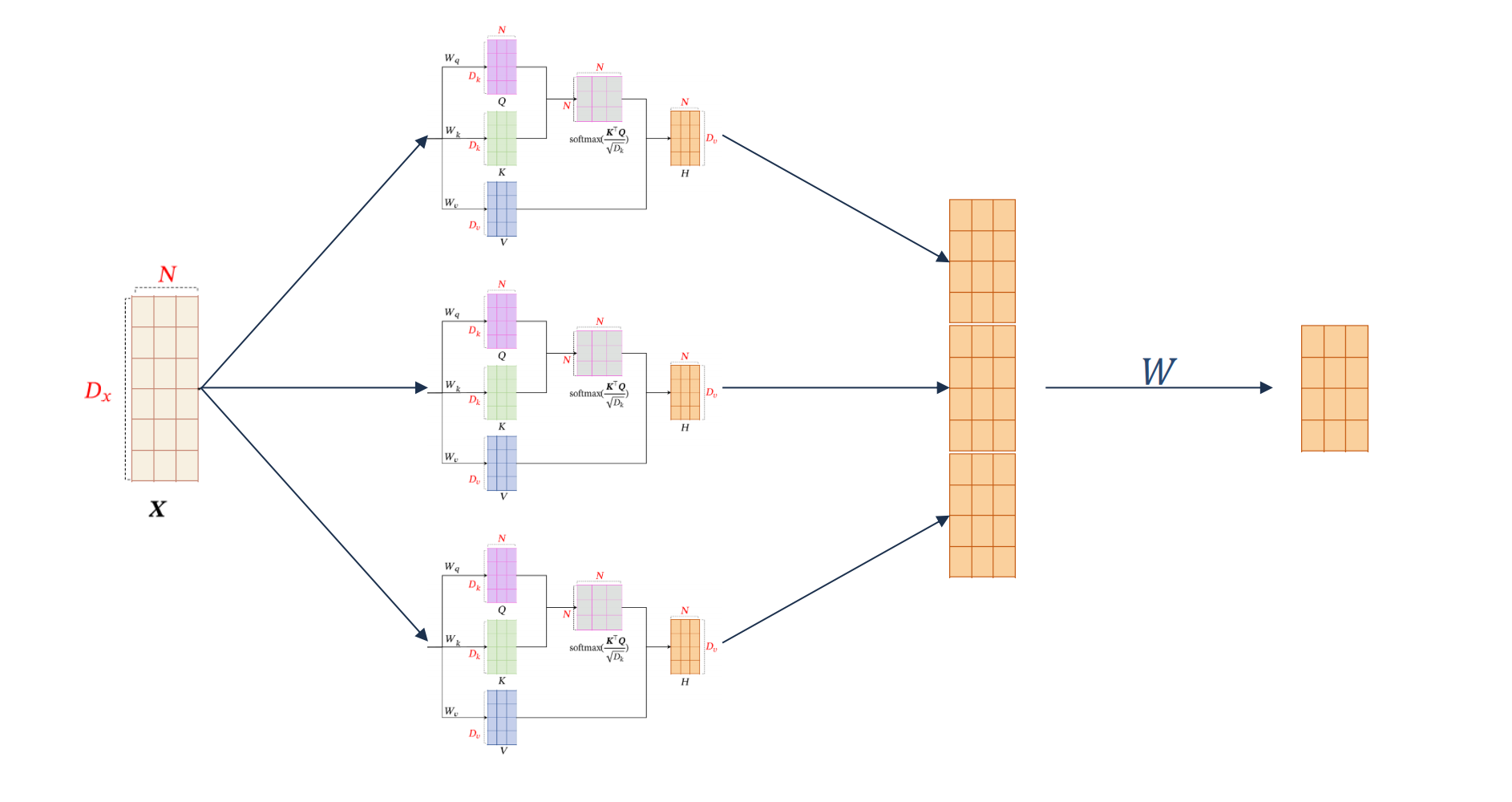
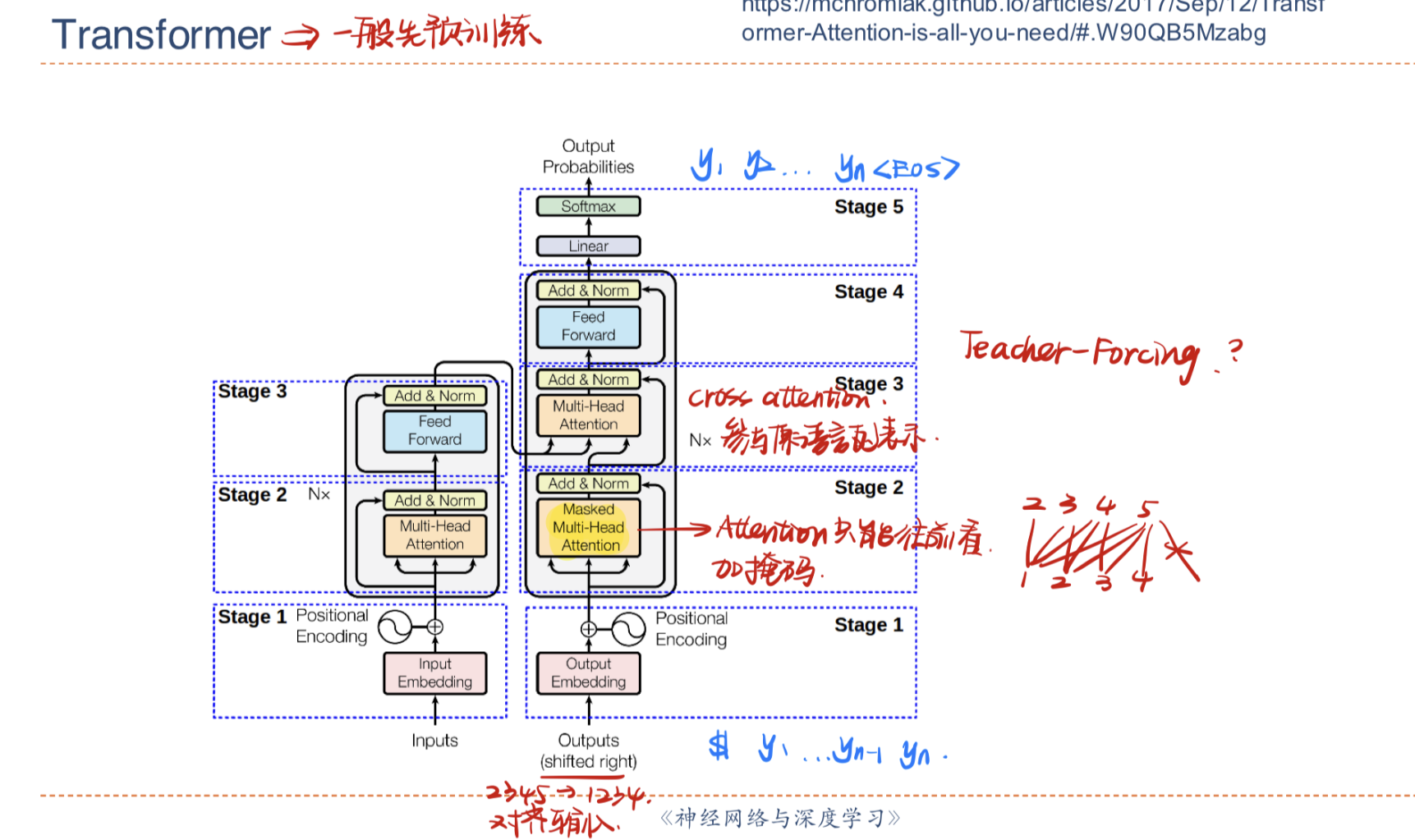
Transformer编码器
自注意力机制通过动态生成权重,解决了变长问题,但丢失了位置信息,因此Transformer引入了位置编码与更多的操作来实现动态权重和位置信息的统一,从而大幅度提高了模型的处理能力。
- 位置编码:在编码前加入位置编码向量,表示位置的相对信息
- 层归一化:防止梯度爆炸
- 直连边:方便线性逼近,提高运行效率
- 逐位FNN:先升维后降维
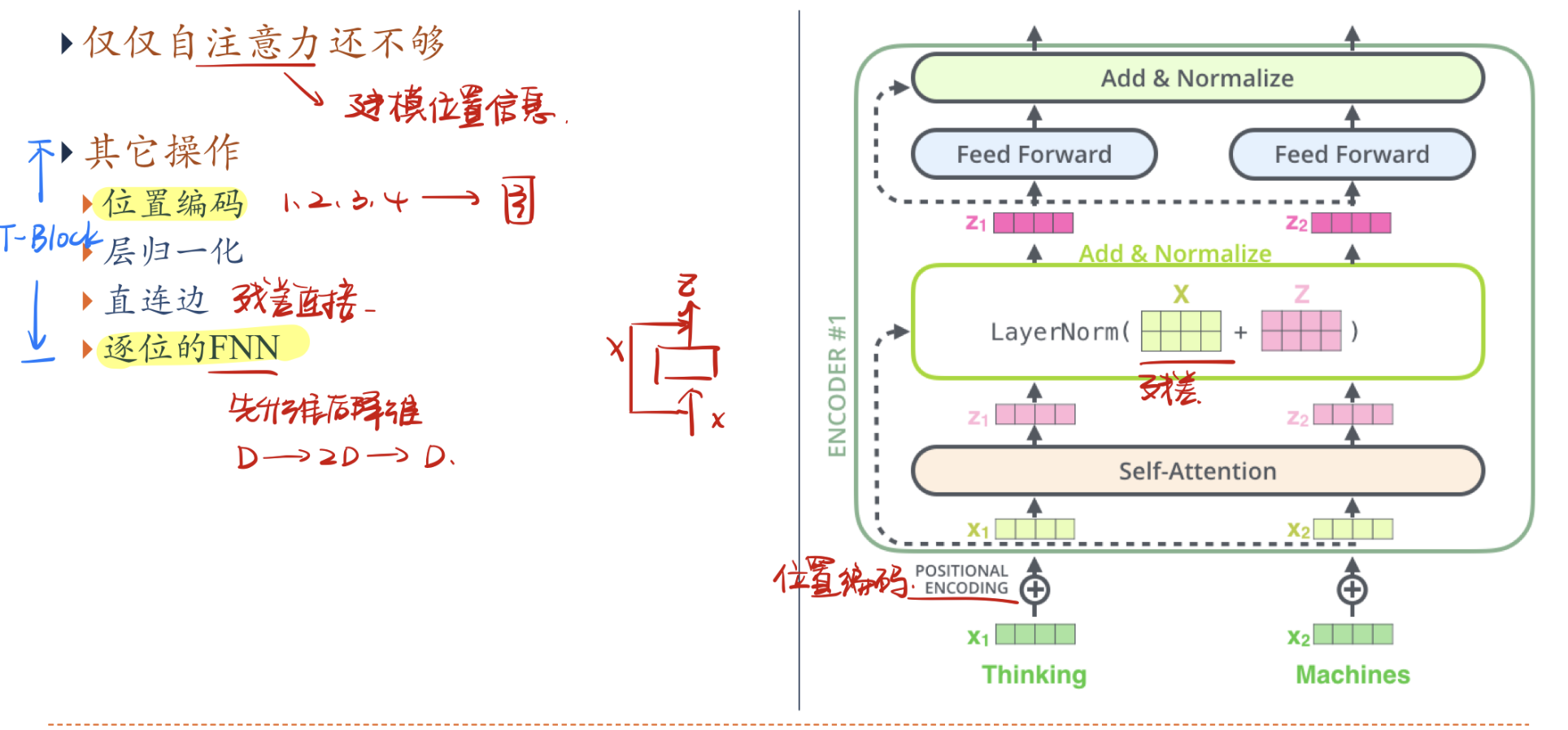
Transformer的过程同样是从一个点位出发,建模与其他点位的关系,且上面的一个编码器可以累加,提高模型的表达能力与处理能力。
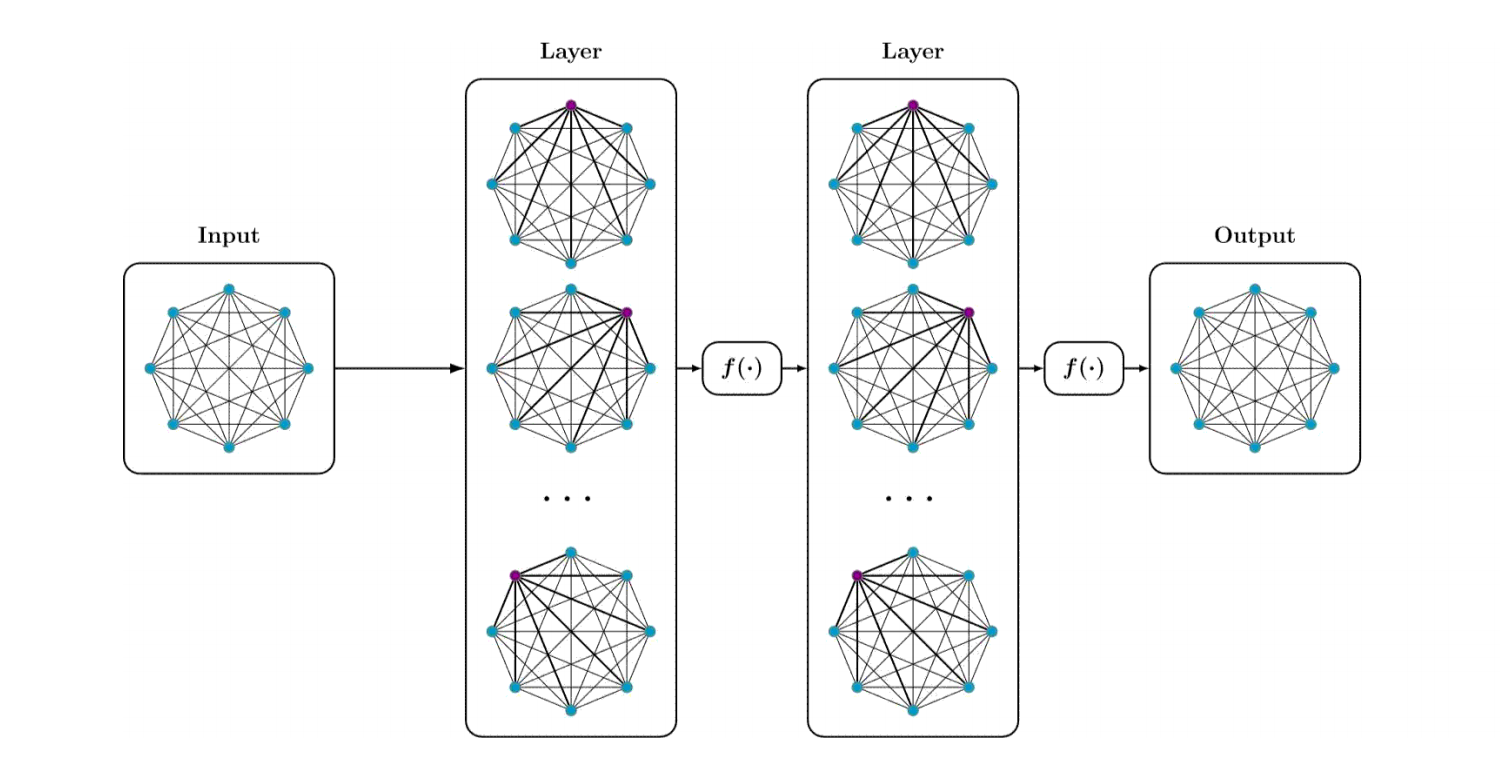

目前,基于Transformer的模型非常非常多,这个还需要以后专门钻研学习。
人脑中的记忆
记忆是人脑对于外界信息做出的内部存储,人脑的记忆过程可以分为工作记忆(短期记忆)、情景记忆、结构记忆(长期记忆),且人脑的记忆特点是联想记忆,即是指一种学习和记住不同对象之间关系的能力。联想记忆是指一种可以通过内容匹配的方法进行寻址的信息存储方式,也称为基于内容寻址的存储。

结构化外部记忆
为了增强网络容量,我们可以引入辅助记忆单元,将一些和任务相关的信息保存在辅助记忆中,在需要时再进行读取,这样可以有效地增加网络容量.这个引入的辅助记忆单元一般称为外部记忆。
外部记忆主要由主网络、外部记忆和读写操作三部分构成,
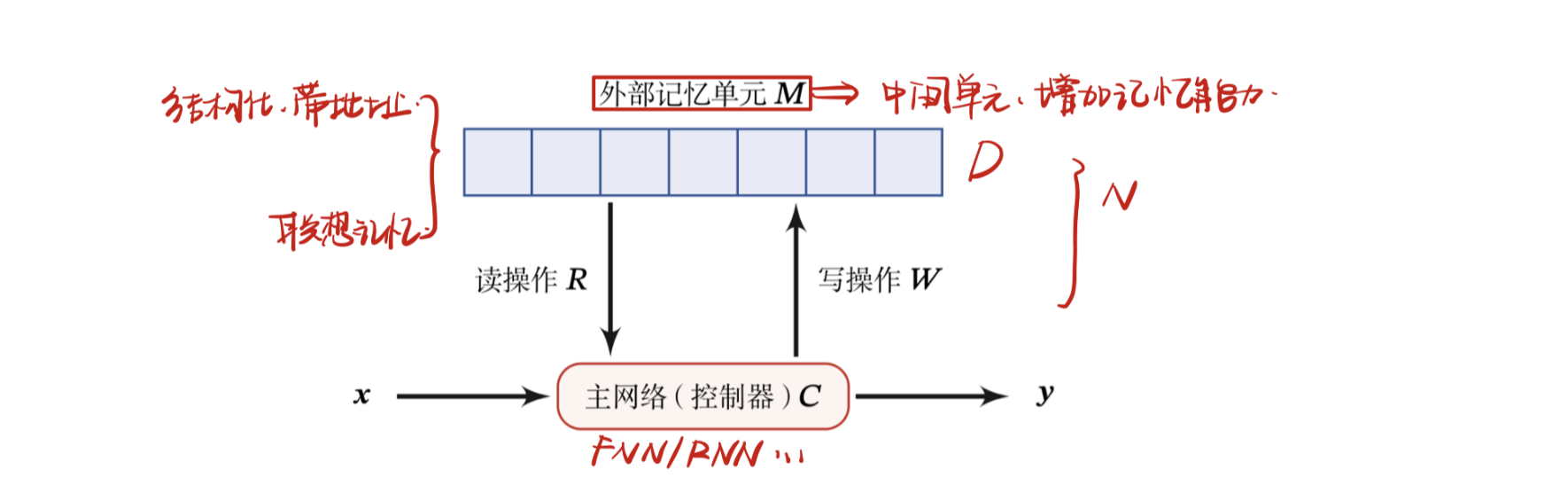
外部记忆定义为矩阵$M\in R^{d\times k}$,其中$k$是记忆片段的数量,$d$是每个记忆片段的大小;外部记忆的类型可以分为:
- 只读
- 记忆网络:专用于存储的网络结构
- RNN中的$h_t$:用循环网络的隐状态存储部分信息
- 可读写
- NTM
要实现类似于人脑神经网络的联想记忆能力,就需要按内容寻址的方式进行定位,然后进行读取或写入操作.按内容寻址通常使用注意力机制来进行。通过引入外部记忆,可以将神经网络的参数和记忆容量“分离”,即在少量增加网络参数的条件下可以大幅增加网络容量.因此,我们可以将注意力机制看作一个接口,将信息的存储与计算分离。
记忆网络
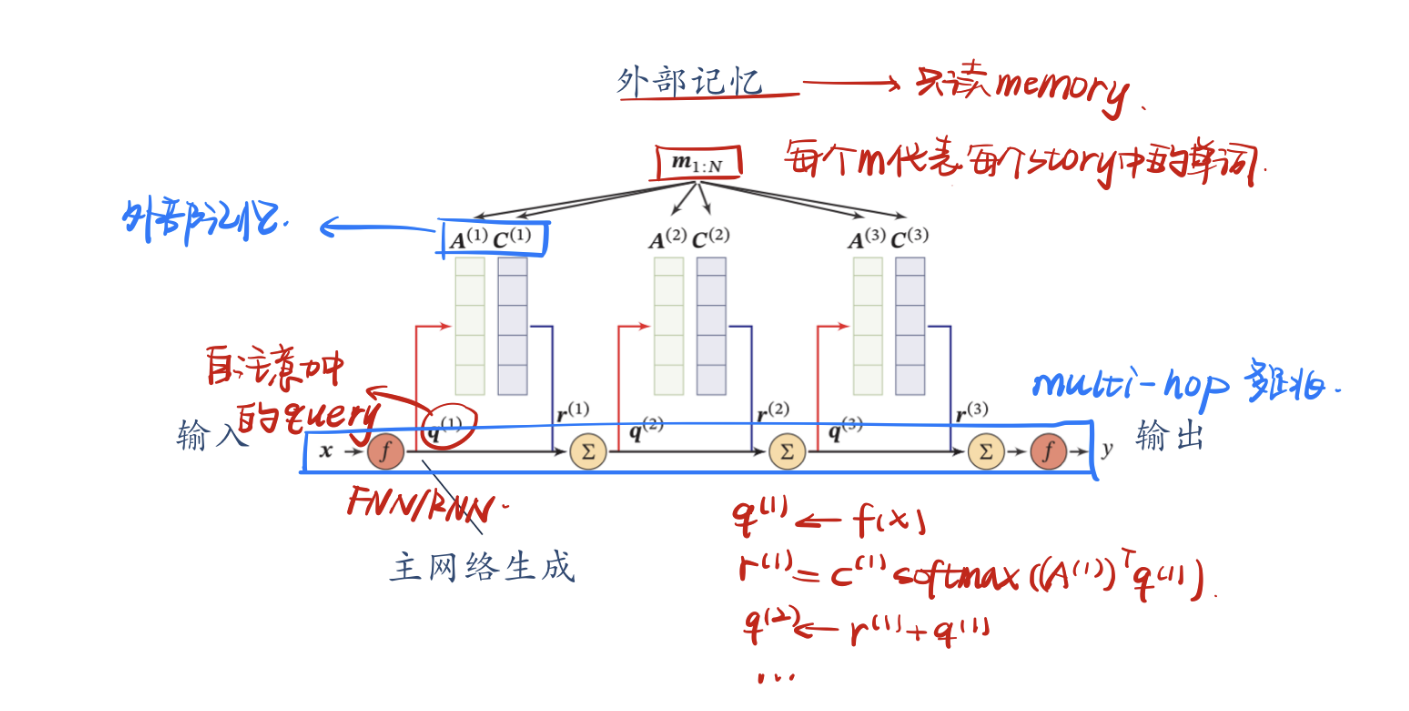
端到端记忆网络采用一种可微的网络结构,可以多次从外部记忆中读取信息。在端到端记忆网络中,外部记忆单元是只读的。为了实现更复杂的计算,我们可以让主网络和外部记忆进行多轮交互。
给定一组需要存储的信息$m_{1,N}$,外部记忆首先将其分成寻址片段$A=[\pmb a_1,…,\pmb a_n]$和输出片段$C=[\pmb c_1,…,\pmb c_n]$。开始阶段,主网络接收输入$\pmb x$并通过预测函数$f(·)$,生成输入$\pmb q_1=f(\pmb x)$,然后执行下面的步骤:
使用键值对注意力从外部记忆读取相关信息
$$
\pmb r^{(k)}=\pmb C^{(k)}softmax(\pmb A^{(k)}\pmb q^{(k)})
$$整合注意力读取的结果,生成新的查询向量
$$
\pmb q^{(k+1)}=\pmb r^{(k)}+\pmb q^{(k)}
$$
以上过程可以迭代$K$次,以实现复杂计算。
神经图灵机
图灵机是一种抽象数学模型,主要用来模拟任何可计算问题,通过控制器从无限长的纸带上读写记忆。
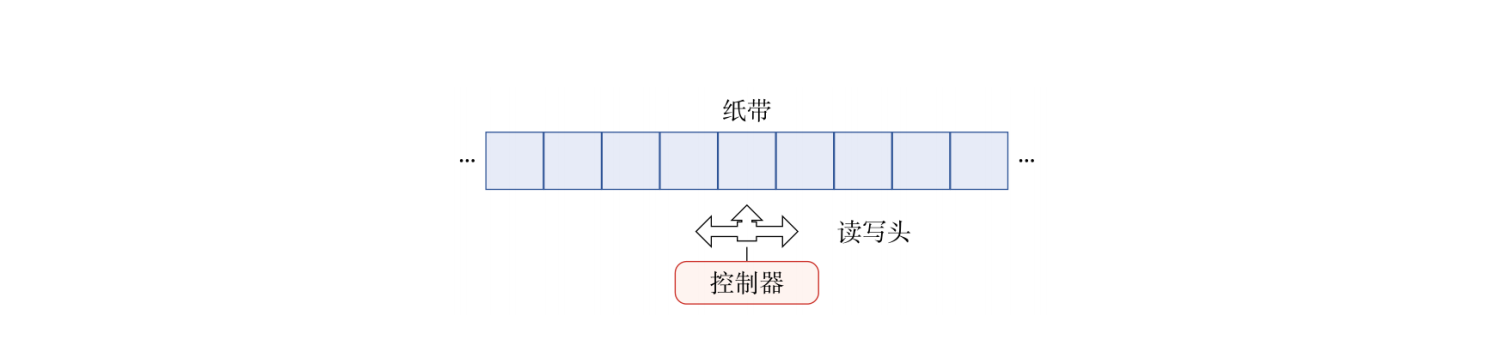
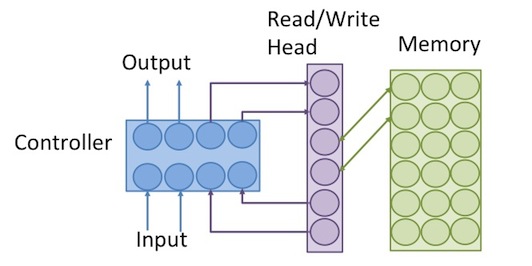
图灵机由控制器、符号表、读写头、寄存器和纸带五个部分组成,其中可以看出当今计算机架构的一些影子,而神经图灵机基于此,主要由两个部件构成:控制器和外部记忆。其中控制器通过读写操作完成对外部记忆的处理和读取,外部记忆定义为矩阵$M\in \mathbb R^{D\times N}$,其中$D$表示记忆片段大小,$N$表示记忆片段数量;控制器为一个前馈或循环神经网络。整个架构是可微分的。
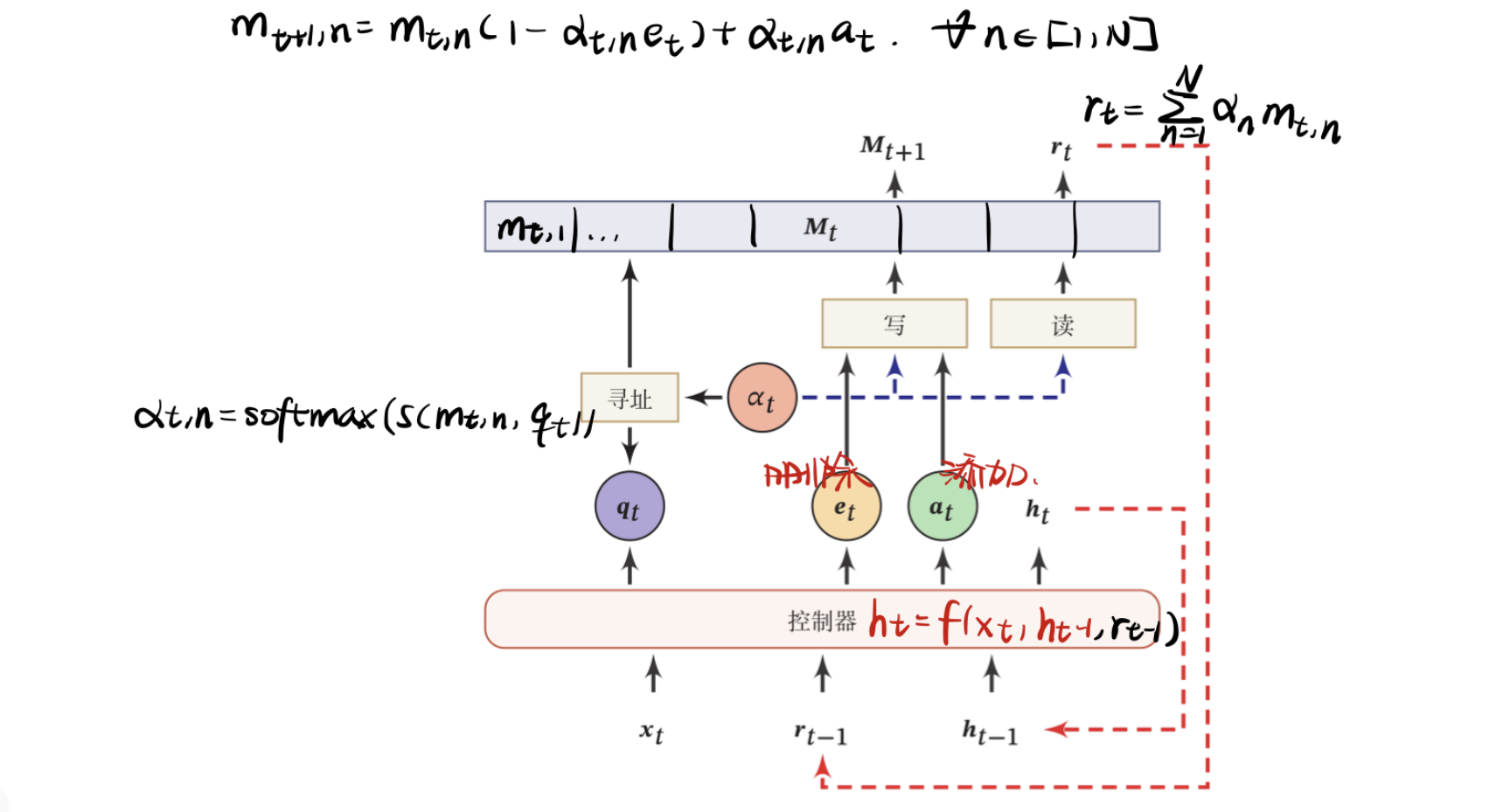
神经图灵机在每个时刻$t$,控制器接受当前时刻的输入$\pmb x_t$、上一时刻的输出$\pmb h_{t-1}$和上一时刻从外部记忆中读取的信息$\pmb r_{t-1}$,并产生输出$\pmb h_t$,同时生成和读写外部记忆相关的三个向量:查询向量$\pmb q_t$、删除向量$\pmb e_t$和增加向量$\pmb a_t$.然后对外部记忆$\pmb M_t$进行读写操作,生成读向量$\pmb r_t$和新的外部记忆$\pmb M_{t+1}$。
读操作
在时刻$t$,外部记忆的内容为$\pmb M_t=[\pmb m_{t,1},…,\pmb m_{t,N}]$,读操作为从外部记忆$\pmb M_t$中读取信息$\pmb r_t\in\mathbb R^D$,首先通过注意力机制来进行基于内容的寻址,即
$$
\alpha_{t,n}=softmax(s(\pmb m_{t,n},\pmb q_t))
$$
根据注意力分布$\alpha_t$,可以计算读向量$\pmb r_t$,作为下一个时刻控制器的输入:
$$
\pmb r_t=\sum_{n=1}^N \alpha_n \pmb m_{t,n}
$$
写操作
外部记忆的写操作可以分解为两个子操作:删除和增加,分别基于删除向量和增加向量按比例操作。通过写操作得到下一时刻的外部记忆$\pmb M_{t+1}$
$$
\pmb m_{t+1,n}=\pmb m_{t,n}(1-\alpha_{t,n}\pmb e_t)+\alpha_{t,n}\pmb a_{t,n}\ \ \ \ \forall n\in[1,N]
$$
基于神经动力学的联想学习
结构化的外部记忆更多是受现代计算机架构的启发,将计算和存储功能进行分离,这些外部记忆的结构也缺乏生物学的解释性。为了具有更好的生物学解释性,还可以将基于神经动力学(Neurodynamics)的联想记忆模型引入到神经网络以增加网络容量。
自联想和异联想
联想记忆模型(Associative Memory Model)主要是通过神经网络的动态演化来进行联想,有两种应用场景.
- 输入的模式和输出的模式在同一空间,这种模型叫作自联想模型(Auto Associative Model)。自联想模型可以通过前馈神经网络或者循环神经网络来实现,也常称为自编码器(Auto-Encoder,AE)。
- 输入的模式和输出的模式不在同一空间,这种模型叫作异联想模型(Hetero-Associative Model).从广义上讲,大部分机器学习问题都可以被看作异联想,因此异联想模型可以作为分类器使用。
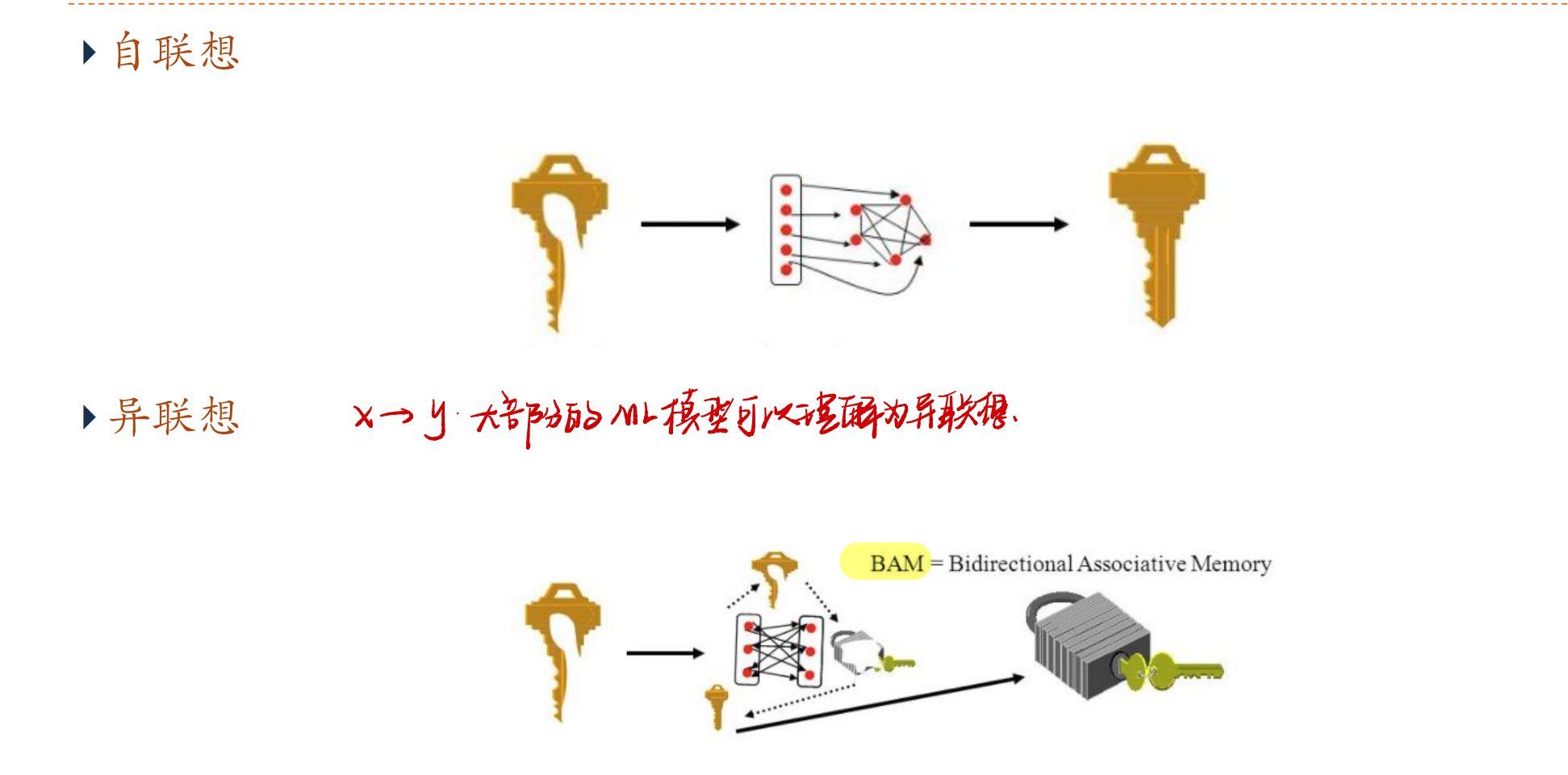
Hopfield网络
hopfield网络将神经网络作为记忆的存储和检索模型,是一种循环神经网络模型,由一组互相连接的神经元组成。Hopfield 网络也可以认为是所有神经元都互相连接的不分层的神经网络。每个神经元既是输入单元,又是输出单元,没有隐藏神经元。一个神经元和自身没有反馈相连,不同神经元之间连接权重是对称的。
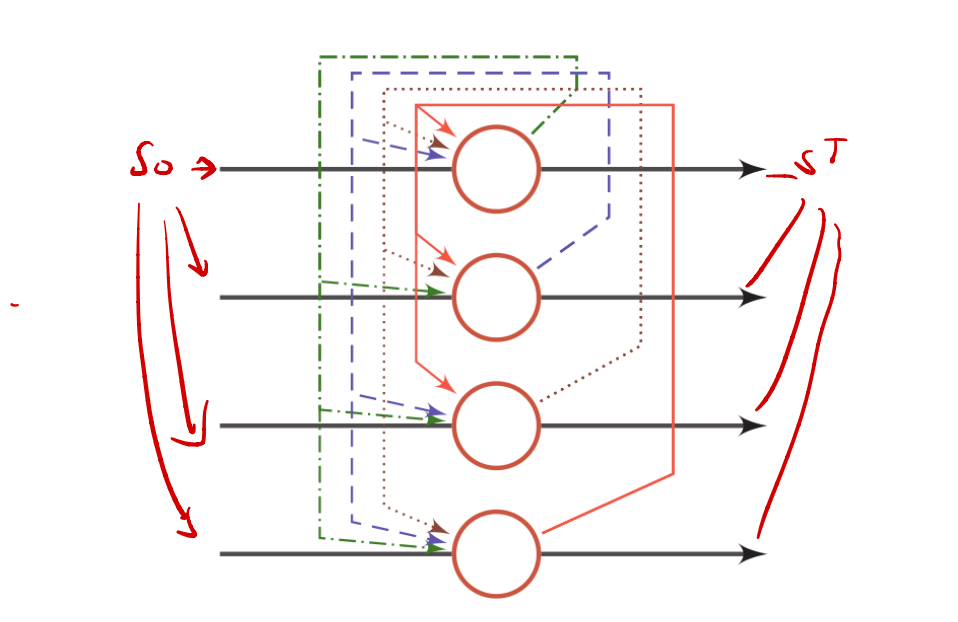
更新规则
假设一个Hopfield网络有$M$个神经元,第$i$个神经元的更新规则为:
$$
s_i=\begin{cases} +1 \ \ \ \ if \sum_{j=1}^Mw_{ij}s_j+b_i\ge0 \\ -1 \ \ \ \ otherwise, \end{cases}
$$
其中
$$
\begin{cases}w_ii=0 \ \ \ \ \forall i\in[1,M] \\ w_{ij}=w_{ji} \ \ \ \ \forall i,j\in[1,M]\end{cases}
$$
从$s_i$的更新方式中可以看出Hopfield网络的规则是使用相邻单元的权重进行更新,每次做线性加和。更新方式中,异步更新每次更新一个神经元,其可以随机或者固定;同步更新一次性更新所有神经元,更新时满足非线性阶跃函数$f(·)$
$$
\pmb s_t=f(\pmb W\pmb s_{t-1}+\pmb b)
$$
其中$\pmb s_0=\pmb x,\pmb W=[ w_{ij} ]_ { M\times M }$为连接权重,$\pmb b=[b_i]_ {M \times 1}$为偏置向量。
能量函数
在Hopfield网络中,我们给每个不同的网络状态定义一个标量属性,称为“能量”。
$$
E=-{1\over 2}\sum_{i,j}w_{ij}s_is_j-\sum_ib_is_i = -{1\over 2}\pmb{s^\top Ws-b^\top s}
$$
符合物理规律,Hopfield网络应该是稳定的,即能量函数经过多次迭代后会达到收敛状态。权重对称是一个重要特征,因为它保证了能量函数在神经元激活时单调递减,而不对称的权重可能导致周期性振荡或者混乱。
检索过程(联想记忆)
给定一个外部输入,网络经过演化会达到某个稳定状态。Hopfield网络存在有限的吸引点(Attractor),即能量函数的局部最小点。
检索过程如下:
- 每个吸引点$\pmb u$都对应一个“管辖”区域$\mathcal R_{\pmb u}$.若输入向量$\pmb x$落入这个区域,网络最终会收敛到$\pmb u$。
- 吸引点可以看作是网络中存储的信息。
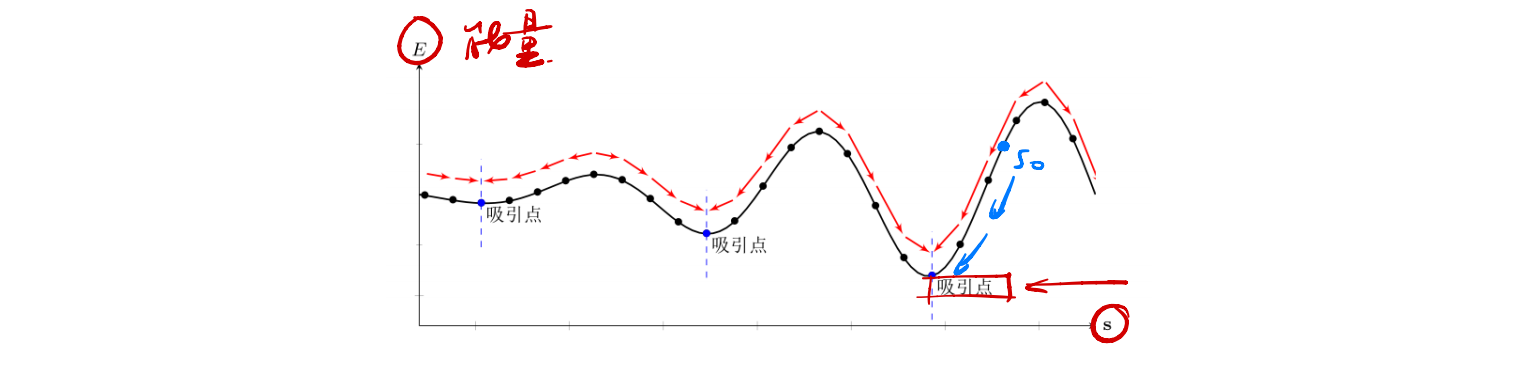
存储过程
信息存储是指将一组向量$\pmb x_1,…,\pmb x_N$存储在网络中的过程,存储过程主要是调整神经元之间的连接权重,因此可以看作是一种学习过程。
神经元$i$和$j$之间的连接权重为:
$$
w_{ij}={1\over N}\sum_{n=1}^N x_i^{(n)}x_j^{(n)}
$$
其中$x_i^{(n)}$是第$i$个神经元的第$n$个分量。这个公式表达了这样的意思:如果两个神经元经常同时激活,则它们之间的连接会加强;否则则会消失。这种学习方式和人脑的赫布法则十分的类似。权重的更新公式可以使得权重更新时所得到的能量相对最低,其证明可以将能量式在权重$w_{ij}$上求导。
这种通过神经元之间权重来存储的方式,其存储容量相对有限,模型容量一般与网络结构和学习方式有关。Hopfield 网络的最大容量为$0.14M$,玻尔兹曼机的容量为$0.6m$, 但是其学习效率比较低,需要非常长时间的演化才能达到均衡状态。
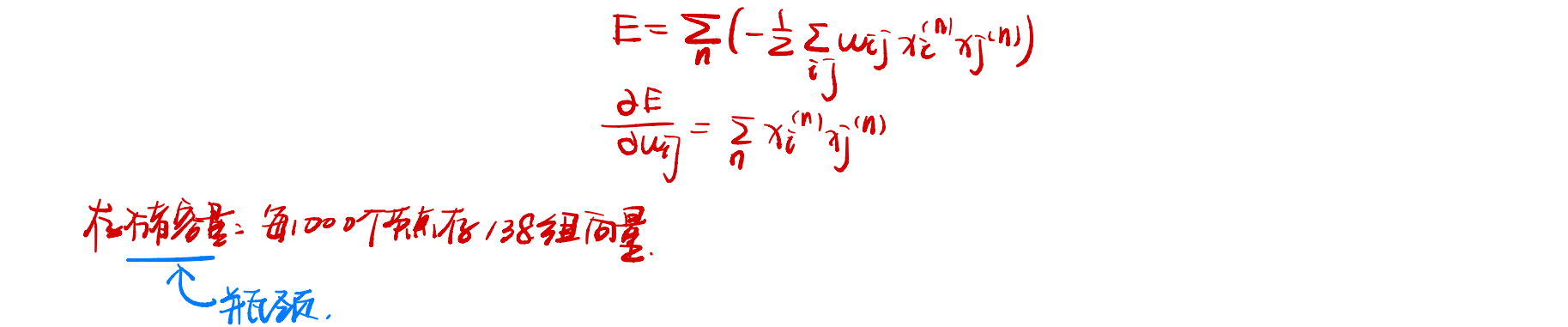
联想记忆增加网络容量
既然联想记忆具有存储和检索功能,我们可以利用联想记忆来增加网络容量。和结构化的外部记忆相比,联想记忆具有更好的生物学解释性。比如,我们可以将一个联想记忆模型作为部件引入 LSTM 网络中,从而在不引入额外参数的情况下增加网络容量。