CS224N课程P6:LSTM和机器翻译
本文最后更新于:几秒前
课程词汇
1 | |
课程内容
LSTM
引入:梯度消失问题的解决
需要解决梯度消失的问题,本质上是需要解决经过多个时间步之后,远处的信息如何得到保存的问题,为了解决这个问题,LSTM引入了一个分开的存储来保存信息。

LSTM的结构
LSTM的结构如下:在每一步$t$中设置一个隐状态(hidden state)$\pmb h^{(t)}$和一个细胞状态(cell state)$\pmb c^{(t)}$:
- 两个都是$n$维向量
- 细胞状态存储的是长程信息
- LSTM可以从细胞状态中读取、修改或写入信息,决定信息的操作的是三个对应的门,门的开关通过现有上下文来进行计算。
LSTM的两个状态的计算公式如下:
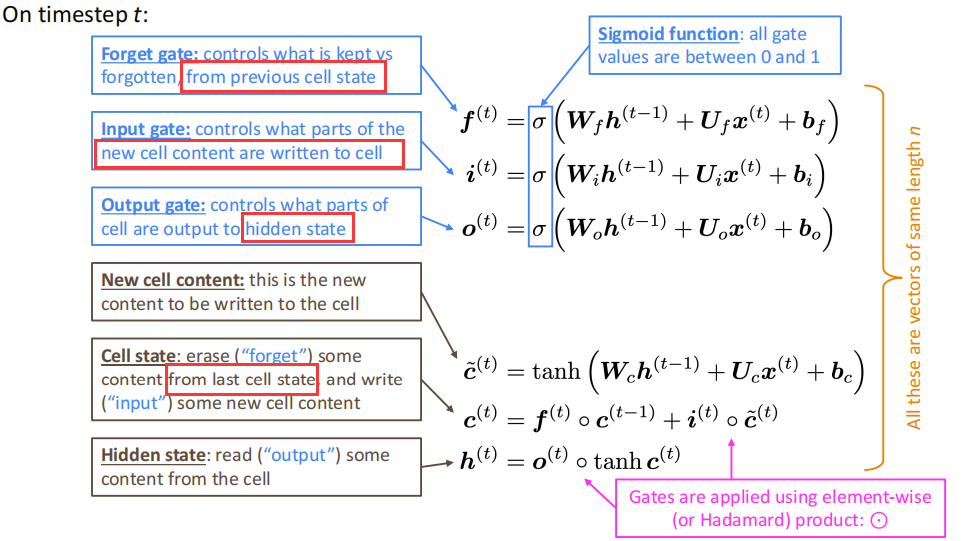
需要注意的是每个门对应的信息。其中遗忘门对应于遗忘之前cell state里的信息,输入门对应于写入cell state,输出门对应于将cell state的信息输出到hidden state。这里用到了Hadamard乘积。
LSTM的可视化解释为:
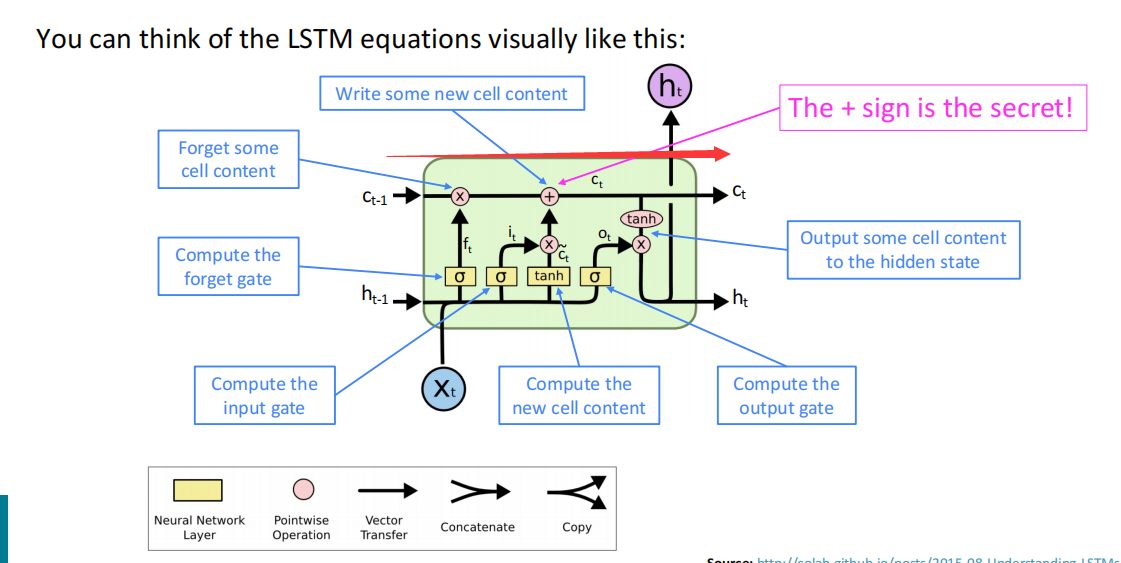
这张图给出了LSTM的运行机理,首先神经元是沿着从$c_{t-1}$到$c_t$的主干道传送长程信息,然后在主干道上,先通过遗忘门判断保存$c_{t-1}$的哪些信息,然后过输入门,并计算新的cell信息,给到cell state,最后过输出门,判断是否将$c_i$的部分信息输出到$h_t$,从而实现整体运行。
LSTM相对于Vanilla RNN,其在保留长程信息上表现十分优秀,甚至来说,将遗忘门置1并将输入门置0,则cell state的信息会无限的保存下去,而RNN中一直使用的$\pmb W_h$会导致其容易出现梯度问题。实践下来,LSTM可以保存近百步的信息,而Vanilla RNN大概只能保存7步左右。
其他解决梯度消失的结构
梯度消失的问题在各个深层神经网络中都有出现,其中以时序网络更为明显,为了解决梯度消失的问题,一些神经网络引入了直连边,允许梯度在边上流动,如十分重要的ResNet:

更多的,在状态之间引入稠密连接,每层都与其他未来的层进行相连,就是DenseNet的主要思路。以及像LSTM一样设置一个主干道连接,这是HighwayNet的基本思路。总而言之,梯度消失是在网络中十分普遍的问题,如今的人们也在致力于完美解决这个问题。
LSTM的优化结构
BiLSTM
如果将LSTM中的隐状态看作单词的一种表示(如词嵌入),则LSTM也可以理解成对句子的上下文表示进行学习,不过LSTM只有一个方向(左边)的context作为特征来学习,故引入了双向LSTM网络(BiLSTM),分别从左边和右边构建一个LSTM网络,最后将两个方向的结果简单连接起来。
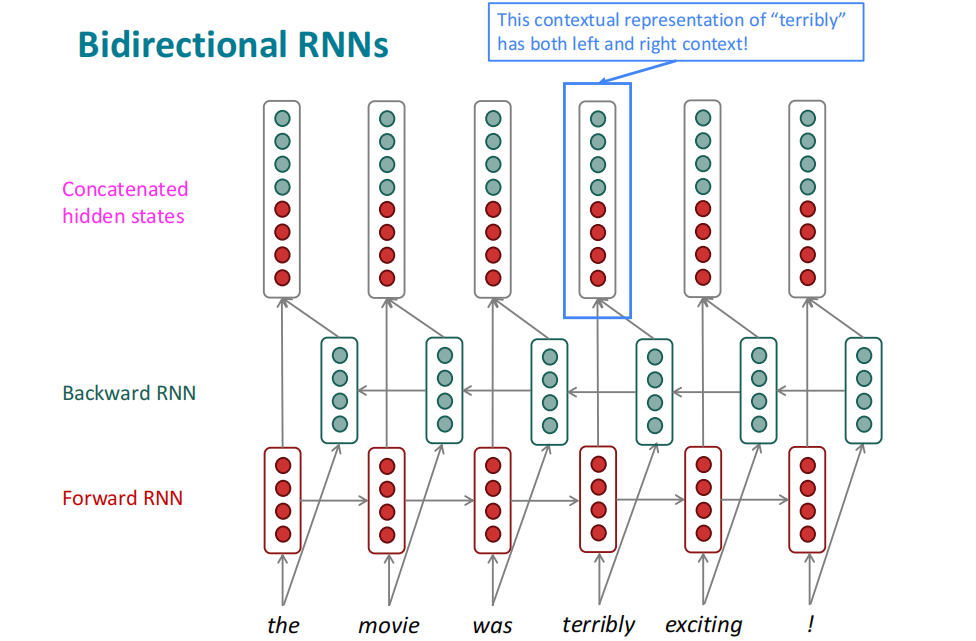
在第$t$个时间步:
$$
\begin{align}
{\rm Forward\ RNN }\ \ \overrightarrow {\pmb h}^{\ (t)} & = {\rm RNN_ {FM} }\left( \overrightarrow {\pmb h}^{\ (t-1)}, \pmb x^{(t)} \right) \\
{\rm Backward\ RNN }\ \overleftarrow {\pmb h}^{(t)} & = {\rm RNN_ {BM} }\left( \overleftarrow {\pmb h}^{\ (t+1)}, \pmb x^{(t)} \right) \\
{\rm Hidden\ State}\ {\pmb h}^{(t)} & =[\overrightarrow {\pmb h}^{\ (t)} ; \overleftarrow {\pmb h}^{(t)} ]
\end{align}
$$
BiLSTM在图示上可以简化为:
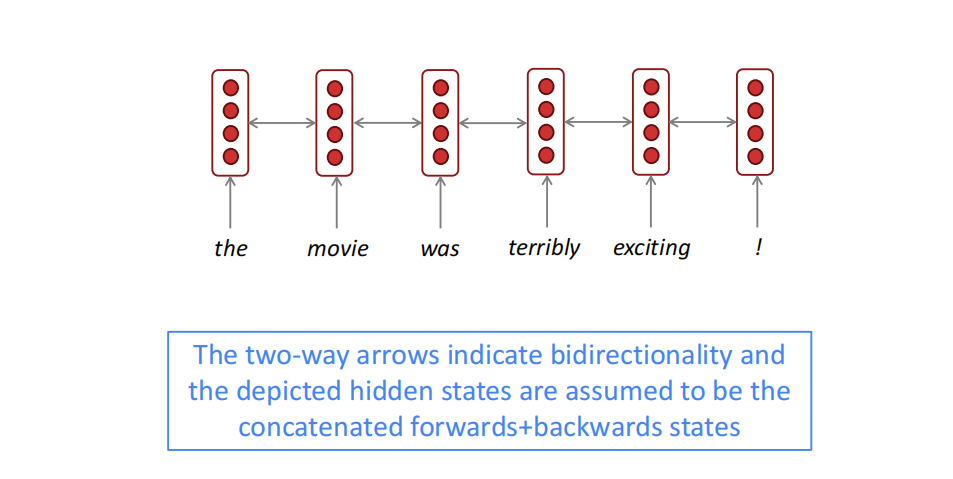
BiLSTM适用于需要处理整体输入序列,双方向的任务(如编码),而不适用于像语言模型这样单方向的语言任务,BiLSTM在现有的语言领域中使用十分广泛,如现在十分火热的BERT架构,其中的“B”就是BiLSTM的缩写。
Multi-layer RNN
上文所讲述的RNN都是基于一个维度的加深,即从左到右深度较深,timestep许多但在另一个维度上很窄,因此引入了多层RNN的架构,在层数上加深。这能够使RNN计算出更为复杂,更高层的表示信息,Muiti-layer RNNs又称为stacked RNNs。
目前来说,表现较好的RNN模型通常都为多层结构(不像卷积网络或前馈网络那么深层),进入到更深层(超过4层)则通常需要使用skip-connections或dense-connections来防止梯度问题,基于Transformer的RNN网络则在深度上会更高(一般在12或24层)。

机器翻译
机器翻译任务(Machine Translation,MT)是将基于一种语言的句子(Source language)翻译到另一种语言(Target language),其中心思想为从语料数据中学习一个概率模型,下文均基于法译英展开。
机器翻译的任务可以表示为:
$$
{\rm argmax}_y P(y|x)
$$
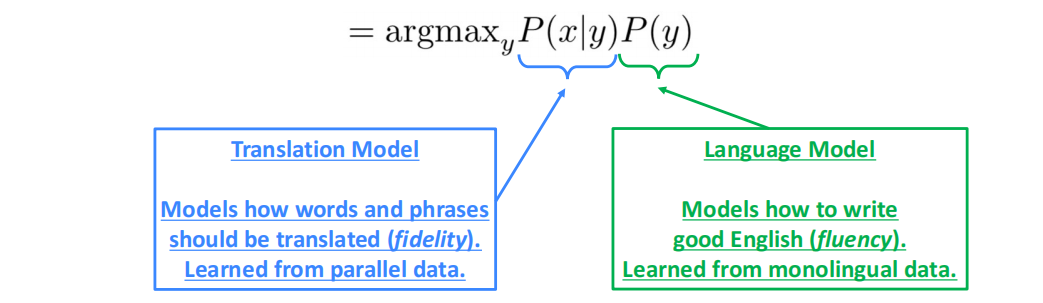
使用贝叶斯公式可以将任务拆分为两个部分:
$$
{\rm argmax}_y P(y|x) = {\rm argmax}_yP(x|y)P(y)
$$
统计机器翻译(SMT,1990s—2010s)
统计机器翻译在当时是一个十分巨大的研究领域,其最优的系统都十分复杂,有数以百计的重要细节需要考量。而且系统中包含了许多分别设计的子部件,因此需要十分庞大的特征工程,额外的资源和人力。
神经网络机器翻译(NMT,2010s至今)
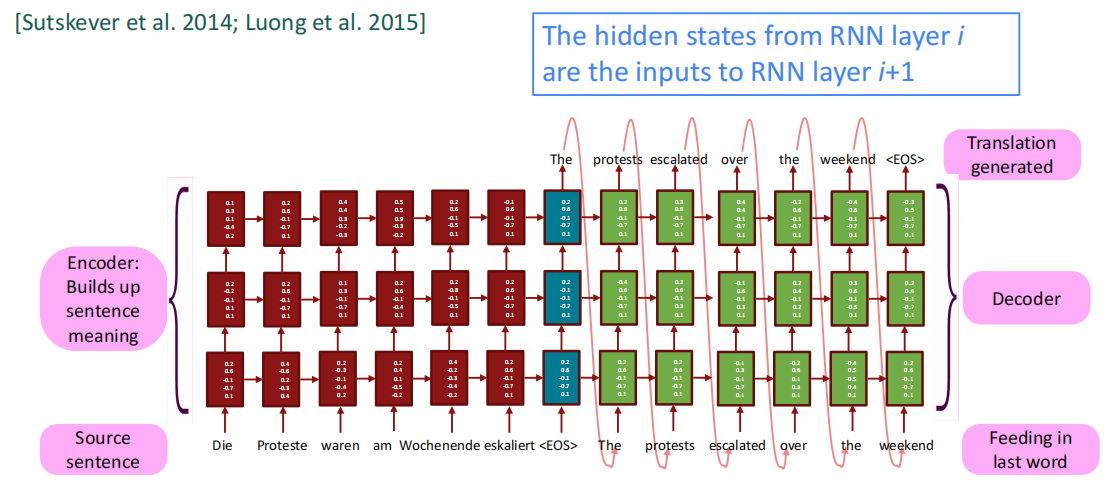
神经网络机器翻译是通过单个的端到端网络来实现机器翻译的方法,其中神经网络的架构被称为Sequence-to-sequence模型(seq2seq),其中包括两个RNN,一个为编码器(Encoder),一个为解码器(Decoder)。
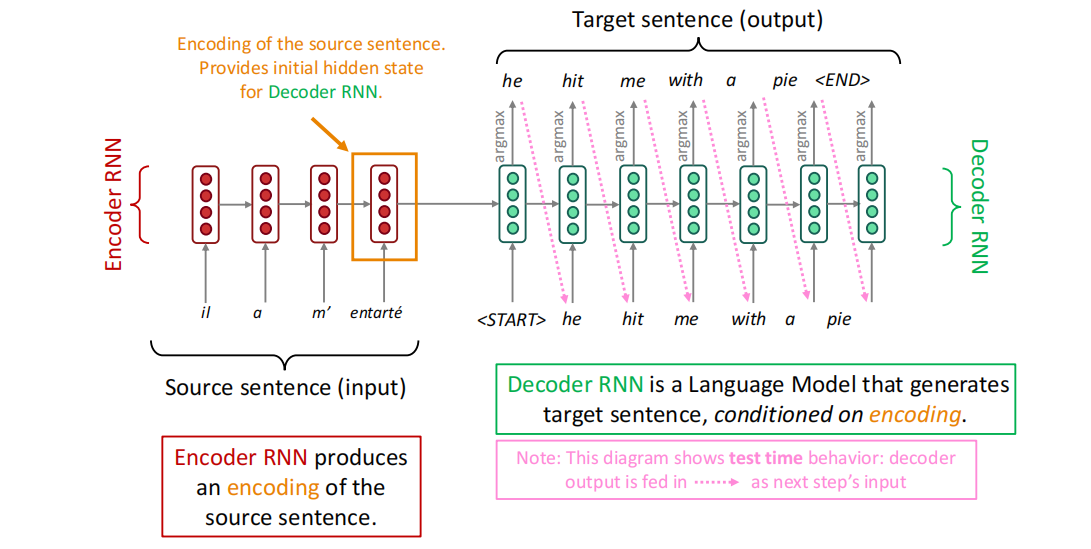
如图所示,左边的红色部分为Encoder部分,负责将源句子编码表示,其中Encoder的结果作为Decoder的初始隐状态,Decoder负责基于Encoder的条件,作为语言模型生成目标语句。这体现了条件网络的概念,即将之前的Encoder的结果作为一种条件指导Decoder的训练。目前来说,条件网络的条件可以有以下几种:
- 作为初始隐状态
- 作为下个网络的输入
Seq2seq

Seq2seq在nlp的许多应用场景中都有所使用,如:
- Summarization(long text $\rightarrow$ short text)
- Dialogue(previous utterances $\rightarrow$ next utterance)
- Parsing(input text $\rightarrow$ output parse as sequence)
- Code generation(natural language$\rightarrow$ Python code)
Seq2seq在这里的模型是一个典型的条件语言模型的例子:
- 语言模型:Decoder每个隐状态预测一次目标语句中的下一个单词
- 条件:Decoder的预测由源语句经Encoder编码后条件约束。
NMT直接计算了概率分布$P(y|x)$以给出机器翻译结果,具体来说是不断计算$P(y|x)$在贝叶斯分解后的每个部分,其训练主要是需要一个相对大的并行语料,但目前也有无监督NMT和数据增强等一些新兴的工作。
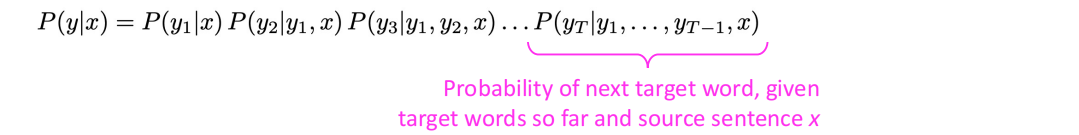
NMT的训练和多层NMT
NMT的前向训练就如上文中的图示一样,先训练Encoder获取表示,后Decoder训练语言模型,其中每个隐状态都需要计算真实语句和预测语句中对应位置的负对数损失,最后做加和;反向传播的过程中,Seq2seq通常被看作一个整体。Encoder的输出也有将之前的隐状态做一次平均的情况存在,但大多数就是从前到后做训练。
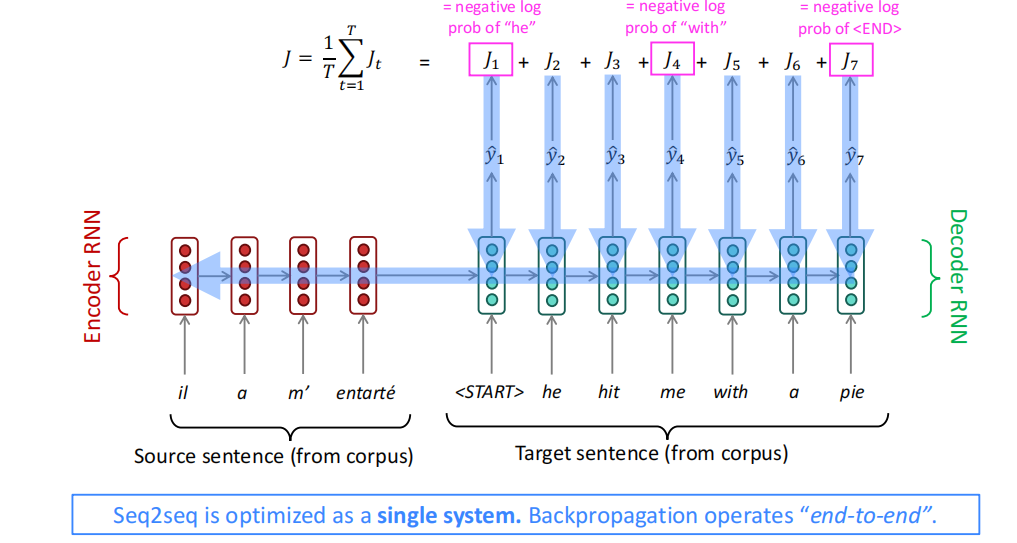
将NMT加深层次,多层NMT就可以更有效地捕捉语句信息。
机器翻译的评估
机器翻译的评估通常采用BLEU(Bilingual Evaluation Understudy)。BLEU通过比较机器翻译和人类手工翻译并计算其中的相似度分数,分数的计算基于两个部分:
- n-gram precision(Usually for 1,2,3 and 4-grams)
- 对系统翻译过短的惩罚项
具体的细节要到A4作业看,BLEU作为评估指标上是很有效的,但其确实也有一些缺点,因为好的翻译的评价是很多元化的,因此可能会出现翻译在我们人类看来是很出色但是BLEU分数很低(因为用词不一样)的情况出现。故BLEU也只是覆盖到了大部分的情况。
机器翻译的分析
对比SMT,NMT有以下优点:
- 更好的翻译表现
- 更加流利的译后语言
- 对context和phrase similarities利用得更完备
- 一个单一的神经网络可以端到端优化
- 没有子组件需要特别进行优化
- 人力和特征工程资源要求降低
- 没有特征工程
- 对所有语言方法一致
但NMT也有以下弱点需要注意:
- NMT的可解释性更差
- 难以debug
- NMT的可控性更差
- 例如:无法轻松指定翻译规则或准则
- 安全性考量
最后,NMT近些年的优秀表现,使得绝大部分的企业都选择了NMT作为机器翻译的首选。

课后问题
Q:门的工作原理
所有的门控都需要学习,都是在模型中学习出来的,实际上效果是可以的
Q:为什么LSTM中的加和操作(Add)是十分重要的?
因为加和相对于乘积,其梯度的不断下降的程度会弱一些,这也间接防止了梯度消失的快速出现。而且加和操作可以大致实现信息的整合,需要加哪些信息,需要忘记哪些信息。
Q:在多层RNN中,低级语义和高级语义分别指什么?示例?
低级特征是在句子中更为基础的特征,如单词的词性等等,而高级特征更关注于高维的表示,如句子的结构、句子的情绪价值等等。