无监督学习笔记
本文最后更新于:几秒前
无监督学习
监督学习旨在建立从数据到预测的一个映射,而无监督学习是指从无标签的数据中学习出一些有用的模式。无监督学习算法一般直接从原始数据中学习,不借助于任何人工给出标签或者反馈等指导信息。
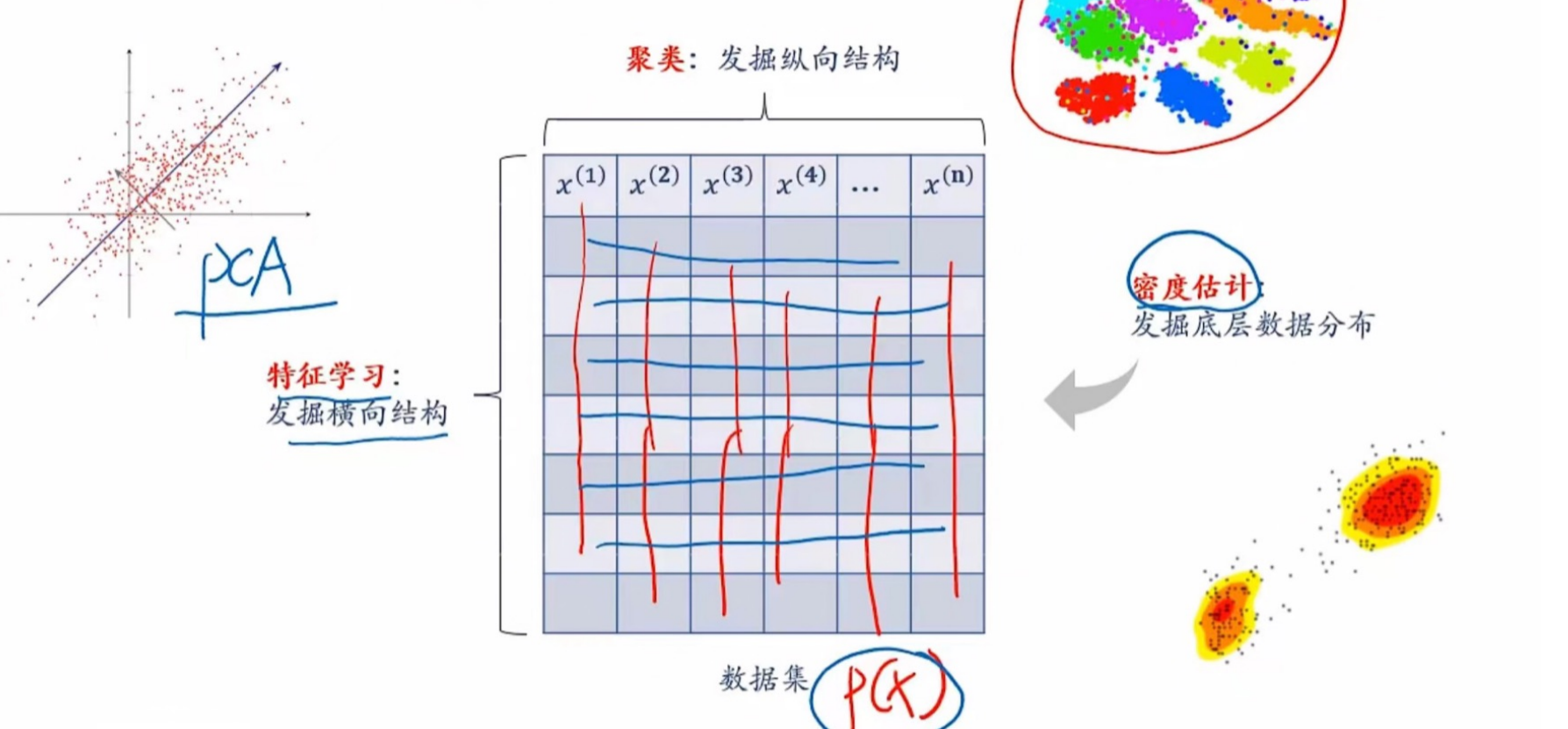
无监督学习按现有类别可以分为:
- 特征学习:从无标签的训练数据中挖掘有效的特征或表示,一般用于降维、数据可视化、数据预处理等;
- 聚类:将具有相似性的忘本划归为同一类,旨在建立从无标签数据到聚类预测结果的映射;
- 密度估计:是根据一组训练样本来估计样本空间的概率密度,可分为参数密度估计和非参数密度估计,通过数据挖掘底层分布。
聚类
聚类是指将样本集合中相似的样本分配到相同的类/簇(cluster),不同的样本分配到不同的类/簇,使得类内样本间距较小而类间样本间距较大。其中,类间距和相似度等参数都是一种主观定义,有多种表示方式。
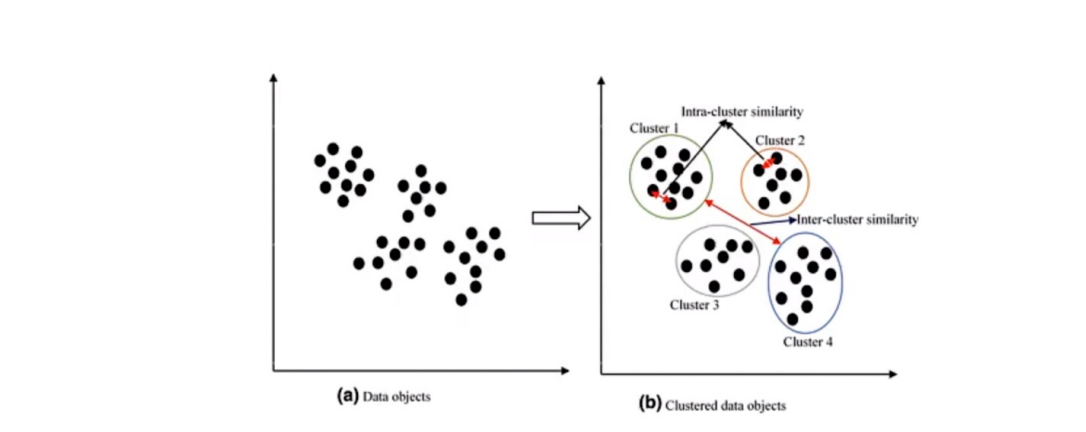
聚类常见应用于图像分割、文本聚类、社交网络分析等。
概念
样本间距离
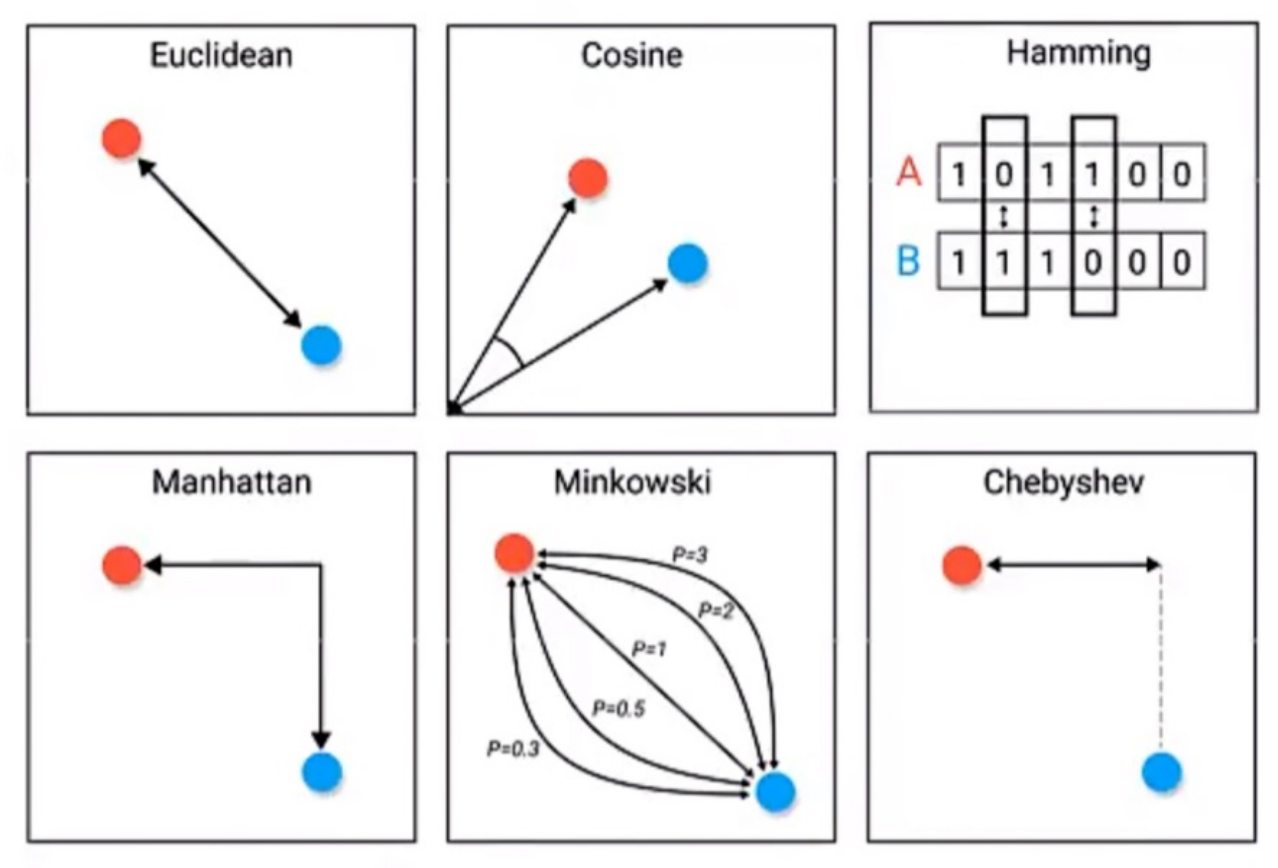
样本间的距离用于表示样本间的相似性,样本可以视做一个个点,而距离的表示方法有多样,如$L1/L2$距离、余弦距离、相关系数、汉明距离等。
类/簇
类/簇没有一个严格的定义,可以理解为一组相似的样本,用于提取相似度较高样本组的信息。
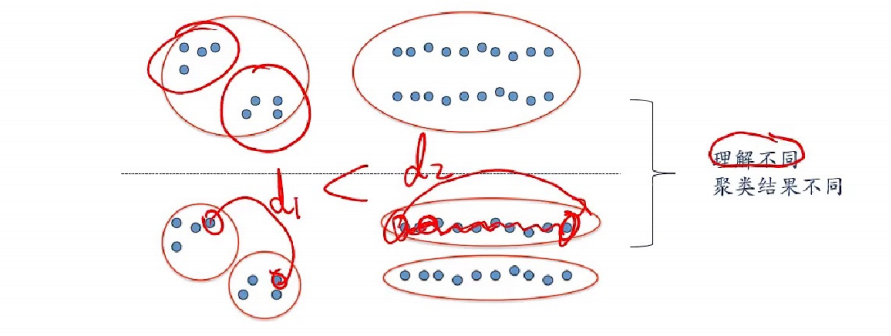
类内间距
类内间距可以用样本间平均距离或样本间最大距离表示。
样本间平均距离
$$
avg(C)={2 \over {|C|(|C|-1)} } \sum_{1\le i \lt j \le |C|} d_{ij}
$$样本间最大距离
$$
dia(C)=\max_{1\le i \lt j \le |C|}d_{ij}
$$
类间间距(设为$C_p$、$C_q$)
类间间距可以用样本间的最短距离和均值间距离表示。
样本间最短距离
$$
D_{pq}=\min \lbrace d_{ij}|x^{(i)}\in C_p,x^{(j)}\in C_q \rbrace
$$样本均值间距离
$$
D_{pq}=d_{\mu_p\mu_q}
$$
聚类指标
外部指标
指有外部因素用于参考聚类结果,即已知标签$y$,其作为最后的评价标准。常见的外部指标有$Jaccard$系数、$FM$系数、$Rand$系数等;

内部指标
指评价体系只基于内部数据,无外部参考聚类结果,如$Dunn$指数、$DB$指数等
$$
DBI={1\over k}\sum_{i=1}^k \max_{j\ne i} { {avg(C_i)+avg(C_j)} \over {d_{\mu_i\mu_j}} }
$$
在$DB$系数中,如上式所示,类内间距是分子部分,类间间距是分母部分,$DB$系数希望类内越近越好,类间越远越好,整理越小越好;$\max$代表其取的是所有$i \ne j$的最坏情况下的最小,保证其普适性成立。
聚类方法
常见聚类方法有K均值聚类、层次聚类、密度聚类、谱聚类等;
k均值聚类
K均值的目标函数为:
$$
E=\sum_{i=1}^k\sum_{x\in C_i}||x-\mu_i||^2_2
$$
其中$\mu_i$是第$i$个簇$C_i$的均值向量,$E$值刻画了簇内样本围绕簇均值向量的紧密程度。
K均值聚类的过程分为两步
1)选择K个点作为聚类中心
- 根据与聚类中心的距离对每个样本点进行聚类
- 求每类样本的平均值作为该类别的新的聚类中心
2)不断迭代1和2,直至收敛(每个样本类别不再改变或其他更为宽松的条件)
对于K均值聚类的收敛性,由于其需要两个步骤不断迭代优化,其属于NP-Hard问题:
- 固定均值向量,优化聚类划分(第1步)
- 固定聚类划分,优化均值向量(第2步)
对于K均值聚类的超参,K的选择可以基于经验,类中心的初始化过程可以按照一定策略,如大于最小间距的随机点/样本点、K个相互距离最远的样本点、K个等距网格点等。
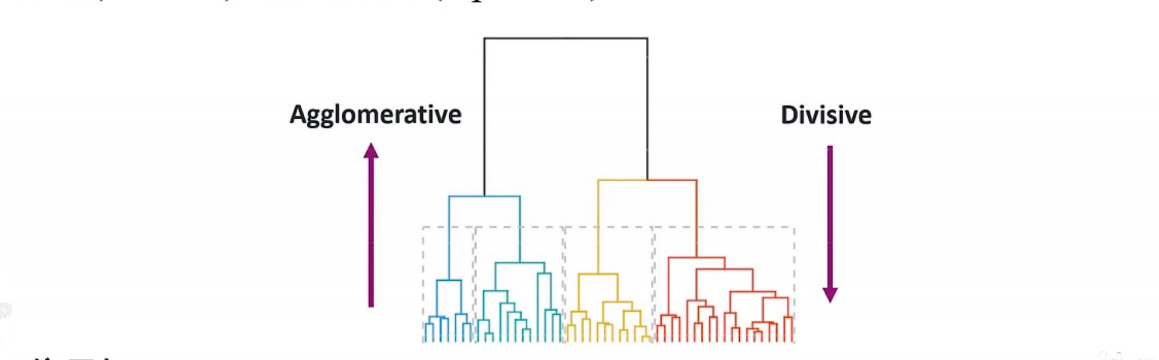
层次聚类
层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次地嵌套聚类树,嵌套策略可以是聚合(自底向上)或者分裂(自顶向下)
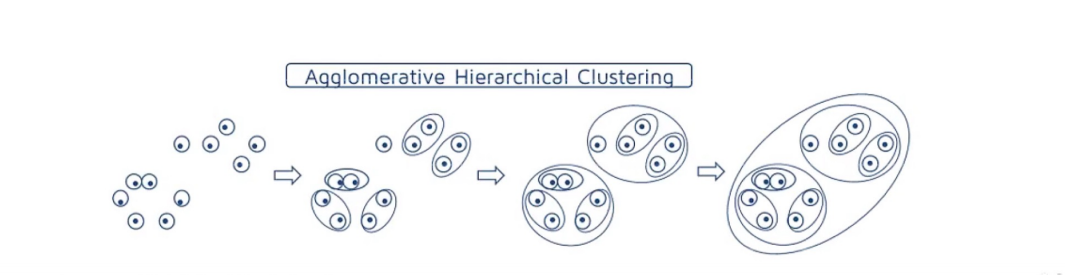
聚合过程先将每个样本分到单独的类,然后不断迭代合并过程直至满足终止条件:
- 计算两两类簇之间的距离,找到距离最小的两个类簇$c_1$和$c_2$
- 合并类簇$c_1$和$c_2$
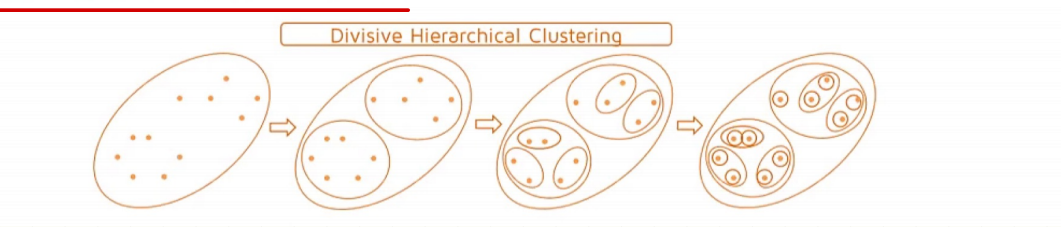
分裂过程和聚合过程相反,先将所有样本划归到同一个类,然后不断分裂直到满足终止条件:
- 在同一个类簇(记为$c$)中计算两两样本之间的距离,找出距离最远的两个样本$a$和$b$
- 将样本$a$、$b$分配到不同类簇$c_1$和$c_2$中
- 计算原类簇$c$中剩余的其他样本点和$a$、$b$的距离,若是$dis(a)<dis(b)$则将样本点归到$c_1$,否则归到$c_2$。
其余两种方法不在这里继续叙述。
无监督特征学习
无监督特征学习一般遵循着先编码后解码,其目的在于提取有用特征,以去噪、降维、数据可视化等应用。
主成分分析(PCA)
数据的原始特征可能存在维度高、冗余等问题,其会直接导致维度灾难和学习效果降低,因此需要采用特征学习的方式进行降维,一种最常用的数据降维方法就是投影,将数据映射到另一个域,其中以线性投影应用最广。
$$
\pmb z=\pmb W^\top\pmb x
$$
并满足对称性,以降低冗余
$$
\pmb W^\top \pmb W=I
$$
主成分分析是特征学习在降维领域的一个经典应用,其优化原则为
- 最大投影方差:使得在转换后的空间中的数据方差最大,尽可能多的保留原数据的信息;
- 最小重构误差:使得样本点到超平面的距离足够近,降低重构难度。
样本点$\pmb x^{(n)}$投影之后的表示为
$$
z^{(n)}=\pmb w^\top \pmb x^{(n)}
$$
所有样本点投影之后的方差为
$$
\begin{align}
\sigma(\pmb {X};\pmb w)&={1\over N}\sum_{n=1}^N(\pmb w^\top\pmb x^{(n)}-\pmb w^\top \pmb {\overline x})^2 \\
&={1\over N}\sum_{n=1}^N(\pmb w^\top\pmb X-\pmb w^\top\pmb {\overline X})(\pmb w^\top\pmb X-\pmb w^\top\pmb {\overline X})^\top\\
&=\pmb w^\top \Sigma \pmb w
\end{align}
$$
其中$\Sigma$是原始空间中$X$的协方差矩阵,对上式方差做拉格朗日乘子法,可得目标函数
$$
\max_\omega\pmb w^\top \Sigma \pmb w+\lambda(1-\pmb w^\top\pmb w)
$$
对目标函数求导并令导数等于0,可得:
$$
\Sigma \pmb w=\lambda\pmb w
$$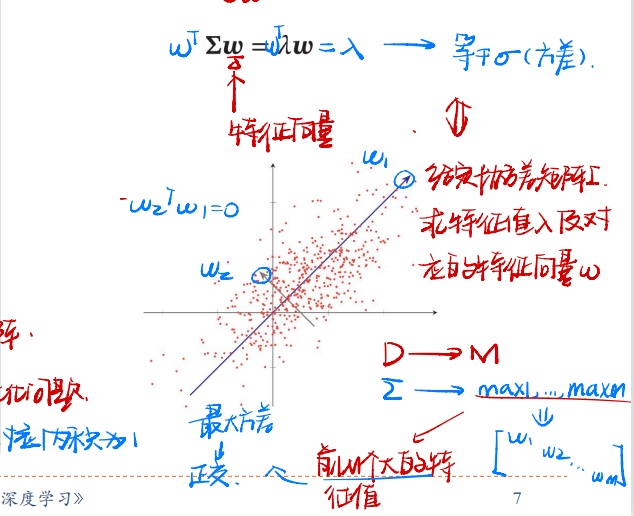
从这个式子可以看出,PCA的目标函数过程可以视为:给定协方差矩阵$\Sigma$,求特征值$\lambda$及对应的特征向量$\pmb w$,这种求解过程可以推广到多维,如果要通过投影矩阵$\pmb W\in R^{D\times D’}$将样本投到$D’$维空间,投影矩阵满足$\pmb{W^\top W=I}$为单位阵,只需要将$\Sigma$的特征值从小到大排列,保留前$D’$个特征向量,其对应的特征向量即是最优的投影矩阵
$$
\pmb \Sigma\pmb W=\pmb Wdiag(\pmb \lambda)
$$
提高两类可分性的方法一般为监督学习方法,比如线性判别分析(LDA)。
稀疏编码
(线性)编码
(线性)编码定义为:给定一组基向量$A=[\pmb a_1,…,\pmb a_M]$,将输入样本$\pmb x$表示为这些基向量的线性组合。
$$
\pmb x=\sum_{m=1}^M z_m \pmb a_m = \pmb {Az}
$$
即,数据可以分为字典$\pmb A$和编码$\pmb z$,通过字典来实现对数据的编码。编码是对$D$维空间中的样本$\pmb x$找到其在$P$维空间中的表示或投影,其目标通常是编码的各个维度都是统计独立的,并且可以重构出输入样本。编码的优化目标为:
$$
\sum_{n=1}^N||\pmb A\pmb z^{(n)}-\pmb x^{(n)}||
$$
迭代时,不断重复“固定一个求另外一个”的过程,即交替求解$\pmb A$和$\pmb z$直到收敛。
完备性
如果$M$个基向量刚好可以支撑$M$维的欧氏空间,则这$M$个基向量是完备的;如果$M$个基向量可以支撑$D$ 维的欧氏空间,并且$M>D$,则这$M$个基向量是过完备的(overcomplete)、冗余的.“过完备”基向量是指基向量个数远远大于其支撑空间维度。因此这些基向量一般不具备独立、正交等性质。
- 当$M>D$时,能找到多个完备解且其重构方差为0;
- 当$M<D$时,不能找到解,欠完备。
稀疏编码
稀疏编码目标是找到一组“过完备”的基向量来进行编码,少数基向量就可以表示原问题的所有信息。少数基向量的加权可以构成原始解。
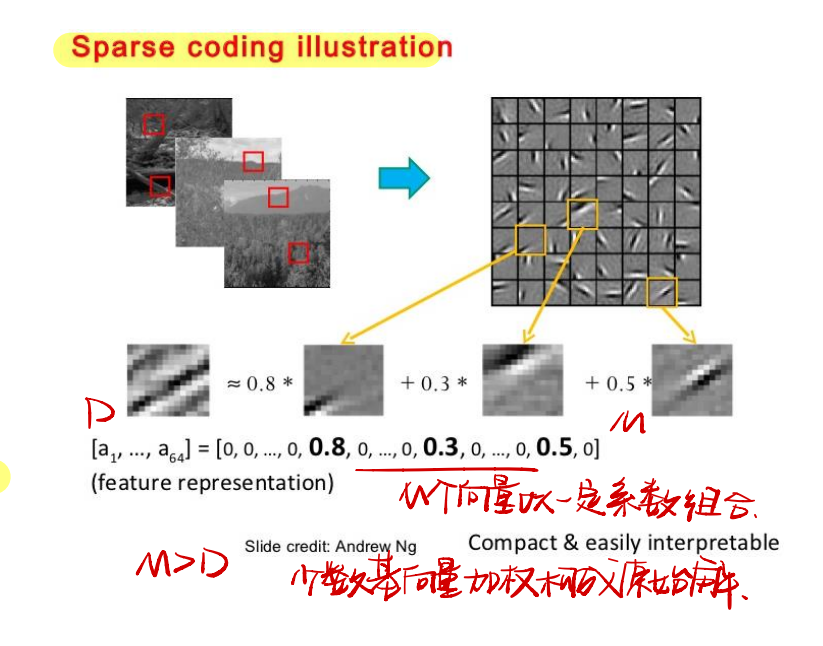
给定一组$N$个输入向量的$\pmb x^{(1)},…,x^{(n)}$,其稀疏编码的目标函数为:
$$
\mathcal L(\pmb A,\pmb Z)=\sum_{n=1}^N(||\pmb x^{(n)}-\pmb A\pmb z^{(n)}||^2+\eta\rho(\pmb z^{(n)}))
$$
其中,$\rho(·)$是一个稀疏性衡量函数,$\eta$是一个超参数,用于控制稀疏性的强度,目标函数的前半部分表示重构误差,后半部分是稀疏性的衡量,整体其实和梯度下降添加正则化的目标函数比较类似,一部分是具体目标,一部分是防止过度。
$\rho(·)$的定义有很多种。
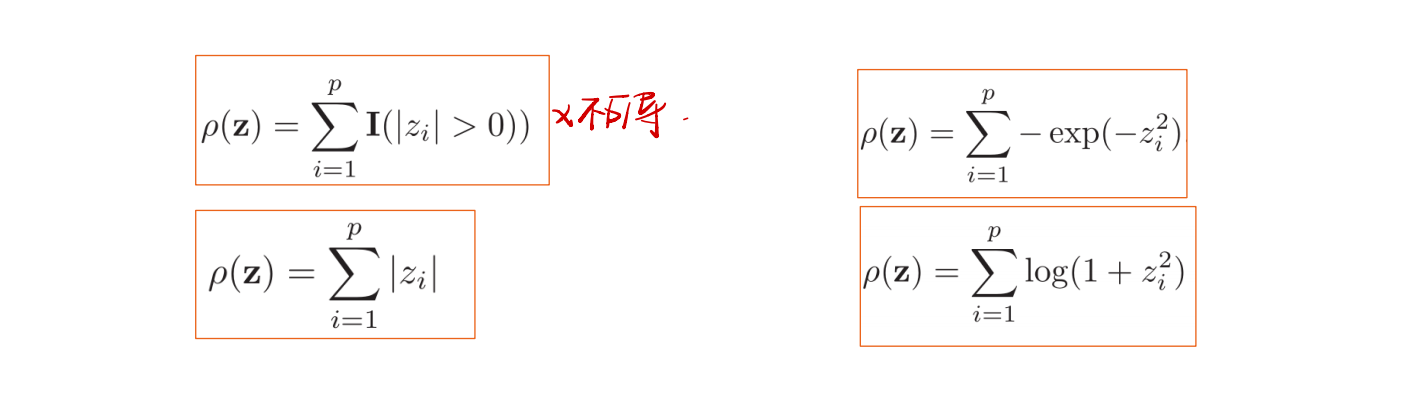
稀疏编码的训练过程分为两步,一般采用交替优化的方法进行。
固定基向量$\pmb A$,对每个输入$\pmb x^{(n)}$,计算其对应的最优编码
$$
\min_{\pmb z^{(n)}}||\pmb x^{(n)}-\pmb {Az}^{(n)}||^2+\eta\rho(\pmb z^{(n)}), \forall n\in[1,N]
$$固定上一步得到的编码$\lbrace \pmb z^{(n)} \rbrace_{n=1}^N$,计算其最优基向量
$$
\min_{\pmb A}\sum_{n=1}^N(||\pmb x^{(n)}-\pmb {Az}^{(n)}||^2)+\lambda {1\over 2}||\pmb A||^2
$$
稀疏编码的每一维都可以被看作一种特征。稀疏编码的优点有:
- 计算量:稀疏性带来的最大好处就是可以极大地降低计算量.
- 可解释性:因为稀疏编码只有少数的非零元素,相当于将一个输入样本表示为少数几个相关的特征。这样我们可以更好地描述其特征,并易于理解。
- 特征选择 稀疏性带来的另外一个好处是可以实现特征的自动选择,只选择和输入样本最相关的少数特征,从而更高效地表示输入样本,降低噪声并减轻过拟合。
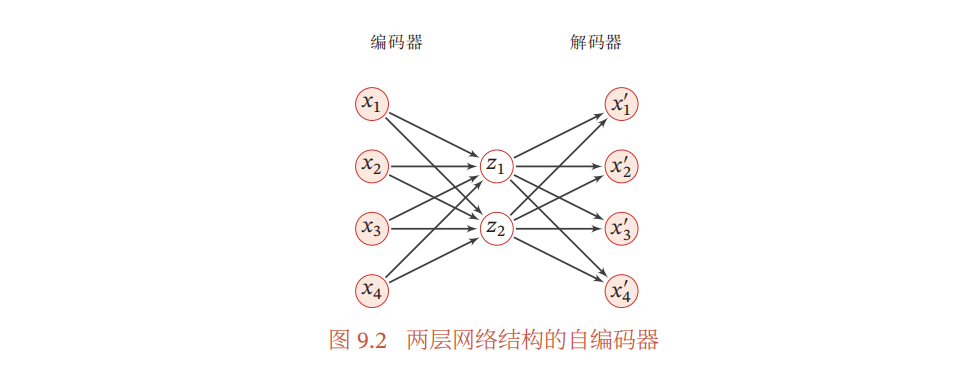
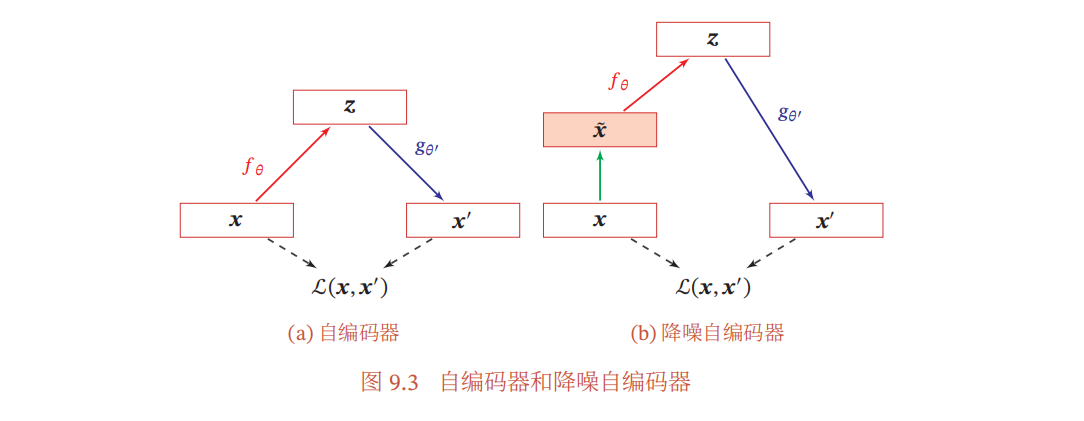
自编码器
自编码器(Auto-Encoder,AE)是通过无监督的方式来学习一组数据的有效编码(或表示),自编码器的组成部分包括编码器($\mathbb R^D \rightarrow \mathbb R^M$)和解码器($\mathbb R^M \rightarrow \mathbb R^D$)。自编码器希望实现编码-解码后恢复的结果与原数据一致,因此其目标函数是最小化重构误差
$$
\mathcal L=\sum_{n=1}^N||\pmb x^{(n)}-g(f(\pmb x^{(n)}))||^2 = \mathcal L=\sum_{n=1}^N||\pmb x^{(n)}-f\circ g(\pmb x^{(n)})||^2
$$
比较简单的是二层网络结构的自编码器,更复杂的可以设定编码的稀疏性、$g \circ f$的形式等。
稀疏自编码器
自编码器除了可以学习低维编码之外,也能够学习高维的稀疏编码,假设中间隐藏层$\pmb z$的维度大于输入样本$\pmb x$的维度$D$,并让$\pmb z$尽量稀疏,这就是稀疏自编码器。和稀疏编码一样,稀疏自编码器的优点是有很高的可解释性,并同时进行了隐式的特征选择。稀疏自编码器可以学习到数据中的一些有用的结构。
稀疏自编码器的目标函数为
$$
\mathcal L=\sum_{n=1}^N||\pmb x^{(n)}-\pmb x’^{(n)}||^2+\eta\rho(\pmb Z)+\lambda||\pmb W||^2
$$
其中$\pmb W$表示自编码器中的参数。
堆叠自编码器
对于很多数据来说,仅使用两层神经网络的自编码器还不足以获取一种好的数据表示。为了获取更好的数据表示,我们可以使用更深层的神经网络作为自编码器以提取更为抽象的底层特征,叫做堆叠自编码器。
降噪自编码器
通过在自编码器中引入噪声,可以增加编码的鲁棒性。对于一个向量$\pmb x$,首先根据一个比例$\mu$随机将$\pmb x$的一些维度的值设置为0,得到一个被损坏的向量$\widetilde{ \pmb x}$,然后将被损坏的向量$\widetilde{ \pmb x}$输入给自编码器得到编码$\pmb z$,并重构出原始的无损输入$\pmb x$。
概率密度估计
概率密度估计可以分为参数密度估计和非参数密度估计两种
非参数密度估计不假设数据服从某种分布,而是通过将样本空间划分为不同的区域,并估计每个区域的概率来近似数据的概率密度函数。
参数密度估计
参数密度估计旨在先根据先验知识假设随机变量服从某种分布,然后通过训练样本来估计分布。估计方法有最大似然估计,假设这些样本服从一个概率分布函数$p(\pmb x;\theta)$,并寻找参数最优。
$$
\log p(\mathcal D;\theta)=\sum_{n=1}^N\log p(\pmb x^{(n)};\theta)
$$
参数密度估计常用的先验分布有正态分布、多项分布等;
正态分布
假设样本$\pmb x\in \mathbb R^D$服从正态分布
$$
\mathcal N(\pmb x|\pmb \mu,\pmb \Sigma)={ 1 \over {(2\pi)^{D/2} |\pmb \Sigma|^{1/2} } }\exp(-{1\over 2} (\pmb x-\pmb \mu)^\top \pmb \Sigma^{-1} (\pmb x-\pmb \mu) )
$$
其中$\pmb \mu$和$\pmb \Sigma$分别为正态分布的均值和方差。数据集$\mathcal D=\lbrace \pmb x^{(n)} \rbrace_{n=1}^N$的对数似然函数为
$$
\log p(\mathcal D|\pmb \mu,\pmb \Sigma)=-{N\over 2}\log((2\pi)^{D} |\pmb \Sigma|)-{1\over 2} \sum_{n=1}^N (\pmb x^{(n)}-\pmb \mu)^\top \pmb \Sigma^{-1} (\pmb x^{(n)}-\pmb \mu)
$$
分别求上式关于$\pmb{\mu,\Sigma}$的偏导数并令其等于0,可得:
$$
\begin{align}
\pmb \mu^{ML} & ={1\over N}\sum_{n=1}^N \pmb x^{(n)}, \\
\pmb \Sigma^{ML} &={1\over N}\sum_{n=1}^N (\pmb x^{(n)}-\pmb \mu^{ML})(\pmb x^{(n)}-\pmb \mu^{ML})^\top.
\end{align}
$$
多项分布
假设样本服从$K$个状态的多项分布,令one-hot向量$\pmb x\in \lbrace 0,1 \rbrace ^K$来表示第$k$个状态,即$x_k=1$,其余$x_{i,i\ne k}=0$,样本$\pmb x$的概率密度函数为
$$
p(\pmb x|\pmb \mu)=\sum_{k=1}^K \mu_k^{x_k}
$$
其中$u_k$为第$k$个状态的概率,并满足$\sum_{k=1}^K \mu_k=1$。数据集$D={\pmb x^{(n)}}_{n=1}^N$的对数似然函数为
$$
\log p(\mathcal D|\pmb \mu)=\sum_{n=1}^N \sum_{k=1}^K x_k^{(n)}\log(\mu_k)
$$
多项分布的参数估计为约束优化问题,引入拉格朗日乘子$\lambda$,将原问题转换为无约束优化问题。
$$
max_{\pmb \mu,\lambda} \sum_{n=1}^N\sum_{k=1}^K x_k^{(n)} \log(\mu_k)+\lambda(\sum_{k=1}^K \mu_k-1)
$$
分别求上式关于$\mu_k,\lambda$的偏导数,并令其等于0可得
$$
\mu_k^{ML}={ {m_k} \over N}
$$
其中$m_k=\sum_{n=1}^N x_k^{(n)}$是数据集中取值为第$k$个状态的样本数量。
参数估计的短板
在实际应用中,参数密度估计一般存在以下问题:
- 模型选择问题:即如何选择数据分布的密度函数。实际数据的分布往往是非常复杂的,而不是简单的正态分布或多项分布。
- 不可观测变量问题:即我们用来训练的样本只包含部分的可观测变量,还有一些非常关键的变量是无法观测的,这导致我们很难准确估计数据的真实分布。
- 维度灾难问题:即高维数据的参数估计十分困难。随着维度的增加,估计参数所需要的样本数量指数增加.在样本不足时会出现过拟合。
非参数密度估计
非参数密度估计是不假设数据服从某种分布,通过将样本空间划分为不同的区域并估计每个区域的概率来近似数据的概率密度函数。
对于高维空间中的一个随机向量$\pmb x$,假设其服从一个未知分布$p(\pmb x)$,则$\pmb x$落入空间中的小区域$\mathcal R$的概率为
$$
P=\int_{\mathcal R}p(\pmb x)d\pmb x
$$
给定$N$个训练样本$\mathcal D=\lbrace \pmb x^{(n)}\rbrace _{n=1}^N$,落入区域$\mathcal R$的样本数量$K$服从二项分布:
$$
P_K=\begin{pmatrix}N\\K\end{pmatrix}P^K(1-p)^{1-K}
$$
其中$K/N$的期望为$\mathbb E[K/N]=P$,方差为$var(K/N)=P(1-P)N$。当$N$非常大时,我们可以近似认为$P\approx {K\over N}$。假设区域$\mathcal R$足够小,其内部的概率密度是相同的,则有
$$
P=p(\pmb x)V
$$
其中$V$为区域$\mathcal R$的体积,结合上面的两个公式可得
$$
p(\pmb x)={K \over {NV} }
$$
这个公式就是非参估计中的核心。实践中非参数密度估计通常使用两种方式,一是固定区域大小$V$,统计落入不同区域的数量,如直方图法和核方法;二是改变区域大小使得落入每个区域的样本数量为$K$,如$K$近邻。
非参数密度估计的弱点在于,其大部分方法需要保留整个数据集(直方图方法除外),而参数估计不需要,因此在存储和计算上相对弱;但是非参数估计可以在不设置参数的情况下直接进行密度估计,其操作性会比参数估计高。
直方图方法
直方图方法是一种非常直观的估计连续变量密度函数的方法,可以表示为一种柱状图。
以一维随机变量为例,首先将其取值范围分成$M$个连续的、不重叠的区间(bin),每个区间的宽度为$\triangle_m$。给定$N$个训练样本$D=\lbrace x^{(n)}\rbrace_{n=1}^N$我们统计这些样本落入每个区间的数量$K_m$,然后将它们归一化为密度函数。
$$
p_m={K_m \over {N\triangle_m} }, \ \ \ \ 1\le m\le M
$$
区间宽度$\triangle_m$的取值偏向于先验,过大会导致估计精度降低,过小会导致部分桶中没有数据,估计不精确。
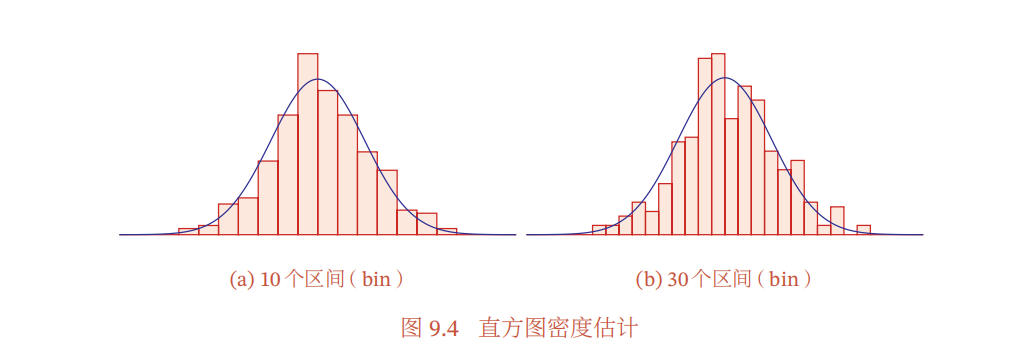
直方图方法需要的样本数量会随着维度$D$的增加而指数增长,从而导致维度灾难。
核密度估计(核方法)
核密度估计是对直方图方法的一种改进,假设$\mathcal R$是$D$维空间中的一个以点$\pmb x$为中心的“超立方体”,边长为$H$,并定义核函数来表示一个样本$\pmb z$是否落入该超立方体中。
$$
\phi({ {\pmb z-\pmb x}\over H} )=
\begin{cases}
1\ \ \ \ if|z_i-x_i|< {H\over 2},1\le i\le D \\
0\ \ \ \ else
\end{cases}
$$
点$\pmb x$的密度估计则为
$$
p(\pmb x)={K \over {NH^D} } = {1 \over {NH^D} } \sum_{n=1}^N \phi( { {\pmb x^{(n)} -\pmb x} \over H } )
$$
其中$\sum_{n=1}^N \phi( { {\pmb x^{(n)} -\pmb x} \over H } )$表示落入到$\mathcal R$的样本数量。
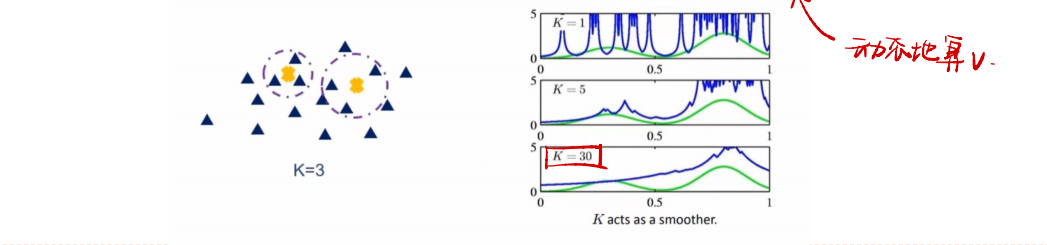
K近邻方法
核密度估计方法中的核宽度是固定的,因此同一个宽度可能对高密度的区域过大,而对低密度的区域过小.一种更灵活的方式是设置一种可变宽度的区域,并使得落入每个区域中样本数量为固定的$K$。
要估计点$\pmb x$的密度,首先找到一个以$\pmb x$为中心的球体,使得落入球体的样本数量为$K$,然后根据非参估计公式得出点$\pmb x$的密度,因为落入球体的样本也是离$\pmb x$最近的$K$个样本,因此这种方法也称为$K$近邻方法。
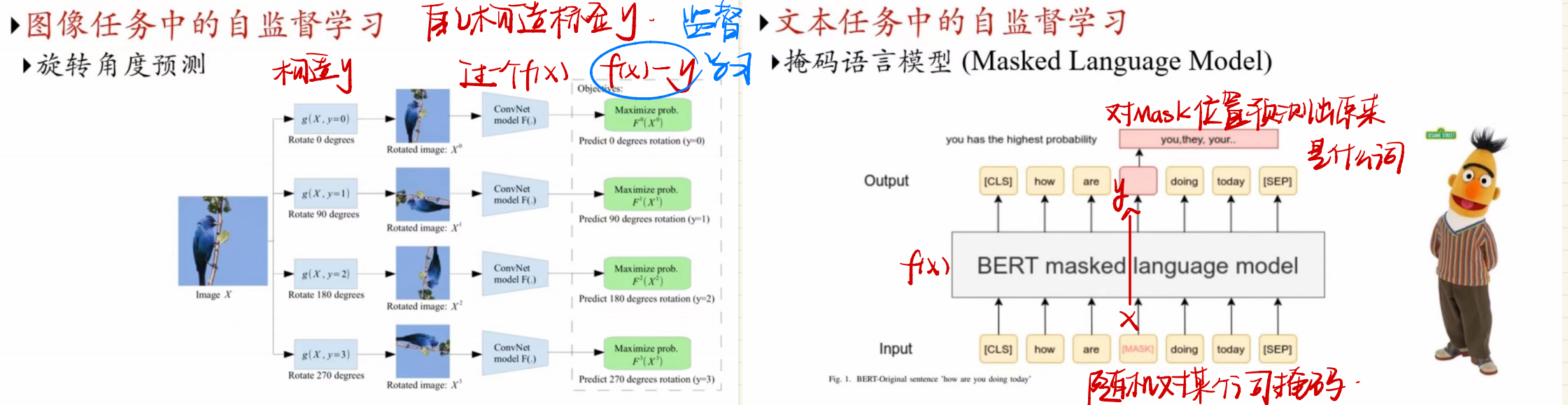
半监督的应用
半监督学习中,自训练和协同训练十分的典型,也在各个领域中有所应用,如图像任务中的旋转角度预测,文本任务中的掩码语言模型等。