CS224N课程P2:词向量与神经网络分类器
本文最后更新于:几秒前
课程词汇
1 | |
课程内容
分布式词向量:Word2Vec
数据设置
词袋模型实际上是不关心词序或位置的模型,无论上下文词离中心词远或近,其概率估计结果是相同的。word2vec为实现对上下文的高概率,其需要将相似的词汇放到词汇空间中十分接近的位置。
学习优化:梯度下降
$$
\theta_{new} = \theta_{old}-\alpha\triangledown_{\theta} J(\theta)
$$
因为$J(\theta)$在大规模的中心词存在的情况下使用梯度下降,效率很低,因此采用随机梯度下降(SGD)代替全数据梯度下降,提高性能。随机梯度下降每次更新采用一个或一批数据(单词)进行更新。
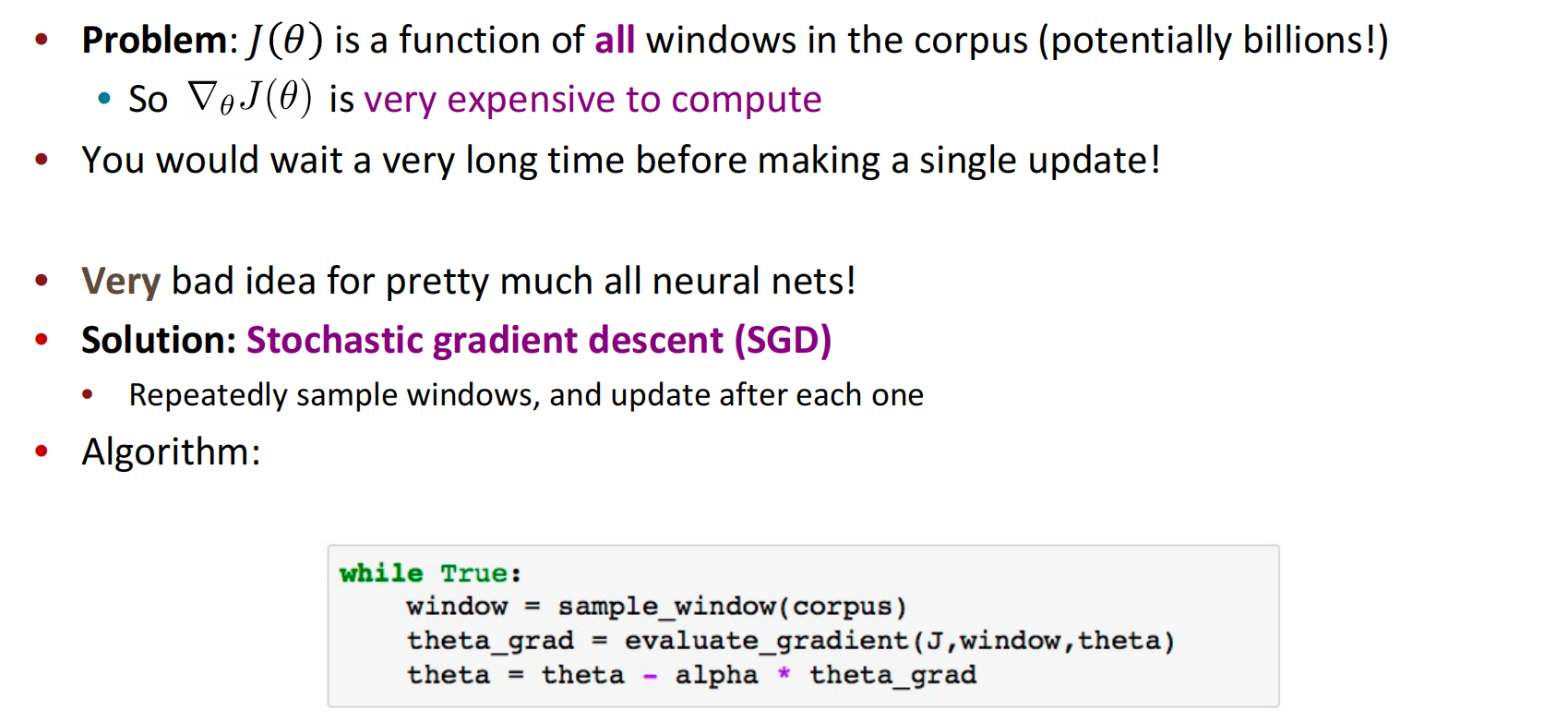
单词用向量表示使用行向量。
在随机梯度下降的过程中,由于每次更新时只用到$2m+1(m为窗口大小)$的单词,如果有负采样则加上$2km(k为负采样次数)$的单词数量,这与所有单词总数相比十分的小,因此计算出来的梯度$\triangledown_\theta J_t(\theta)$十分的稀疏。
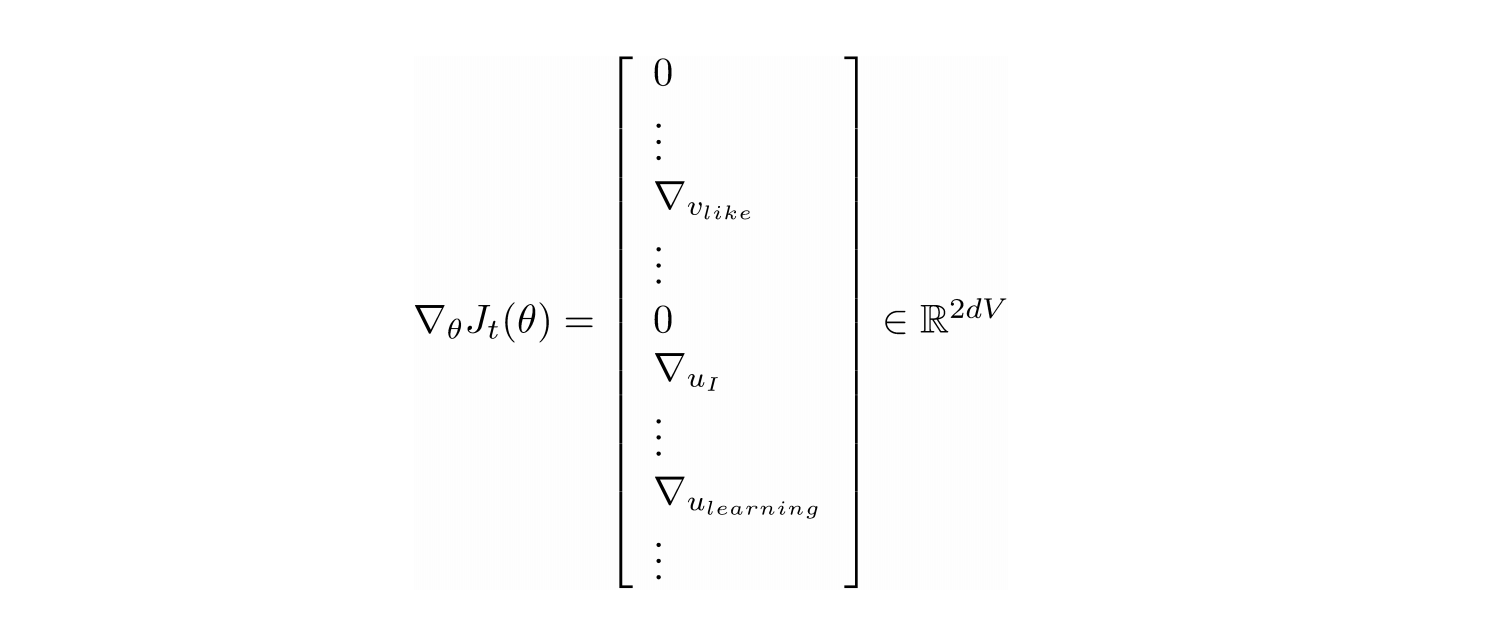
我们有时只需要更新实际上出现过的单词,大部分单词不需要更新,解决方法是需要稀疏矩阵更新操作,只更新全嵌入矩阵U和V的某些行;或者你需要为词向量保留一个哈希值。
Skip-gram+负采样
使用两个向量的原因是方便优化计算,只有一个向量确实会帮助提升效率,但当中心词和上下文词出现相同词类型的时候,这种$x x^\top$的关系会影响到优化,造成混乱。
两种模型:

在skip-gram模型中,对于朴素的softmax函数的概率,其分母的计算要求十分昂贵,需要遍历一遍所有的词汇,因此引入负采样。
负采样的思想在于将分母去掉,以中心词和外部词的点积表示其和外部的相似度,一般来说,取样后产生的点积应该越小越好,以防止对上下文词的影响。我们将中心词和上下文词的点积概率最大化,而把中心词和外部词的点积概率最小化。这个思想和softmax函数的思路是一致的,增大分子而缩小分母。
$$
J_{neg-sample}(\pmb u_o,\pmb v_c,U) = -\log \sigma(\pmb u_o^\top\pmb v_c) - \sum_{k\in \lbrace K sampled\ indices \rbrace} \log \sigma(-\pmb u_k^\top \pmb v_c)
$$
其中$\sigma(·)$是$logistic$函数,将数据压缩到0-1,加上负号的原因是最小化损失函数(习惯问题)。对于采样的选择,论文中采用了$P(w)={ U(w)^{3\over 4} \over Z}$作为对k个外部单词采样的概率分布,其中$U(w)$是单词的原数量分布,加上${3\over 4}$将频用词和鲜用词的相差概率压缩,但不至于到均匀分布的程度,然后除以$Z$概率还原到$0-1$。
计数共现矩阵
共现矩阵
将单词表现为共现矩阵的一行或一列,这样可以保存单词之间的共现关系,直接训练相邻的单词。
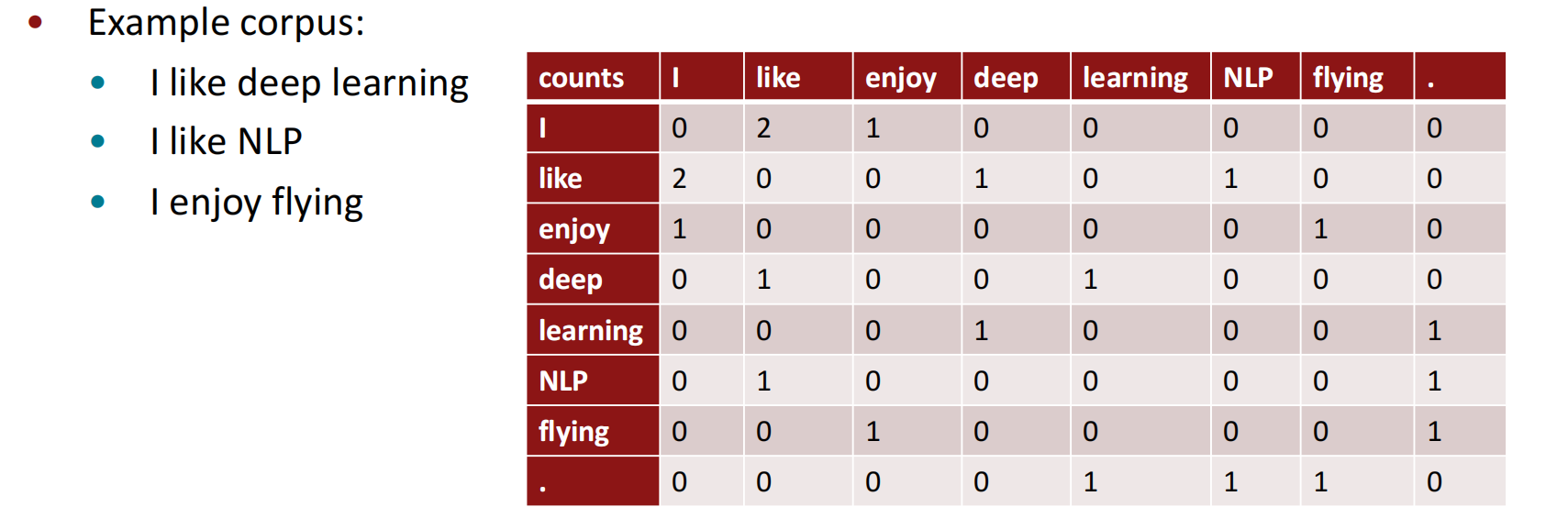
共现矩阵的实现分为两种,一是确定窗口的单词共现矩阵,二是使用段落、单元等自有单位的文档-单词矩阵。
维度降低
我们可以在固定的少量维度中存储有关单词分布和其他单词上下文的大部分重要信息,从而实现低维向量的表示。具体的这里需要用到奇异值分解的基本知识:
奇异值分解(SVD)
一个$n \times n$的矩阵$A$可以特征分解为$n$个特征值$\lambda_1\le \lambda_2 \le … \le \lambda_n$,以及这$n$个特征值所对应的特征向量$w_1,w_2,…,w_n$,那么矩阵$A$就可以用特征式来表示:
$$
A = W \Sigma W^{-1}
$$
其中$W$是这$n$个特征向量所张成的$n \times n$维矩阵,$\Sigma$是$n$个特征值为主对角线的$n \times n$维矩阵。一般我们会把W的这n个特征向量标准化,此时$W$的$n$个特征向量为标准正交基,满足$W^{\top}W=I$,即$W^\top = W^{-1}$,这样特征分解表达式可以写成:
$$
A = W\Sigma W^\top
$$
如果$A$不是方阵,则需要引入奇异值分解,假设$A$是$m\times n$的矩阵,分解时分解成下列形式:
$$
A = U \Sigma V^\top
$$
其中$U$是$m\times m$的矩阵;$\Sigma$是一个$m\times n$的矩阵,除主对角线上的元素外其余元素均为0,主对角线上的每个元素都称为奇异值;$V$是一个$n\times n$的矩阵。$U$和$V$都满足标准正交的性质。
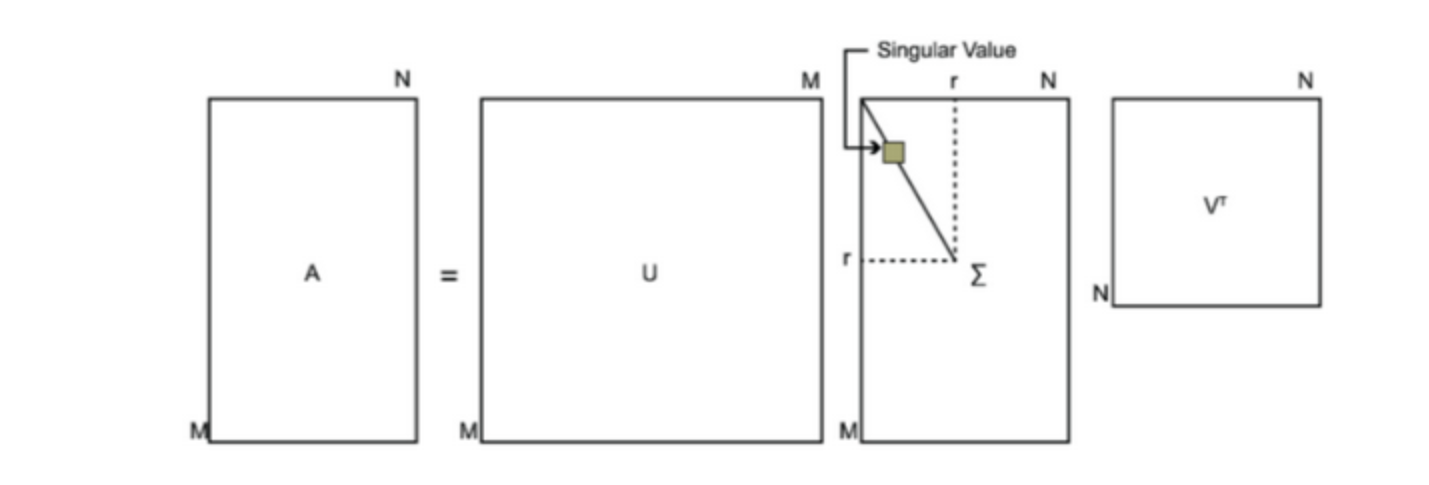
对三个部分的求解,请参考原文,在这里不再赘述。
奇异值在降维的应用
将奇异值分解应用到降维部分,可以用几个低维矩阵最大程度还原原始矩阵。
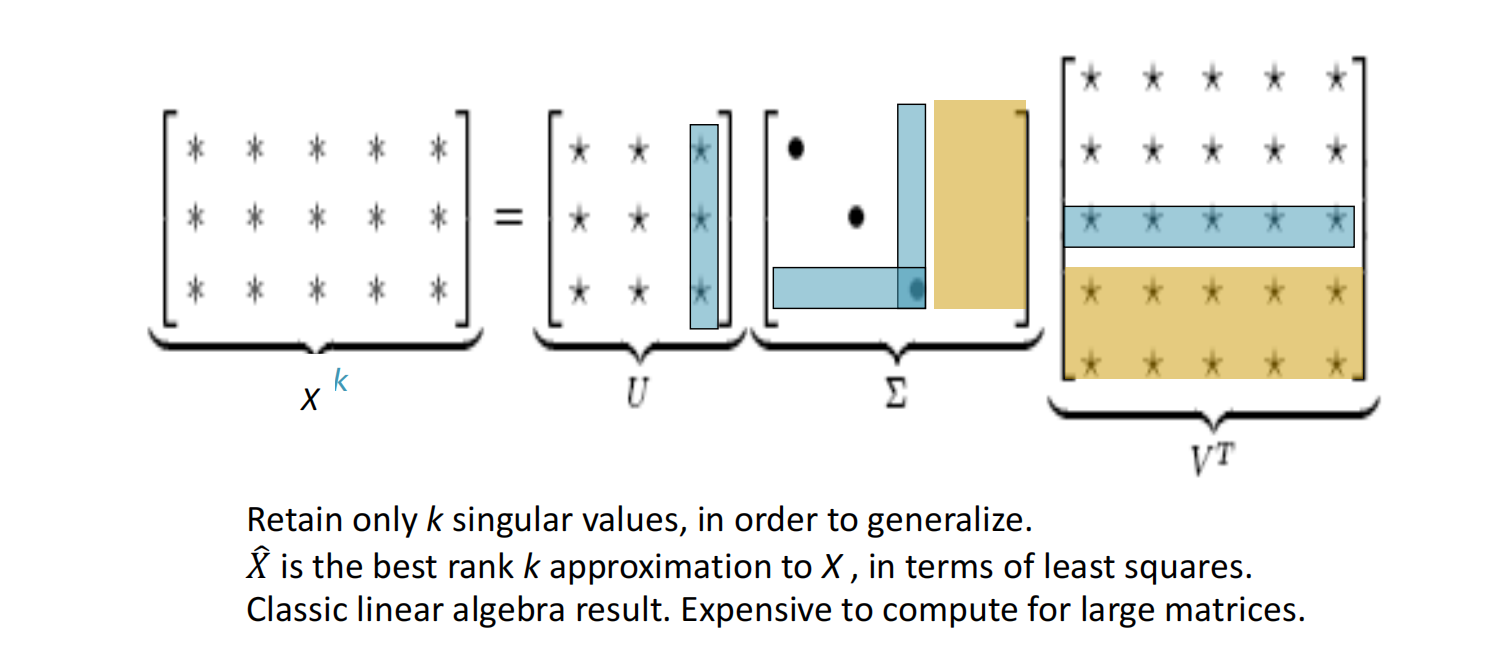
其中,黄框中的内容是在主对角线中没有用到的,因此被压缩掉;为了减少尺度同时尽量保存有效信息,可保留对角矩阵的最大的$k$个值,其余置零,并将酉矩阵的相应的行列保留,其余置零,如蓝框内的部分。再然后我们使用$U$的行来作为字典中所有词的词向量。
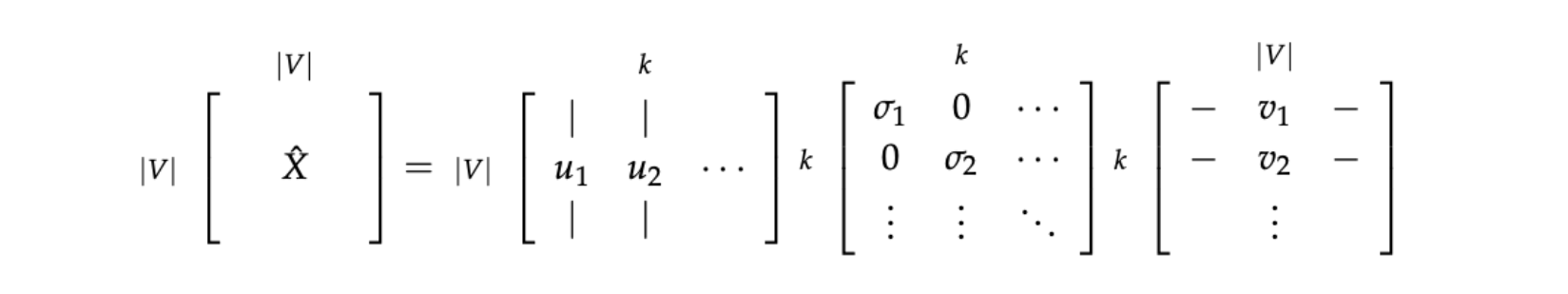
单纯使用SVD的效果并不太好,因此也有一些优化改进。

GloVe
GloVe模型解决了如何在词向量空间中捕捉共现概率比例作为线性意义的成分,共现矩阵中概率的比例可以编码词的意义成分(如:男人到女人、动物到植物等)。这也为之后能够对这些线性意义成分进行计算提供基础。
GloVe的核心在于使用词向量表达共现概率比值,而任意一个这样的比值需要三个词i、j和k的词向量。令i为单词ice,j为单词steam,论文中的一组比较可以体现这种共现性:
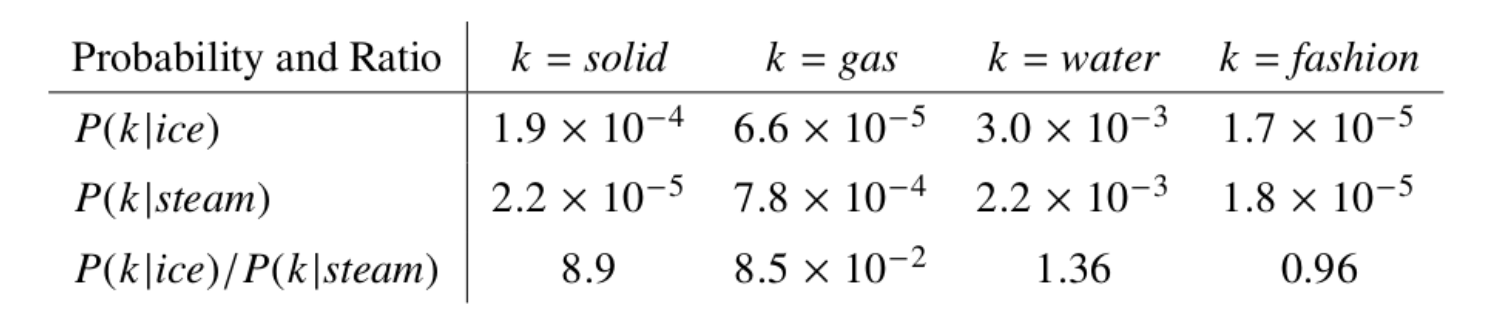
例如对于solid固态,虽然$P(solid|ice)$与$P(solid|steam)$本身很小,不能透露有效的信息,但是它们的比值${ {P(solid|ice)} \over {P(solid|steam)} }$却较大,因为solid更常用来描述ice的状态而不是steam的状态,所以在ice的上下文中出现几率较大,对于gas则恰恰相反,而对于water这种描述ice与steam均可或者fashion这种与两者都没什么联系的单词,则比值接近于1。
定义一些符号:对于矩阵$X$,$X_{ij}$代表单词$j$出现在单词$i$上下文中的次数,则$X_i=\sum_k X_{ik}$代表所有出现在单词$i$的上下文中的单词次数。我们用$P_{ij}=P(j|i)=X_{ij}/X_i$表示单词$j$出现在单词$i$上下文中的概率。
基于对上面概率的观察,假设模型的函数有以下形式:
$$
F(w_i,w_j,\tilde{w_k})
$$
其中$\tilde w$代表背景词,如上例中的solid,gas等;$w_i,w_j$代表需要比较的两个词汇,如上例中的ice,steam。$F$的可选形式过多,因此论文作者在这里做出了限定:首先我们希望的是$F$能有效的在单词向量空间内表示概率比值,由于向量空间是线性空间,一个自然的假设是$F$是关于向量$w_i,w_j$的差的形式:
$$
F(w_i-w_j,\tilde w_k) = { {P_{ik} } \over {P_{jk} } }
$$
等式右边为标量形式,左边如何操作能将矢量转化为标量形式呢?一个自然的选择是矢量的点乘形式:
$$
F((w_i-w_j)^\top\tilde w_k) = { {P_{ik} } \over {P_{jk} } }
$$
又因为对称性,即对于单词-单词 共现矩阵,将向量划分为center word还是context word的选择是不重要的,即我们在交换$w\leftrightarrow \tilde w$和$X \leftrightarrow X^\top$的时候该式仍然成立。这里分两步进行,首先要求$F((w_i-w_j)^\top\tilde w_k) = { {F(w_i^\top \tilde w_k)} \over {F(w_j^\top \tilde w_k)} }$,该方程解为$F=exp$;同时与$F((w_i-w_j)^\top\tilde w_k) = { {P_{ik} } \over {P_{jk} } }$相比较有$F(w_i^\top \tilde w_k)=P_{ik}={ {X_{ik} } \over {X_i} }$,故有
$$
w_i^\top \tilde w_k=\log (P_{ik})=\log(P(i|k)) = \log(X_{ik}) - \log (X_i)
$$
这里$\log(X_i)$破坏了对称性,但这一项并不依赖于$k$,因此可以将其融合进关于$w_i$的偏置项$b_i$;同时为了平衡对称性(这里不太懂,可能纯粹是形式对称),再加入$\tilde w_k$的偏置项$\tilde b_k$,得到GloVe的损失函数如下,其中$f(·)$用于滤掉过高频出现的词语,如虚词副词等等。
$$
Loss:J=\sum_{i,j=1}^Vf(X_{ij})(w_i^\top w_j+b_i+b_j-\log X_{ij})^2
$$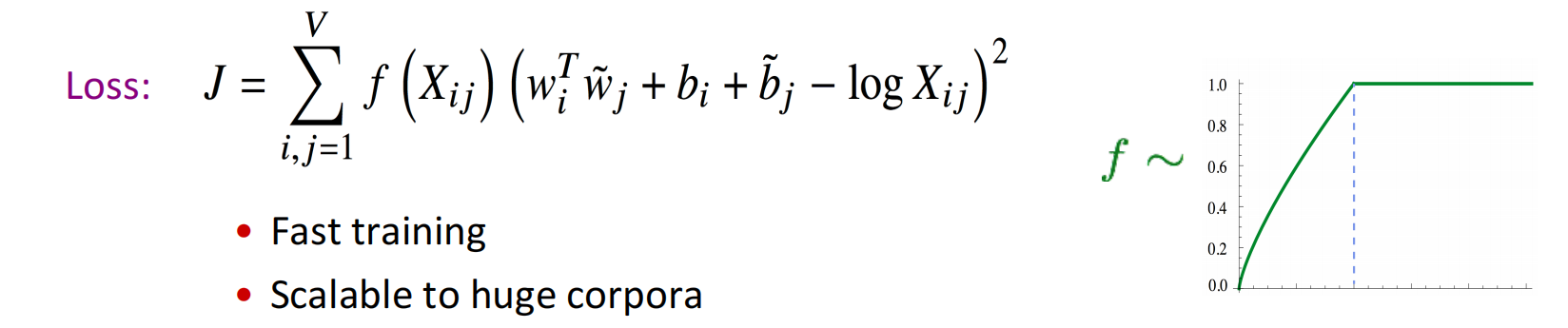
评估过程
包括内在评估和外在评估。内在评估通过设置与词向量任务相关的子任务来测试词向量的效果,外在评估直接设置真实项目来予以实验。

内在评估
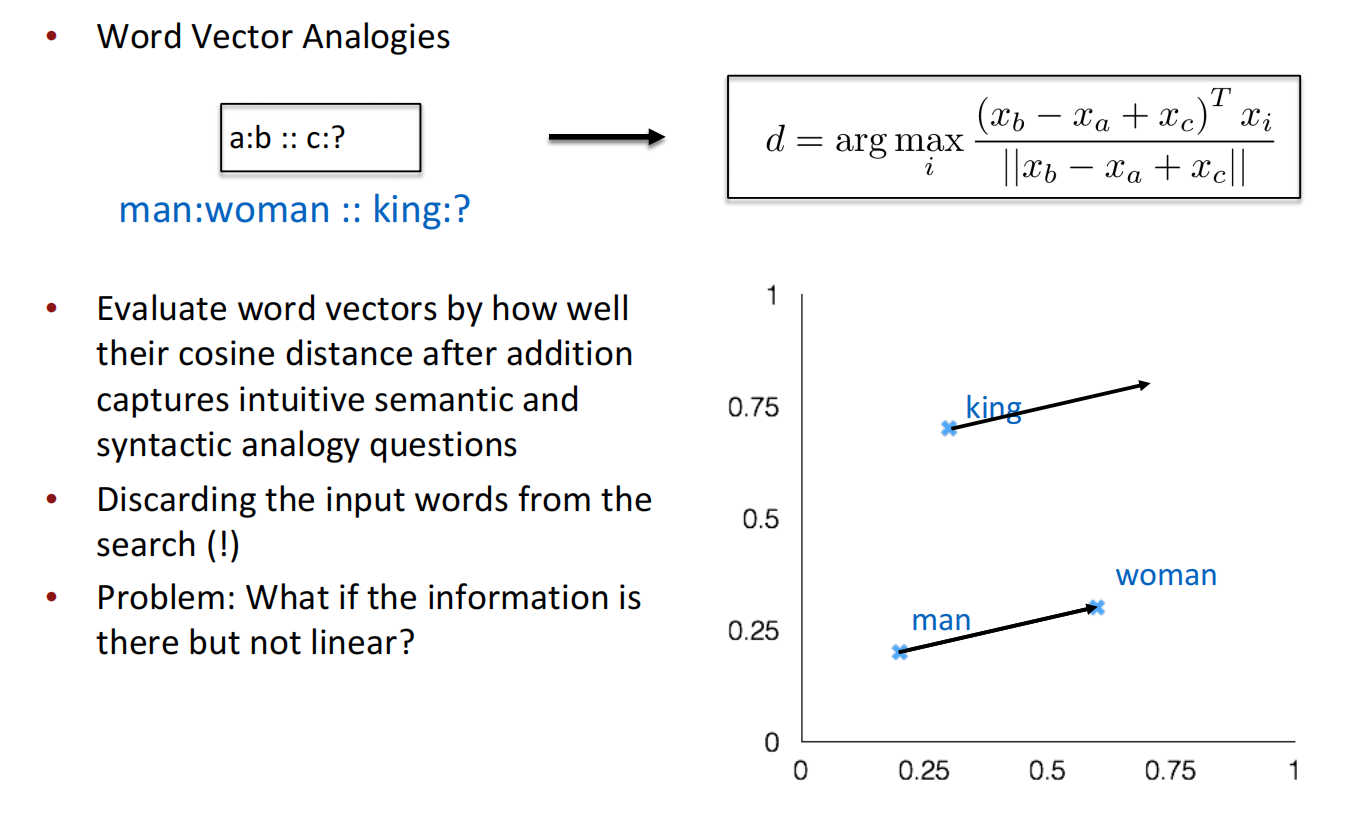
内在评估中,现有的评估大多针对于向量本身的评估,以及单词间相似性的评估。对于向量计算本身的评估,可以通过评估其向量计算后的单词类比来评估,即man->woman : king-> ?这种类比过程能否通过向量计算成功类比。
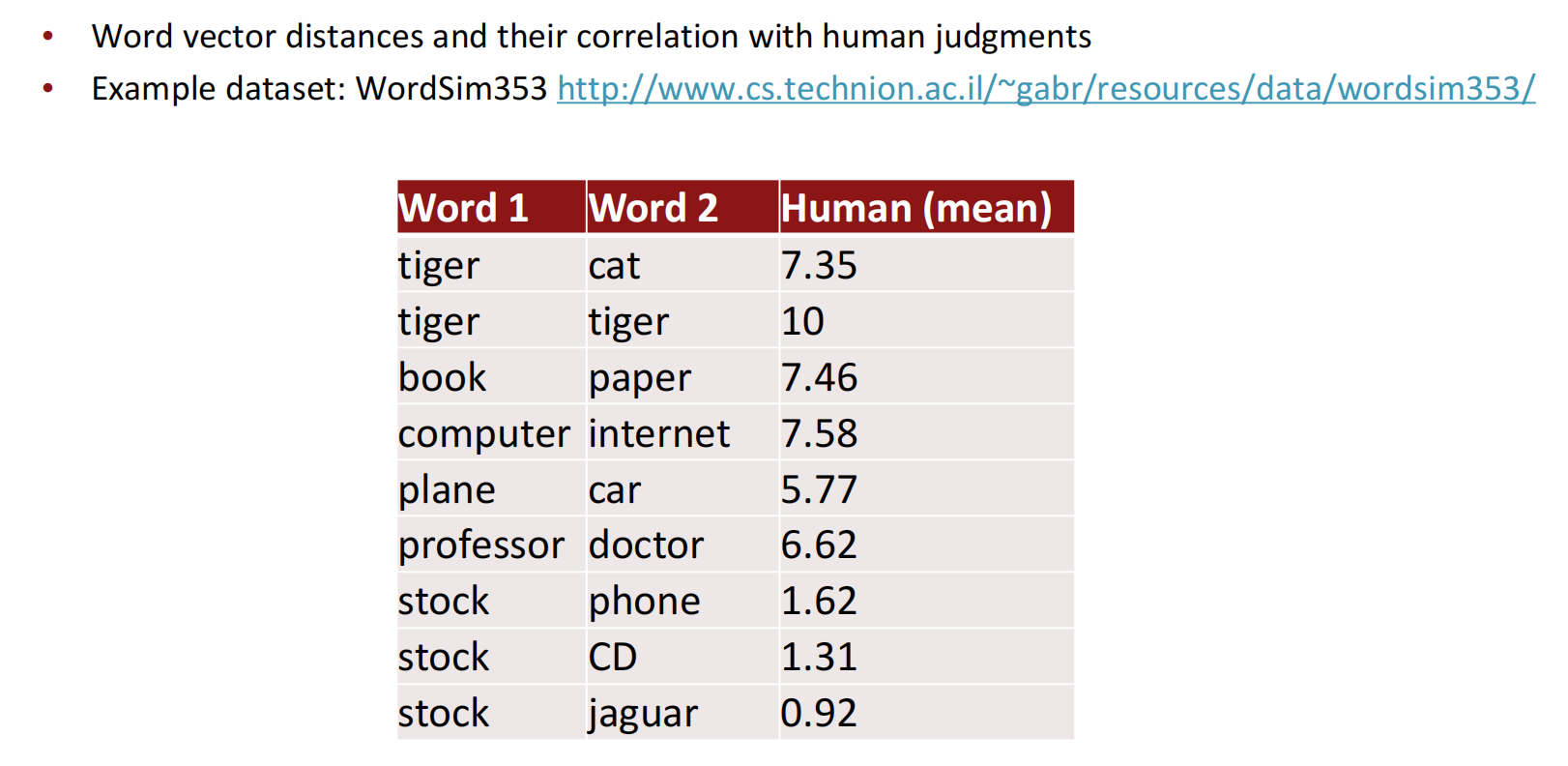
对于单词意义相似性的评估,现有人类已经有了相似单词定量化的数据集,因此可以通过比较词向量距离及其与人类判断的相关性来实现内在评估。
外在评估
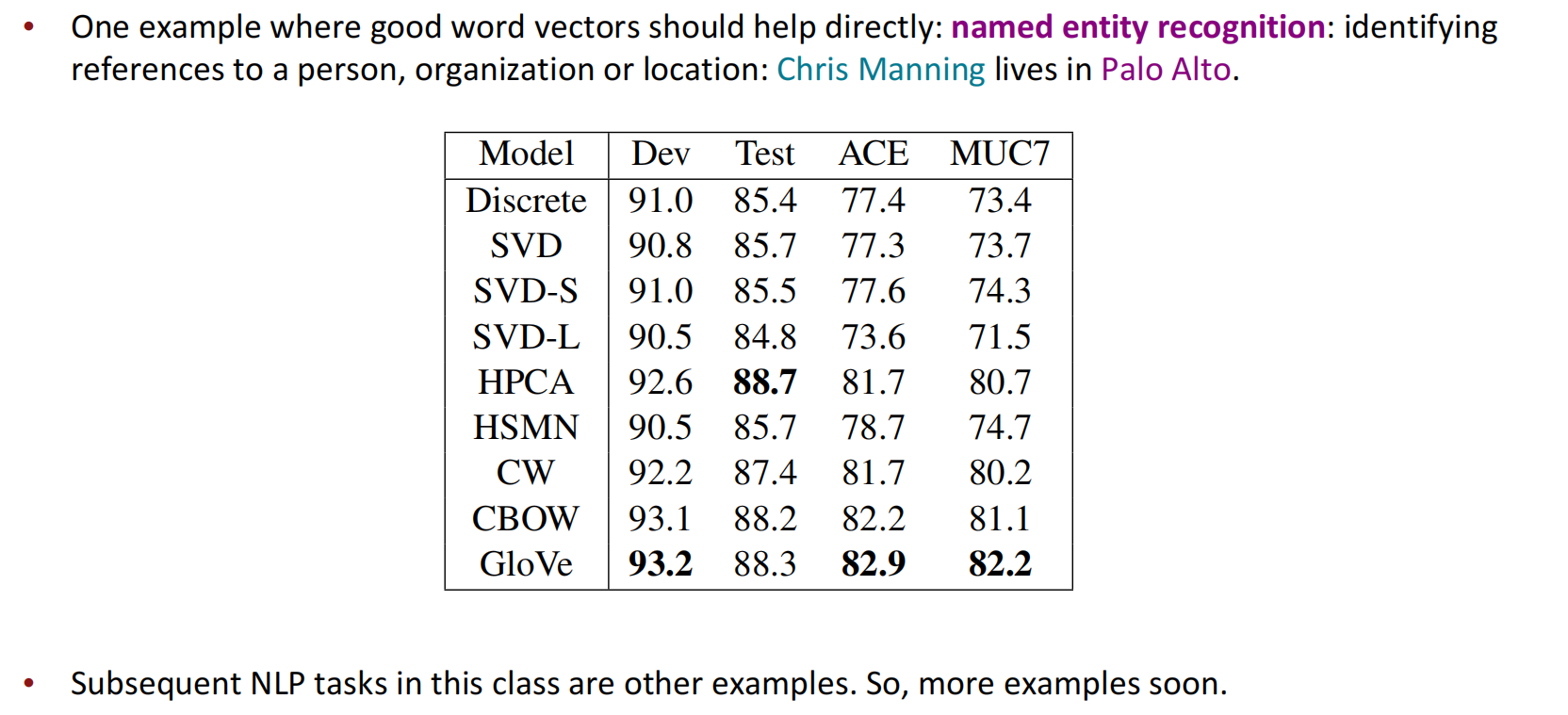
外在评估中,可以通过比较不同的词向量来看到词向量带来的收益。如下图中提到的命名实体识别的真实任务。
课后问题
Q:为什么Skip-gram在数据统计的使用效率上比较低?
A:因为Skip-gram每次只操作一个中心词,需要对每个中心词都做一次处理,而共现矩阵这样的操作可以直接操作一整个矩阵,其操作效率会高上许多。
Q:可否再讲解一下GloVe的目标函数和双线性对数模型?
A:(返回看上面)每个词都有一个偏置项很重要,方便调整。
Q:如何处理词汇的多义性?(这个问题是补充讲解)
A:比较疯狂的做法是对词语的每个语义作一个词向量,这可以通过意义聚类来尝试;但一是这种做法复杂度较高,在词向量生成时要加上一层词义分析;二是词汇中多个语义之间可能难以区分,无法达到固定标准。
对每个语义做一个词向量,这个尝试在早期就有人做,主要思想是对各个词义的词向量作加权组合,而且令人惊讶的是通过稀疏自编码的思想,可以将组合后的词向量再分离回去(前提是语义十分常见)。
